学习目的:
解决AJAX请求的爬虫,网页解析库的学习,MongoDB的简单应用
正式步骤
Step1:流程分析
- 抓取单页内容:利用requests请求目标站点,得到单个页面的html代码,返回结果;
- 抓取页面详情内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息;
- 下载图片并保存数据库:将图片下载到本地,把页面信息及图片url保存至MongoDB;
- 开启循环及多线程:对多页面内容遍历,开启多线程并提高抓取效率。
Step2:实例分析
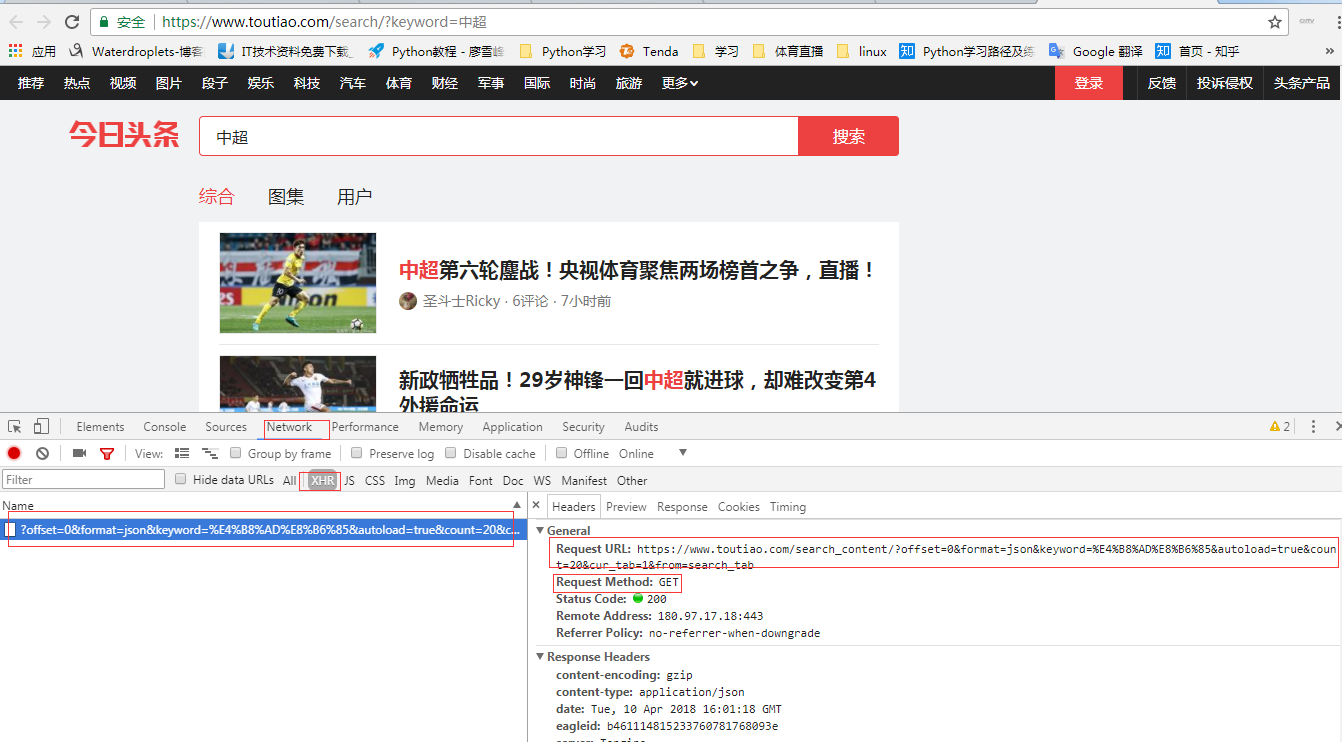
1. 打开今日头条搜索页,搜索“中超”,查看页面的请求方法为:GET
2. 创建一个Python文件:spider_ajax.py
3.网站url信息获取
4. 打印抓取的文章超链接和抓取的html内容
# -*- coding:utf-8 -*- import json from urllib.parse import urlencode from requests.exceptions import RequestException import requests def get_page_html(offset,keyword): data = { 'offset':offset, 'format':'json', 'keyword':keyword, 'autoload':'true', 'count':'20', 'cur_tab':1 } # urlencode把字典对象自动转化为url参数, # 快速导入,请选中以后,按alt+enter url = 'https://www.toutiao.com/search_content/?' + urlencode(data) try: response = requests.get(url) if response.status_code == 200: return response.text return None except RequestException: print('请求索引页失败') return None def parse_page_index(html): #因为html打印出来是json字符串格式,json.loads作用是将已编码的 JSON 字符串解码为 Python 对象 # json.dumps作用是将 Python 对象编码成 JSON 字符串 #参考http://www.runoob.com/python/python-json.html data = json.loads(html) if data and 'data' in data.keys(): for item in data.get('data'): yield item.get('article_url') def main(): html = get_page_html(0,'中超') #打印抓取的文章详细内容的url for url in parse_page_index(html): print(url) #打印获取页面内容 print(html) if __name__ == '__main__': main()
后面的内容因为爬虫被封,很多信息获取不到,暂时不会,以后再补全这节内容
学习总结:
想爬取商业的门户网站,感觉一脸懵逼