Django之路由(urls)层
路由的作用
路由即请求地址与视图函数的映射关系,如果把网站比喻为一本书,那路由就好比是这本书的目录,在Django中路由默认配置在urls.py中
简单的路由配置
# urls.py
from django.conf.urls import url
# 由一条条映射关系组成的urlpatterns这个列表称之为路由表
urlpatterns = [
url(regex, view, kwargs=None, name=None), # url本质就是一个函数
]
#函数url关键参数介绍
# regex:正则表达式,用来匹配url地址的路径部分,
# 例如url地址为:http://127.0.0.1:8001/index/,正则表达式要匹配的部分是index/
# view:通常为一个视图函数,用来处理业务逻辑
# kwargs:略(用法详见有名分组)
# name:略(用法详见反向解析)
难点解释
-
如浏览器输入输入:http://127.0.0.1:8001/index/,Django会拿着路径部分index/去路由表中自上而下匹配正则表达式,一旦匹配成功,则立即执行其后的视图函数,不会继续往下匹配,此处匹配成功的正则表达式是 r'^index/$'。
-
如浏览器输入输入:http://127.0.0.1:8001/index,同样也会匹配,但是和url中的不一样,少一个/,但实际也会匹配成功,原因如下:
- 在配置文件settings.py中有一个参数APPEND_SLASH,该参数有两个值True或False
当APPEND_SLASH=True(如果配置文件中没有该配置,APPEND_SLASH的默认值为True),并且用户请求的url地址的路径部分不是以 / 结尾,Django会在路径后面加/,即index/)再去路由表中匹配,如果匹配失败则会返回路径未找到,如果匹配成功,则会返回重定向信息给浏览器,要求浏览器重新向 http://127.0.0.1:8001/index/地址发请求。APPEND_SLASH=False时,则不会执行上述过程,即一旦url地址的路径部分匹配失败就立即返回路径未找到,不会做任何的附加操作
- 在配置文件settings.py中有一个参数APPEND_SLASH,该参数有两个值True或False
无名分组与有名分组
首先什么是分组、为何要分组呢?
-
其实Django要将携带在网址后面的参数取出来,这就用到了正则表达式的分组功能了,分组分为两种:无名分组与有名分组.
-
有名分组和无名分组都是为了获取路径中的参数,并传递给视图函数,区别在于无名分组是以位置参数的形式传递,有名分组是以关键字参数的形式传递。
无名分组
对于正则加括号,会将括号内匹配到的内容当做位置参数传递给后面的视图函数test(request,args)
eg:
urls.py文件
url(r'^test/(d+)/',views.test)
# 上述正则表达式会匹配url地址的路径部分为:test/数字/,匹配成功的分组部分会以位置参数的形式传给视图函数,有几个分组就传几个位置参数
views.py文件
# 需要额外增加一个形参用于接收传递过来的分组数据
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容...' %article_id)
运行
在浏览器输入:http://127.0.0.1:8001/article/3/ 会看到: id为 3 的文章内容...
有名分组
就是给正则起个别名
会将括号内匹配到的内容当做关键字参数传递给后面的视图函数test(request,month=123)
这个month也可以是其他值
eg:
urls.py文件
url(r'^test/(?P<month>d+)/',views.test)
# 该正则会匹配url地址的路径部分为:text/数字/,匹配成功的分组部分会以关键字参数(month=匹配成功的数字)的形式传给视图函数,有几个有名分组就会传几个关键字参数
views.py文件
# 需要额外增加一个形参,形参名必须为month
def article(request,month):
return HttpResponse('id为 %s 的文章内容...' %article_id)
注意
有名分组和无名分组不能结合使用,但是无名和有名分组单独使用的情况下可以使用多次,就是一个里面有多个分组
eg:
url(r'^test/(d+)/(d+)/',views.test)
url(r'^test/(?P<month>d+)/(?P<month>d+)/',views.test)
路由分发
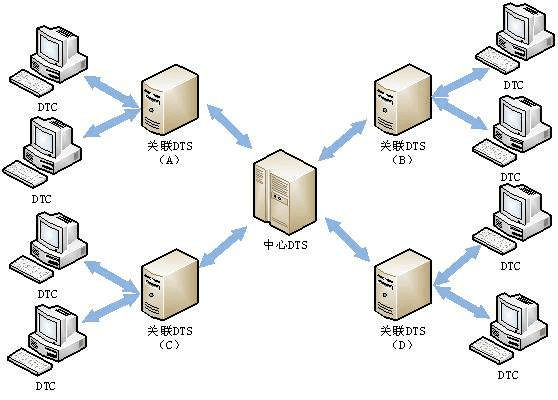
为什么要分发路由
- 随着项目功能的增加,app会越来越多,路由也越来越多,每个app都会有属于自己的路由,如果再将所有的路由都放到一张路由表中,会导致结构不清晰,不便于管理,所以我们应该将app自己的路由交由自己管理,然后在总路由表中做分发,具体做法如下
- Django里面的APP可以有自己的templates文件夹,static文件夹,和urls.py文件
总路由项目名下的urls.py不再做路由与视图函数对应关系了,而是做一个中转站,只负责将请求分发到不同的app中,在app中做视图函数的对应关系
1.在每个app下手动创建urls.py来存放自己的路由,如下:app01下的urls.py文件
from app01 import views
urlpatterns = [
url(r'^index/$',views.index),
]
3 在总的urls.py文件中(mysite2文件夹下的urls.py)
from django.conf.urls import url,include
url(r'^app01/',include(app01_urls)),
url(r'^app02/',include(app02_urls))
# include函数就是做分发操作的,当在浏览器输入http://127.0.0.1:8001/app01/index/时,会先进入到总路由表中进行匹配,正则表达式r'^app01/'会先匹配成功路径app01/,然后include功能会去app01下的urls.py中继续匹配剩余的路径部分
反向解析
-
在软件开发初期,url地址的路径设计可能并不完美,后期需要进行调整,如果项目中很多地方使用了该路径,一旦该路径发生变化,就意味着所有使用该路径的地方都需要进行修改,这是一个非常繁琐的操作。
-
解决方案就是在编写一条url(regex, view, kwargs=None, name=None)时,可以通过参数name为url地址的路径部分起一个别名,项目中就可以通过别名来获取这个路径。以后无论路径如何变化别名与路径始终保持一致,上述方案中通过别名获取路径的过程称为反向解析
eg:
url(r'^login/$', views.login,name='login_page'), # 路径login/的别名为login_page
前段解析
{%url 'xxx' %}
login页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>登录页面</title>
</head>
<body>
<!--强调:login_page必须加引号-->
<form action="{% url 'login_page' %}" method="post">
{% csrf_token %} <!--强调:必须加上这一行,后续我们会详细介绍-->
<p>用户名:<input type="text" name="name"></p>
<p>密码:<input type="password" name="pwd"></p>
<p><input type="submit" value="提交"></p>
</form>
</body>
</html>
测试:
python manage.py runserver 8001
# 在浏览器输入:http://127.0.0.1:8001/login/ 会看到登录页面,输入正确的用户名密码会跳转到index.html
# 当我们修改路由表中匹配路径的正则表达式时,程序其余部分均无需修改
后端解析
导入模块
import revers
url = revers('xxx')
无名分组反向解析
url(r'^test_addsajdsjkahdkjasjkdh/(d+)/', views.testadd,name='xxx')
前端解析
在模版login.html文件中,反向解析的使用
<a href="{% url 'xxx' 1 %}">222</a>
后端解析
在views.py中,反向解析的使用:
url = reverse('xx',args=(1,)) # 相当于反向给他随意写一个参数
有名分组的反向解析
url(r'^test_addsajdsjkahdkjasjkdh/(?P<year>d+)/', views.testadd,name='xxx')
前段解析
<a href="{% url 'xxx' year=1 %}">222</a>
后端解析
url = reverse('xxx',kwargs={'year'=1})
名称空间
当我们的项目下创建了多个app,并且每个app下都针对匹配的路径起了别名,如果别名存在重复,那么在反向解析时则会出现覆盖,但是我们尽量不要重名,解决这个问题的方法之一就是避免使用相同的别名,如果就想使用相同的别名,那就需要用到django中名称空间的概念,将别名放到不同的名称空间中,这样即便是出现重复,彼此也不会冲突
1.总路由
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 传给include功能一个元组,元组的第一个值是路由分发的地址,第二个值则是我们为名称空间起的名字
url(r'^app01/', include(('app01.urls','app01'))),
url(r'^app02/', include(('app02.urls','app02'))),
]
2、修改每个app下的view.py中视图函数,针对不同名称空间中的别名'index_page'做反向解析
app01下的views.py
def index(request):
url=reverse('app01:index_page') # 解析的是名称空间app01下的别名'index_page'
return HttpResponse('app01的index页面,反向解析结果为%s' %url)
app02下的views.py
def index(request):
url=reverse('app02:index_page') # 解析的是名称空间app02下的别名'index_page'
return HttpResponse('app02的index页面,反向解析结果为%s' %url)
3.测试
浏览器输入:http://127.0.0.1:8001/app01/index/反向解析的结果是/app01/index/
在浏览器输入http://127.0.0.1:8001/app02/index/ 反向解析的结果是/app02/index/
总结
伪静态
将动态网页假装成是静态的,这样做的目的是为了提高百度等搜索引擎的SEO查询优先级
搜索引擎在收录网站的时候,会优先手撸看上去像是静态文件的资源
无论你怎么使用伪静态进行优化,都干不过RMB玩家
哈哈哈!!!
虚拟环境
通常针对不停地项目,只会安装该项目所用到的,用不到的一概不装
不同的项目有专门的解释器环境与之对应
每创建一个虚拟环境,就类似于重新下载了一个python解释器
实际功能中针对不同而项目,有一个交叫requestments.txt,该文件列出来的是一个个该项目需要用到的模块名和版本号
eg:
Django=1.11.11
nginx
后期会通过命令直接会去下载该文件内所有的模块及对应的版本
虚拟环境不要创建太多个,会占硬盘资源的操作
Django1版本和Django2 版本的区别
Django1.x
区别一:
urls.py中1.x用的是url,2.x用的是path
2.x中的第一个参数不支持正则表达式,些写什么就匹配什么
2.x里面还有re_path,这个re_path就好比1.x中的url
区别二:
django2.x默认支持一下5种转换器(Path converters)
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
例如
path('articles/<int:year>/<int:month>/<slug:other>/', views.article_detail)
# 针对路径http://127.0.0.1:8000/articles/2009/123/hello/,path会匹配出参数year=2009,month=123,other='hello'传递给函数article_detail