Django基础之模型(models)层
Django测试环境搭建:
拷贝manage.py中的行代码放到tests.py文件中导入模块
import django,django.setup()
import os
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "one_search.settings")
import django
django.setup()
# 你就可以在下面测试django任何的py文件
如果你想查看orm语句内部真正的sql语句有2种方法:
1.如果是queryset对象,就可以.query查看该queryset对象的内部sql语句
2.在settings.py文件中配置
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level': 'DEBUG',
},
}}
一 ORM简介

- 我们在使用Django框架开发web应用的过程中,不可避免地会涉及到数据的管理操作(如增、删、改、查),而一旦谈到数据的管理操作,就需要用到数据库管理软件,例如mysql、oracle、Microsoft SQL Server等。
- 如果应用程序需要操作数据(比如将用户注册信息永久存放起来),那么我们需要在应用程序中编写原生sql语句,然后使用pymysql模块远程操作mysql数据库,但是直接编写原生sql语句会存在两方面的问题,严重影响开发效率,如下
-
- sql语句的执行效率:应用开发程序员需要耗费一大部分精力去优化sql语句
- 数据库迁移:针对mysql开发的sql语句无法直接应用到oracle数据库上,一旦需要迁移数据库,便需要考虑跨平台问题
-
为了解决上述问题,django引入了ORM的概念,ORM全称Object Relational Mapping,即对象关系映射,是在pymysq之上又进行了一层封装,对于数据的操作,我们无需再去编写原生sql,取代代之的是基于面向对象的思想去编写类、对象、调用相应的方法等,,ORM会将其转换/映射成原生SQL然后交给pymysql执行

二、单表查询
创建django项目,新建名为app01的app,在app01的models.py中创建模型
class Employee(models.Model): # 必须是models.Model的子类
id=models.AutoField(primary_key=True)
name=models.CharField(max_length=16)
gender=models.BooleanField(default=1)
birth=models.DateField()
department=models.CharField(max_length=30)
salary=models.DecimalField(max_digits=10,decimal_places=1)
在表生成之后,如果需要增加、删除、修改表中字段,需要这么做
# 一:增加字段
#1.1、在模型类Employee里直接新增字段,强调:对于orm来说,新增的字段必须用default指定默认值
publish = models.CharField(max_length=12,default='人民出版社',null=True)
#1.2、重新执行那两条数据库迁移命令
# 二:删除字段
#2.1 直接注释掉字段
#2.2 重新执行那两条数据库迁移命令
# 三:修改字段
#2.1 将模型类中字段修改
#2.2 重新执行那两条数据库迁移命令
添加表记录
方式一:
# 每个模型表下都有一个objects管理器,用于对该表中的记录进行增删改查操作,其中增加操作如下所示
models.Book.objects.create(title = '三国演义',price = 12.22)
方式二:
#1、用模型类创建一个对象,一个对象对应数据库表中的一条记录
book_obj = models.Book(title='三国演义',price='12.22')
# 2、调用对象下的save方法,即可以将一条记录插入数据库
book_obj.save()
删:
可以直接调用记录对象下的delete方法,该方法运行时立即删除本条记录而不返回任何值,如下
(需要强调的是管理objects下并没有delete方法,这是一种保护机制,是为了避免意外地调用 Employee.objects.delete() 方法导致所有的记录被误删除从而跑路。但如果你确认要删除所有的记录,那么你必须显式地调用管理器下的all方法,拿到一个QuerySet对象后才能调用delete方法删除所有)
models.Book.objects.filter(pk=2).delete()
改
models.Book.objects.filter(pk=2).update(title = '红楼梦',price = 22.22)
Queryset队像和mployee对象
-
以及下面必知必会的13条都是查的
-
注:返回值都是一个模型类Employee的对象,为了后续描述方便,我们统一将模型类的对象称为"记录对象",每一个”记录对象“都唯一对应表中的一条记录
-
查询的结果都有可能包含多个记录对象,为了存放查询出的多个记录对象,django的ORM自定义了一种数据类型Queryeset,所以下述方法的返回值均为QuerySet类型的对象,QuerySet对象中包含了查询出的多个记录对象
-
QuerySet类型是django ORM自定义的一种数据类型专门用来存放查询出的多个记录对象,该类型的特殊之处在于
-
1、queryset类型类似于python中的列表,支持索引操作
过滤出符合条件的多个记录对象,然后存放到QuerySet对象中 queryset_res=Employee.objects.filter(department='技术部') # 按照索引从QuerySet对象中取出第一个记录对象 obj=queryset_res[0] print(obj.name,obj.birth,obj.salary) -
管理器objects下的方法queryset下同样可以调用,并且django的ORM支持链式操作,于是我们可以像下面这样使用
res=Employee.objects.filter(gender=1).order_by('-id').values_list('id','name') print(res) # 输出:<QuerySet [(6, 'Robin'), (5, 'Jack'), (4, 'Tom'), (2, 'Kevin')]>
-
查
res = models.Book.objects.filter(pk=2)
all():查所有,查询结果为Queryset对象
res = models.Book.objects.all()
print(res)
filter:查询结果为Queryset对象
res = models.Book.objects.filter(pk=2)
print(obj.id,obj.name) # 输出:2 三国
get():查询结果为数据对象本身,和filter查询相似,不推荐使用,查询结果为Employee的对象
res = models.Book.objects.get(pk=2)
first():查询第一个,查询结果为Employee的对象
res = models.Book.objects.first()
last():查询最后一个,查询结果为Employee的对象
res = models.Book.objects.last() #res可以.title,.price
exclude():哪一个排除之外,查询结果为Queryset对象
res = models.Book.objects.exclude(pk=3)
values(): 有参,参数为字段名,可以指定多个字段,查询结果为列表套字典的Queryset对象
res = models.Book.objects.values('id','name')
print(res) # 输出:<QuerySet [{'id': 1, 'name': 'Egon'}, {'id': 2, 'name': 'Kevin'}, ......]>
print(res[0]['name']) # 输出:Egon
value_list():查询结果为列表套元组的Queryset对象,返回值为QuerySet对象,QuerySet对象中包含的并不是一个个的记录对象,而上多个小元组,字典的key即我们传入的字段名
res = models.Book.objects.values_list('id','name')
print(res) # 输出:<QuerySet [(1, 'Egon'), (2, 'Kevin'),), ......]>
print(res[0][1]) # 输出:Egon
count():统计数据的条数
res = models.Book.objects.count('title')
res = models.Book.objects.all.count('title')
distinct():数据必须是一模一样的情况下去重
res = models.Book.objects.distinct() #无变化
res = models.Book.objects.values('title').distinct()
order_by():排序 ,查询结果为Queryset对象
res = models.Book.objects.order_by('price') #默认升序
res = models.Book.objects.order_by('-price') #降序
reverse():排序后反转(才有意义)
res = models.Book.objects.reverse()
exists():是否存在
models.Book.objects.filter(pk=1).exists()
神奇的双下划线的模糊查询
查询价格大于200的书籍
models.Book.objects.filter(price__gt=200)
查询价格小于200的书籍
models.Book.objects.filter(price__lt=200)
查询价格大于等于200的书籍
models.Book.objects.filter(price__gte=200)
查询价格小于等于200的书籍
models.Book.objects.filter(price__lte=200)
查询价格是200元或者300元的书籍
res = models.Book.objects.filter(price__in=[200,300])
查询价格是200到500元之间的书籍
res = models.Book.objects.filter(price__range=(200,500)) #顾头不顾尾
查询书籍中包含p的书籍
res = models.Book.objects.filter(title__contains='p') #区分大小写
res = models.Book.objects.filter(title__icontains='p') #不区分大小写
查询书籍名称是以三开头的书籍
res = models.Book.objects.filter(title__startswith="三")
查询书籍名称是以三结尾的书籍
res = models.Book.objects.filter(title__endswith="三")
查询出版日期是2019年的书籍
res = models.Book.objects.filter(data__year="2019")
查询出版日期是10月份的书籍
res = models.Book.objects.filter(data__month="10")
聚合查询
关键字:aggregate
- aggregate()的返回值为字典类型,字典的key是由”聚合字段的名称___聚合函数的名称”合成的
from django.db.models import Max,Min,Sum,Count,Avg # 导入聚合函数
统计所有书的平均价格
res = models.Book.objects.all().aggregate(Avg('price')) #拿所有的书籍的价格的平均值
# 调用objects下的aggregate()方法,会把表中所有记录对象整体当做一组进行聚合
print(res) # {'price_avg':71.0}
这样的话就可以求最大的价格,最小的价格等
分组查询
分组查询annotate()相当于sql语句中的group by,是在分组后,对每个组进行单独的聚合,需要强调的是,在进行单表查询时,annotate()必须搭配values()使用:values("分组字段").annotate(聚合函数)
关键字:annotate
# 表中记录
mysql> select * from app01_employee;
+----+-------+--------+------------+------------+--------+
| id | name | gender | birth | department | salary |
+----+-------+--------+------------+------------+--------+
| 1 | Egon | 0 | 1997-01-27 | 财务部 | 100.1 |
| 2 | Kevin | 1 | 1998-02-27 | 技术部 | 10.1 |
| 3 | Lili | 0 | 1990-02-27 | 运营部 | 20.1 |
| 4 | Tom | 1 | 1991-02-27 | 运营部 | 30.1 |
| 5 | Jack | 1 | 1992-02-27 | 技术部 | 11.2 |
| 6 | Robin | 1 | 1988-02-27 | 技术部 | 200.3 |
| 7 | Rose | 0 | 1989-02-27 | 财务部 | 35.1 |
+----+-------+--------+------------+------------+--------+
# 查询每个部门下的员工数
res=Employee.objects.values('department').annotate(num=Count('id'))
# 相当于sql:
# select department,count(id) as num from app01_employee group by department;
print(res)
# 输出:<QuerySet [{'department': '财务部', 'num': 2}, {'department': '技术部', 'num': 3}, {'department': '运营部', 'num': 2}]>
-
跟在annotate前的values方法,是用来指定分组字段,即group by后的字段,而跟在annotate后的values方法,则是用来指定分组后要查询的字段,即select 后跟的字段
res=Employee.objects.values('department').annotate(num=Count('id')).values('num') # 相当于sql: # select count(id) as num from app01_employee group by department; print(res) # 输出:<QuerySet [{'num': 2}, {'num': 3}, {'num': 2}]> -
跟在annotate前的filter方法表示where条件,跟在annotate后的filter方法表示having条件,如下
# 查询男员工数超过2人的部门名
res=Employee.objects.filter(gender=1).values('department').annotate(male_count=Count("id")).filter(male_count__gt=2).values('department')
print(res) # 输出:<QuerySet [{'department': '技术部'}]>
# 解析:
# 1、跟在annotate前的filter(gender=1) 相当于 where gender = 1,先过滤出所有男员工信息
# 2、values('department').annotate(male_count=Count("id")) 相当于group by department,对过滤出的男员工按照部门分组,然后聚合出每个部门内的男员工数赋值给字段male_count
# 3、跟在annotate后的filter(male_count__gt=2) 相当于 having male_count > 2,会过滤出男员工数超过2人的部门
# 4、最后的values('department')代表从最终的结果中只取部门名
总结:
1、values()在annotate()前表示group by的字段,在后表示取值
1、filter()在annotate()前表示where条件,在后表示having
需要注意的是,如果我们在annotate前没有指定values(),那默认用表中的id字段作为分组依据,而id各不相同,如此分组是没有意义的,如下
res=Employee.objects.annotate(Count('name')) # 每条记录都是一个分组
res=Employee.objects.all().annotate(Count('name')) # 同上
F与Q查询
在上面所有的例子中,我们在进行条件过滤时,都只是用某个字段与某个具体的值做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
F查询:
- F() 的实例可以在查询中引用字段,来比较两个不同字段的值,
from django.db.models import F #导入模块
- Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作
查询卖出数大于库存数
models.Book.objects.filter(maichu__gt=F('kucun'))
查询评论数大于收藏数2倍的书籍
Book.objects.filter(commnetNum__lt=F('keepNum')*2)
将所有的书的价格全部提高100元
models.Book.objects.update(price=F('price')+ 100)
将所有书的名字后面都加上爆款
from django.db.models.functions import Concat
from django.db.models import Value
ret3=models.Product.objects.update(name=Concat(F('name'),Value('爆款')))
Q查询
查询书籍名称是python入门或者价格是54的书
models.Book.objects.filter(Q(title='python入门')|Q(price=54))
查询书籍名称不是python入门或者价格是54的书
models.Book.objects.filter(~Q(title='python入门')|Q(price=54))
Q查询进阶
查询条件由用户输入决定
q = Q()
q.connector = 'or' #将默认and,改为or
q.children.append(('title','python'))
q.children.append(('kucun',666))
res = models.Book.objects.filter(q)
字符串左边跟变量名书写的格式一模一样
查询优化(面试)
only与defer
only会将口号内的字段对应的值 直接封装到返回给你的对象中 点该字段 不需要再走数据库
一旦你点了不在括号内的字段 就会频繁的去走数据库查询
defer和only互为反关系,defer会将括号内的字段排除之外,将其他字段对应的值 直接封装到返回给你的对象中,点该其他字段 不需要再走数据库,一旦你点了在括号内的字段 就会频繁的去走数据库查询
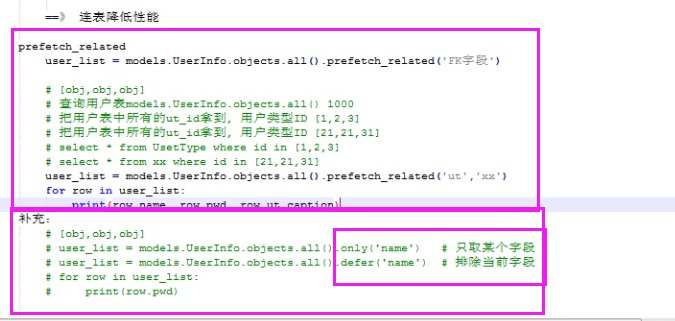
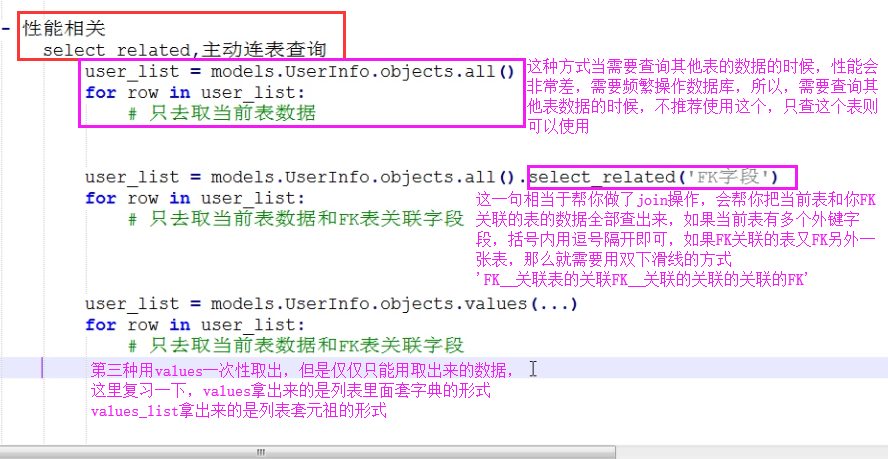
select_related与prefetch_related
select_related会自动帮你做连表操作,然后连表之后的数据全部查询出来封装给对象
select_related括号内只能放外键字段,并且多对多字段除外
如果括号内所关联的外键字段还有外键字段,还可以继续连表
select_related(外键字段__外键字段__外键字段...)
prefetch_relate看似是连表操作,其实是子查询,内部不做连表,小号的资源就在查询次数上,但是给用户感觉不出来
Django ORM中的事务操作
ACID:原子性、一致性、隔离性、持久性
from django.db import transaction
with transaction.atomic():
#在该代码块中所写的orm语句 同属于一个事务
#缩进出来之后自动结束
补充知识:
django2.x版本:在建数据库关系的时候需要手动指定2个参数,要告诉django级联更新,级联删除,是否建立外键约束
on_delete,db_constraint