最近开始看数据结构,该系列笔记简单记录总结下所学的知识,更详细的推荐博主StrayedKing的数据结构系列,笔记部分也摘抄了博主总结的比较好的内容。
一些基本概念和术语
数据是对客观事物的符号表示,在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。
数据元素是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。有时,一个数据元素可由若干个数据项组成,数据项是数据的不可分割的最小单位。
数据对象是性质相同的数据元素的集合,是数据的一个子集。
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。根据数据元素之间关系的不同特性,通常由下列4类基本结果:
(1)集合
(2)线性结构 结构中的数据元素之间存在一个对一个的关系;
(3)树形结构 结构中的数据元素之间存在一个对多个的关系;
(4)图形结构或网状结构 结构中的数据元素之间存在多个对多个的关系。
数据元素之间的关系在计算机中由两种不同的表示方法:顺序映像和非顺序映像,据此得到两种不同的存储结构:顺序存储结构和链式存储结构。顺序映像和特点是借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系;非顺序映像的特点是借助表示元素存储地址的指针表示数据元素之间的逻辑关系。
算法是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示一个或多个操作;一个算法还具有5个重要特性:
(1)有穷性 一个算法必须总是(对任何合法的输入值)在执行有穷步之后结束,且每一步都可在有穷时间内完成。
(2)确定性 算法中每一条指令必须有确切的含义,读者理解时不会产生二义性。在任何条件下,算法只有唯一的一条执行路径,即对相同的输入只能得到相同的输出。
(3)可行性 一个算法是能行的,即算法中描述的操作都是可以通过已经实现的基本运算执行有限次来实现的。
(4)输入 一个算法有零个或多个的输入 ,这些输入取自于某个特定的对象的集合。
(5)输出 一个算法有一个或多个的输出,这些输出是同输入有着某些特定关系的量。
线性表——顺序存储结构
线性表的顺序的顺序表示指的是用一组地址连续的存储单元依次存储线性表的数据元素。
假设线性表的每个元素需占用l个存储单元,并一所占的第一个单元的存储地址作为数据元素的存储位置。则线性表中第i+1个数据原色的存储位置LOC(ai+1)和第i个数据元素的存储位置LOC(ai)之间满足下列关系:
LOC(ai+1) = LOC(ai) + l
一般来说,线性表的第i个数据元素ai的存储位置为:
LOC(ai) = LOC(a1) + (i-1) * l
LOC(a1)指线性表中的第一个数据元素a1的存储位置,通常称做线性表的起始位置或基地址。
只要确定了存储线性表的起始位置,线性表中任一数据元素都可随机存取,所以线性表的顺序存储结构是一种随机存取的存储结构。
若表长为n,为删除或插入元素的时间复杂度为O(n)。
单链表强调元素在逻辑上紧密相邻,所以首先想到用数组存储。但是普通数组有着无法克服的容量限制,在不知道输入有多少的情况下,很难确定出一个合适的容量。对此,一个较好的解决方案就是使用动态数组。首先用malloc申请一块拥有指定初始容量的内存,这块内存用作存储单链表元素,当录入的内容不断增加,以至于超出了初始容量时,就用calloc扩展内存容量,这样就做到了既不浪费内存,又可以让单链表容量随输入的增加而自适应大小。
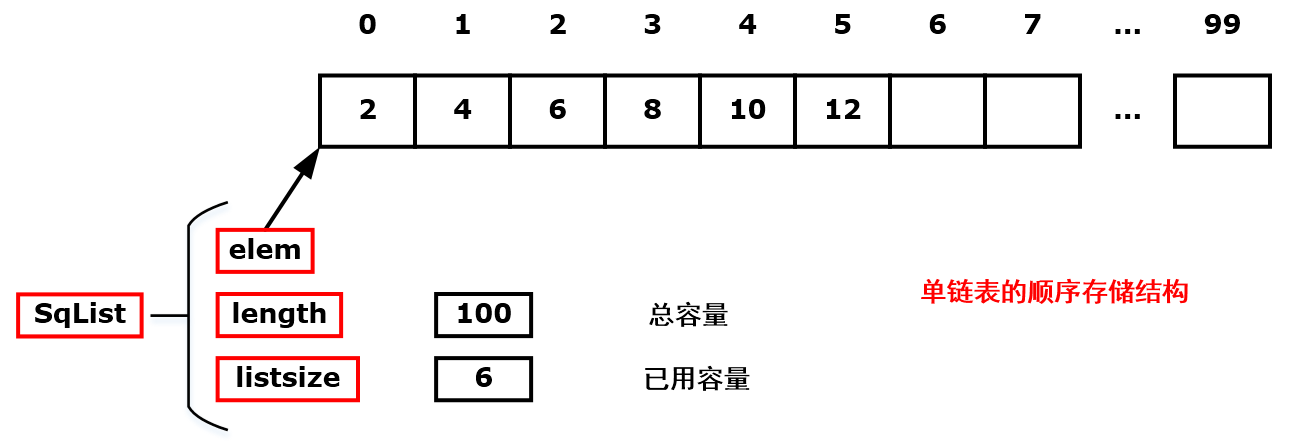
单链表顺序存储结构如下图:
单链表强调元素在逻辑上紧密相邻,所以首先想到用数组存储。但是普通数组有着无法克服的容量限制,在不知道输入有多少的情况下,很难确定出一个合适的容量。对此,一个较好的解决方案就是使用动态数组。首先用malloc申请一块拥有指定初始容量的内存,这块内存用作存储单链表元素,当录入的内容不断增加,以至于超出了初始容量时,就用calloc扩展内存容量,这样就做到了既不浪费内存,又可以让单链表容量随输入的增加而自适应大小。
单链表顺序存储结构如下图:
线性表——链式存储结构
链式存储删除与插入更方便,不用来回移动大量元素。但与此对应的是存取指定位置元素时将变得费劲,因为顺序存储结构中,通过数组下标就可以获取第i个元素,但是在链式存储中,必须由头指针或尾指针(如果有的话)开始遍历整个链表直至寻找到需要的元素。在元素的查找效率方面,此两种存储结构无明显差异。

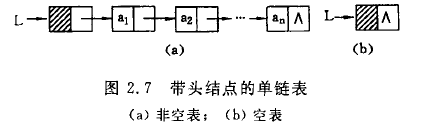
最后一个结点指针通常为NULL。如果将最后一个结点的指针指向开头,那么这个链表就成了循环单链表。
有头结点的单链表:有时,在单链表的第一个节点之前附设一个节点,称之为头结点。头结点指针指向的结点数据域为空,指针域存储指向第一个结点的指针(即第一个元素结点的存储位置)。头结点的存在仅仅是作为标记单链表的开始,有头结点的单链表在操作时更加方便,不用专门为头结点的增删情况写额外代码,这一点可以在实际应用中加以体会。
单链表链式存储也用到了动态分配内存。值得注意的是,由于头结点的指针本身就是个结构指针,所以在初始化、创建、销毁等需要改变头结点指针的地方,则要注意函数形参为二级指针,即指向头指针的指针。新手很容易犯的错误是该用二级指针的地方使用了一级指针,这样做的后果就是明明函数内分配了所需内存,但是外面却访问不到,也可能明明函数内销毁掉的内存,外面还可以访问到。这样不仅会引起内存访问差错,甚至会引起程序崩溃,所以,这一点很值得引起重视。
线性表——静态链表
静态链表用数组存放数据,存取方式模拟了系统的malloc分配和free回收机制。
书中的描述如下:
//-----线性表的静态单链表存储结构-----// #define MAXSIZE 1000 typedef struct{ ElemType data; int cur; }componet,SlineList[MAXSIZE];
数组的一个分量表示一个结点,同时用游标(指示器cur)代替指针指示结点在数组中的相对位置,数组的第零分量可看成头结点,其指针域表示链表的第一个结点。这种存储结构仍需要预先分配一个较大的空间,但在作线性表的插入和删除操作时不需要移动元素,仅需修改指针,故仍具有链式存储结构的主要优点。
假设SWieSLinkList型变量,则S[0].cur指示第一个结点在数组中的位置,若设i = s[0].cur,则S[i].data存储线性表的第一个数据元素,且S[i].cur指示第二个结点在数组中的位置。一般情况,若第i个分量表示链表的第k个结点,则S[i].cur指示第k+1个结点的位置。因此在静态链表中实现线性表的操作和动态链表相似,以整形游标i代替动态指针p,i = S[i].cur的操作实为指针后移(类似与p = p->next)。
在《数据结构》原书中,对静态链表的表述是有些复杂的,这里对其进行了适当简化,但中心思想不变。
静态链表是特殊的顺序表,它从数组(一块连续的内存)中孕育,但行为却类似于单链表,它反映出了链式单链表在系统中实现的本质。静态链表依靠自身的一个游标来实现单链表中结构指针的作用,所以,在存取元素时,一方面要考虑静态链表内部的游标变动,另一方面也要考虑整个空间中剩余内存的游标变化,因为整个内存块同样也是通过游标来链接的。
静态链表存储结构及存取机制如下图:
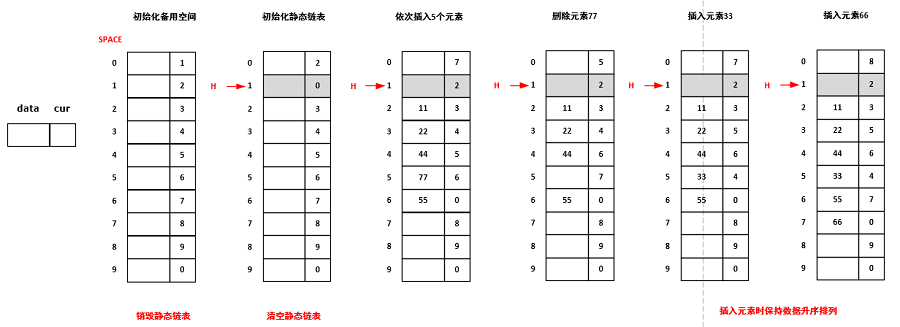
灵活应用typedef来创造新类型,比如在静态空间SPACE定义时,将整个结构数组看做了一个新的类型Component。
关于静态链表的一些操作书中的我看不太明白,参考了博客《数据结构——静态链表》
几个注意点如下:
初始化时别忘了将最后一个指针域指向0;
分配空闲结点时总是取头结点之后的第一个空闲结点,如果空闲链表非空,调整头结点的值;
回收结点时总是将回收的结点放在头结点之后。
#include <stdio.h> #define N 100 typedef struct{ char data; int cur; }SList; void init_sl(SList slist[]){//初始化成空闲静态链表, int i; for(i=0;i<N-1;i++) { slist[i].cur=i+1; } slist[N-1].cur=0;//最后一个指针域指向0 } int malloc_sl(SList slist[]){//分配空闲结点 int i=slist[0].cur;//总是取头结点之后的第一个空闲结点做分配,同时空闲链表非空,头结点做调整 if (i) { slist[0].cur=slist[i].cur;//空闲链表头结点调整指针域 } return i;//返回申请到的空闲结点的数组下标 } void free_sl(SList slist[],int k){//将k结点回收 slist[k].cur=slist[0].cur;//总是将回收的结点放在头结点之后 slist[0].cur=k; }
线性链表——循环链表
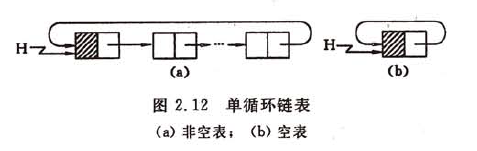
循环链表就是头尾相连,表中最后一个结点的指针域指向头结点,整个链表形成一个环,由此,从表中任一结点出发均可找到表中其他结点。
循环链表的操作和线性链表基本一致,差别仅在于算法中的循环条件不是p或p->next是否为空,而是它们是否等于头指针。
线性链表——双向链表
单链表的单向性是的从某个结点出发只能顺指针往后寻找其他结点,如果要寻找结点的直接前趋,需从表头指针出发。因此,提出了双向链表,一个结点中有两个指针域,其一指向直接后继,另一指向直接前趋。
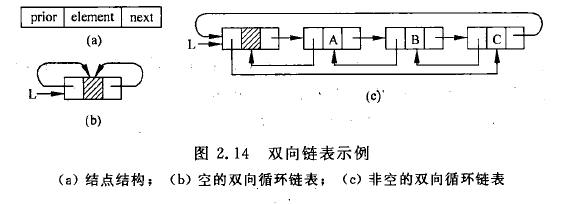
若d为指向表中某一结点的指针,则有d->next->prior = d->prior->next = d