一、多线程的起源
对于软件工程师,整个代码执行的过程中主要关注CPU、内存和I/O这三个方面;在计算机快速发展的阶段,主要是这三个方面在快速发展;但这三方面一直存在这一个严重的矛盾,即运行速度;CPU的运行速度是是最快的,内存次之,IO是最慢的;举个例子来说,CPU是天上一天,内存就是地上一年。若内存是天上一天,IO就是地上十年;
根据木桶理论,限制程序运行速度的是IO。每次在执行IO操作时,CPU都会被闲置;为了最高效的利用CPU的计算资源,平衡这三者的速度差异。计算机体系结构、操作系统和编译程序都做了平衡,主要体现在以下三点:
1、为了均衡CPU和内存的速度差异,给CPU配置专门的缓存;
2、操作系统增加了线程和进程。以分时复用CPU来平衡CPU与IO的时间差;
3、编译程序优化指令执行次序,确保缓存可以被合理的使用;
二、多线程BUG源头
1、缓存导致的可见性问题
1)在单核CPU的时代,所有的线程都是操作同一个CPU的缓存,所以对于所有的线程来说,CPU的缓存都是共享且可见的;但在多核CPU的时代,每个CPU都会有自己的缓存,不同的线程被分配到不同的CPU。就会导致多个线程在不同的CPU缓存中操作同一个变量时,该变量在每一个缓存中都是只对操作该CPU的线程可见,对其它CPU对应的线程是不可见的。不能保证该变量的强一致性;
代码示例:
public class Test1 {
private static Long count = 0L;
private static void sum10k(){
int initNum = 0;
while (initNum++ < 10000){
count += 1;
}
}
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
Test1.sum10k();
});
Thread t2 = new Thread(() -> {
Test1.sum10k();
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(count);
}
}
该代码最终的结果并不是和直觉得到的20000的结果,而是在10000~20000之间的一个随机值。原因就是,t1线程和t2线程对count这个变量的操作是在两个不同的CPU缓存上,相当于在操作两个count变量,各自累加各自的同时互相累加,就会导致两个同时操作时,前一个被后一个覆盖掉,最终只进行一次累加,导致结果不会是20000.
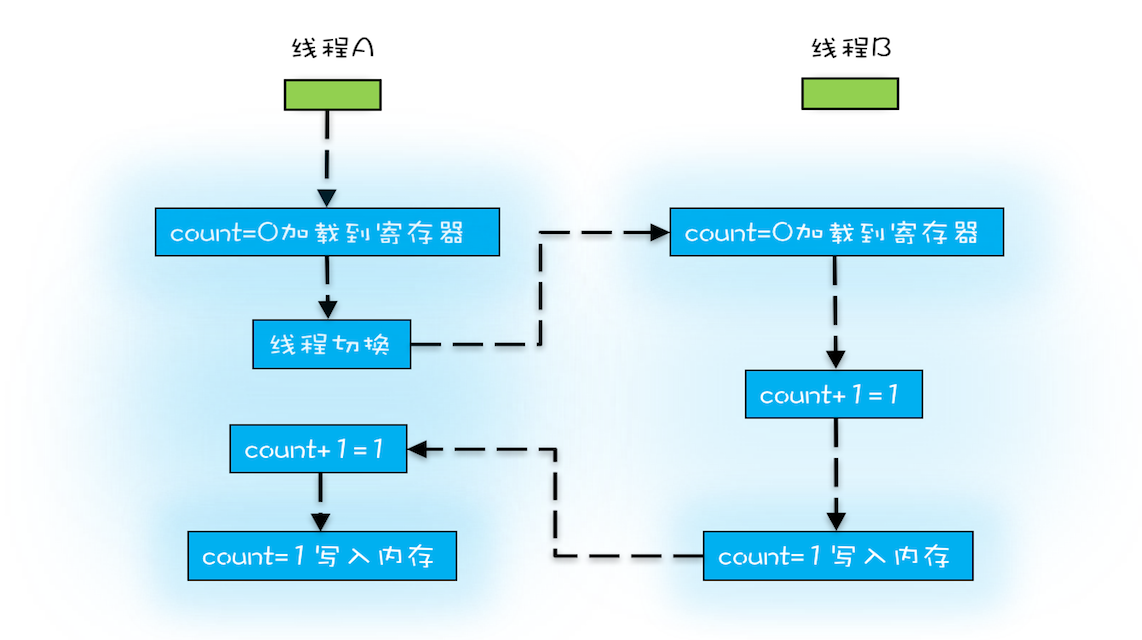
2、线程切换带来的原子性问题
CPU的计算操作是以CPU的指令为最小原子单位操作的,而不是以软件工程师的每行代码为一个原子来执行的;
count+=1;这行代码可以拆分成三个CPU指令:
1)将count的初始值从内存中加载到CPU的寄存器中;
2)在CPU的寄存器中执行+1操作;
3)将+1后的结果写入到内存中(由于CPU缓存的存在,结果写入到的地方应该是CPU的缓存,而不是直接写入到内存中);
由于CPU执行指令是使用时间片(分时复用)来操作的。例如上面的count+=1这行代码,线程A执行时,可能只执行到了第一条指令(将数据加载到CPU1寄存器中)。此时时间片结束,CPU2现在开始操作线程B。线程B执行完完整的三行指令后,现在假设count值结果变成了1,而线程A加载到CPU1寄存器的值仍然是0,在执行完后结果仍是count结果变成了1。执行了两次,理想结果应该是2,但由于线程切换导致线程B的结果覆盖掉了线程A,导致最终结果仍然是1;
3、编译优化带来的有序性问题
在CPU的优化过程中,添加了一种指令重排序的规则。即指令在执行的过程中,指令并不是完全按照代码书写顺序的顺序进行执行的。例如定义int a=0; int b=1。CPU在执行的过程中有可能会先执行int b=1,再执行int a=0,这样执行并不影响最终的结果。但有些逻辑就会产生bug,例如再创建单例的使用双重检查的代码逻辑时逻辑:
public class Singleton(){
private static Singleton instance;
public Singleton getSingleton(){
if(instance == null){
Synchronzed(Singleton.class){
if(instance == null){
instance = new Sinleton();
}
}
}
return instance;
}
}
在new对象的操作过程中,按照正常流程,代码会被分成三条指令被CPU执行:
1)给即将new出来的对象分配一块内存M;
2)在内存M上初始化Singleton对象;
3)将初始完对象的内存M的地址赋值给instance变量;
由于编译优化指令重排序,导致将第二步和第三步调换了位置;分析如下:
线程A和线程B都来执行该段单例代码。在判断现在对象不存在的前提下,由于锁的存在。这两个线程只能有一个线程可以获取到锁。假设B线程获取到锁,线程B再次判断对象为空,然后执行创建对象(new 对象),执行到位置调换后的第二步(将内存M的地址赋值给instance变量)。此时发成了线程切换,开始执行线程A,线程A在最外层判断instance是否为空,发现不为空,就会直接返回一个没有初始化Sinleton对象的但已有内存地址的对象。产生错误情况;