Jmeter关联
所谓关联,从业务角度讲,即:某些操作步骤与其相邻步骤存在一定的依赖关系,导致某个步骤的输入数据来源于上一步的返回数据,这时就需要“关联”来建立步骤之间的联系。
简单来说,就是:将上一个请求的响应结果作为下一个请求的参数。。。
这里的提取器,都可以作为jmeter中关联的使用。
一、边界提取器
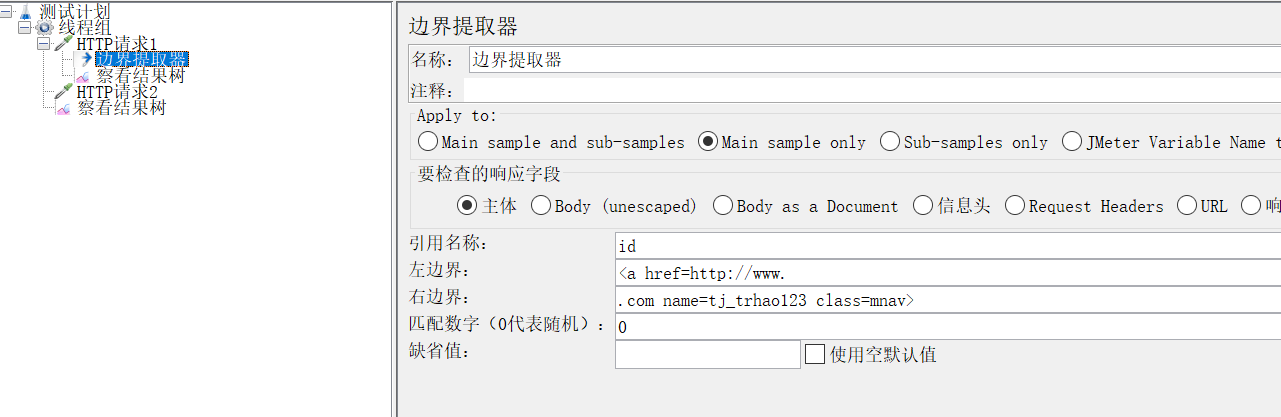
参数:前三个就不做介绍了;
(4)匹配数字:-1表示全部,0随机,1第一个,2第二个
(5)缺省值:这个如果没有匹配到,给它定义的一个默认值
这里和lr里的关联函数是差不多的,比如这里要提取hao123,
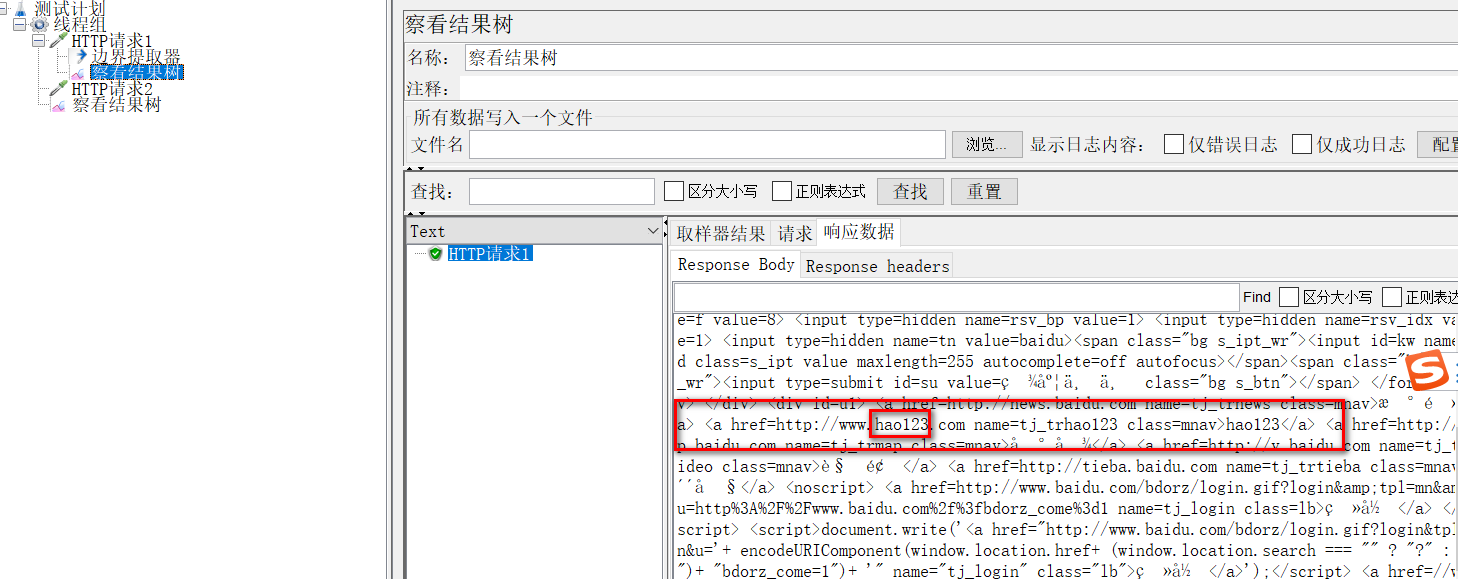
提取器填写如下:
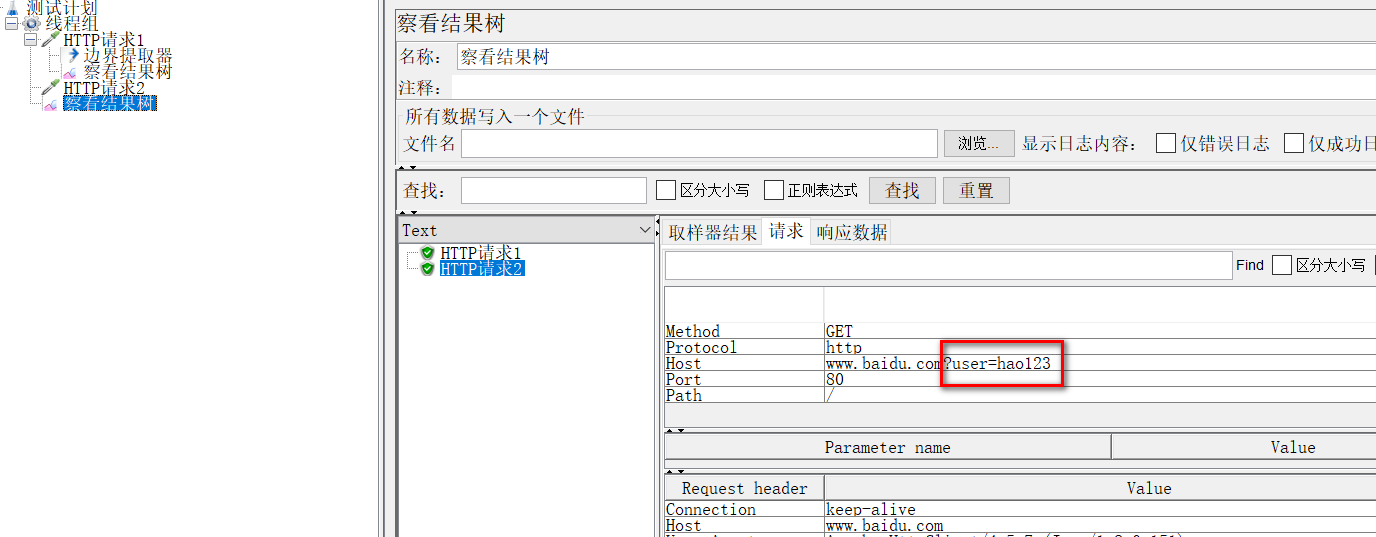
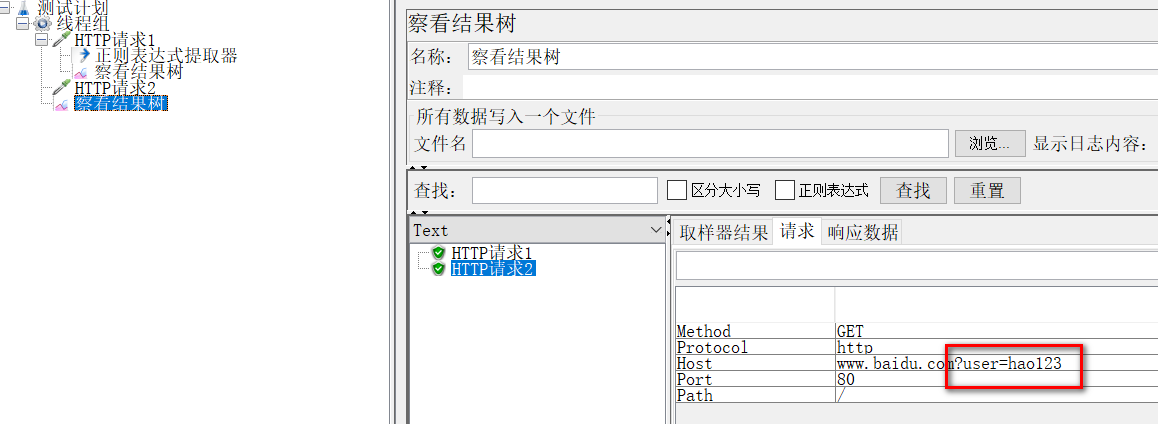
在请求2里引用:引用使用${变量名},这里为${id},如下图,就已经取到值了。
二、正则表达式提取器
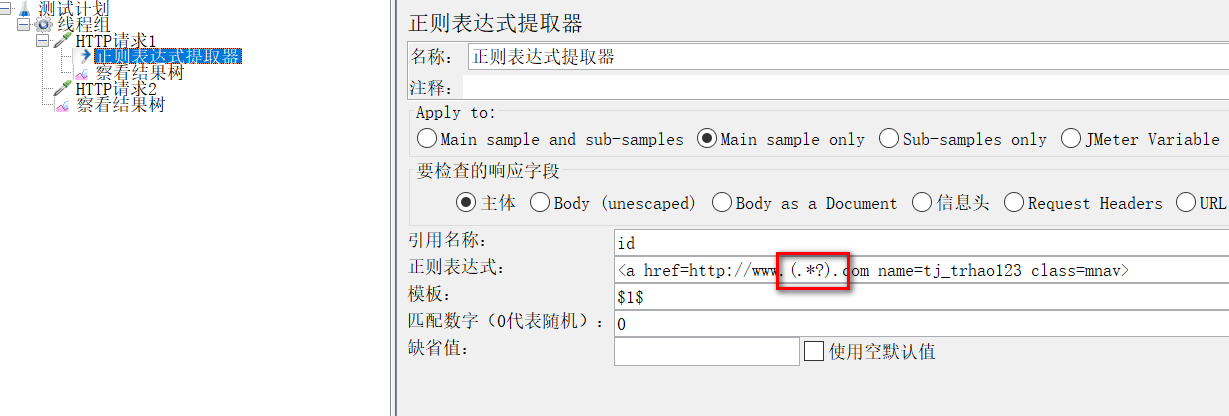
参数:
(1)就是变量名。
(2)正则表达式:
():括起来的部分就是要提取的。
.:匹配任何字符串。
(3)模板:用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给title。如:$1$表示解析到的第1个值
(4)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
(5)缺省值:如果参数没有取得到值,那默认给一个值让它取。
在请求2里引用:引用使用${变量名},这里为${id},如下图,就已经取到值了。
三、json提取器
jsonpath得使用详细:http://www.lemfix.com/topics/63
json提取器的示例:https://www.cnblogs.com/tudou-22/p/12579575.html
参数介绍:
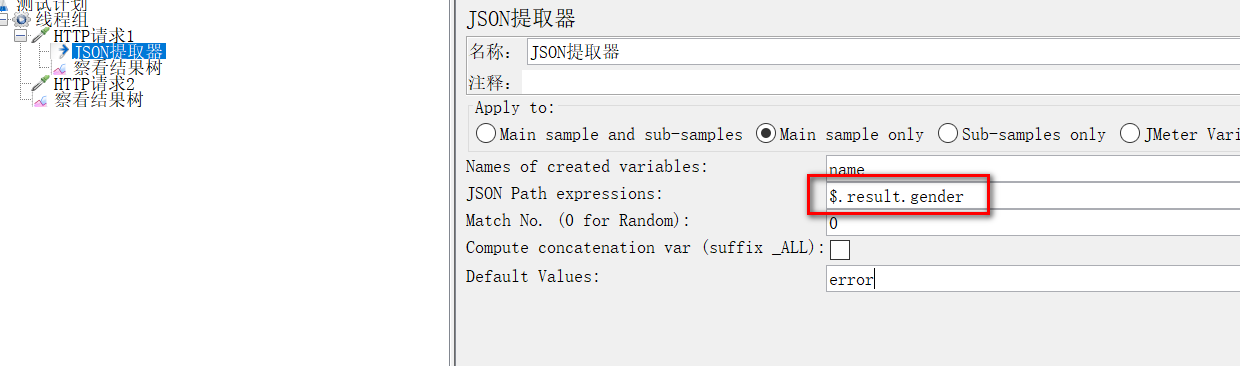
(1)names of created variables :接收值的变量名
(2)json path: json path表达式
(3)match no:0随机;n取第几个匹配值;-1匹配所有,后续引用用 变量名_N 取第N个值。
(4)default values: 缺省值,匹配不到值的时候取该值
如果返回的数据时json串,那么该如何提取呢?
这里说一下json提取器:
json数据为:{"statusCode":200,"data":{"userId":"4a2cbe616eb74f0d99190af072c8dea6","token":"37e7a9e198186f5a443e50e6138a5bd20bd"}}
则json path表达式为:$.data.token
json数据为:{"statusCode":200,"data":[{"code":"407949","id":"aa477ad2085d492a99b877d14343d68d","name":"90一中4545"}]}
则json path表达式为:$.data[0].id 【原来这个responses 的data为数组,故应为 $.data[0].id 提取第1个值】
例子:提取下面json里的性别
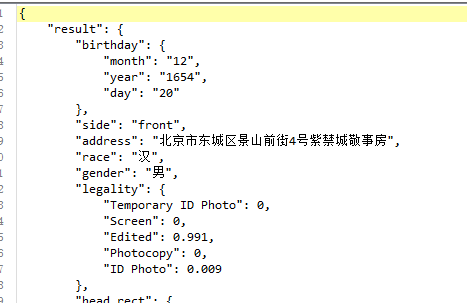
json提取器里填写如下:
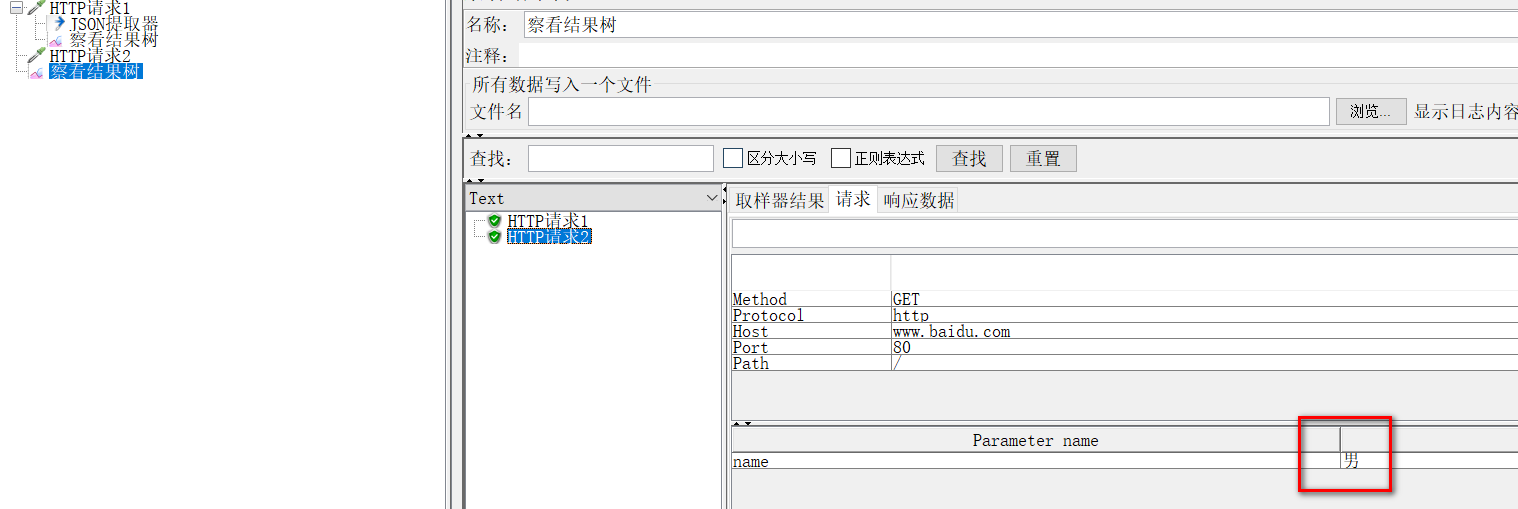
在请求2里引用:引用使用${变量名},这里为${name},如下图,就已经取到值了。
四、xpath提取器
XPath Extractor是另一个可被用来提取页面给定内容的Post Processor,XPath Extractor的使用方式与Regular Expression Extractor类似,只不过需要在该Extractor中指定的不是正则表达式,而是给定的XPath路径。
用xpath从前一个请求中取。这种形式比较适合于返回为xml片段的情况。在需要获得数据的请求上右击添加一个后置处理器-->xPath Extractor。引用名称即下一个请求要引用的参数名称,如填写body,则可用${body}引用它。
Xpath一般用于返回xml用得多。
这里需要学习xpath的写法
参数:
(1)Reference Name:存放提取出的值的参数。
(2)XPath Query:用于提取值的XPath表达式。
(3)Default Value:参数的默认值。
面板介绍:

【小注】正则表达式提取器和XPath Extractor的区别:
①正则表达式提取器可以用于对页面任何文本的提取,提取的内容是根据正则表达式在页面内容中进行文本匹配;
②XPath Extractor则可以提取返回页面任意元素的任意属性;
③如果需要提取的文本是页面上某元素的属性值,建议使用XPath Extractor;
④如果需要提取的文本在页面上的位置不固定,或者不是元素的属性,建议使用正则表达式提取器。