------------恢复内容开始------------
1,字符编码
ASCII 用1个字符来表示所有的英文字母和特殊符号
GB2313(GBK)用2个字符来表示英文字母及中文字符,且决定如果两个字节连在一起,每个字节的128的位置都是1的话,表示汉字,否则表示两个英文字母。
Unicode 现在的国际标准,使用4个字节来表示,且python3 默认使用的编码方式为Unicode编码形式。它可以跟各种编码相互转化。
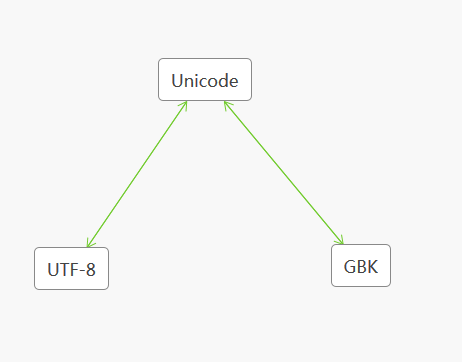
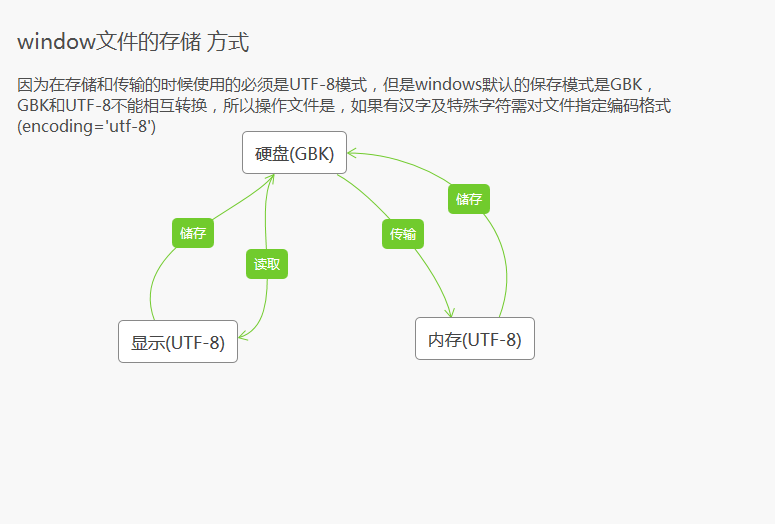
比如windows操作系统默认文件使用的是GBK编码,而Python3使用的是Unicode。
为了解决Unicode使用4个字节而浪费了硬盘空间,引入了UTF-8
UTF-8 在保存到硬盘和传输的时候使用的是UTF-8编码,因此在window保存文件的时候中文和其他特殊字符需要转化成UTF-8的 格式。
2,文件传输
编码和解码的含义:
编码是将Unicode转化成二进制格式
str.encode()
bytes(str,encoding)
解码是通过二进制转化成Unicode格式
bytes.decode()
str(byte,encoding)
操作文件三种特殊的方式:
w+ 写读 , 这个功能基本没什么意义,它会创建一个新文件 ,写一段内容,可以再把写的内容读出来,没什么卵用。
r+ 读写,能读能写,但都是写在文件最后,跟追加一样
a+ 追加读,文件 一打开时光标会在文件尾部,写的数据全会是追加的形式
追加:当使用JSON转化的数据中有中文是保存到文件中也会乱码
1 import json 2 3 data = { 4 'name':'吴某人', 5 'gender':'男', 6 'birthday':'1993-11-24', 7 } 8 print(json.dumps(data)) #其实这里转化的时候就已经乱码了。并不是保存的时候乱码 9 with open('data1.json','w',encoding='utf-8') as f: 10 f.write(json.dumps(data)) 11 f.write(data)
在JSON转化的时候加上ensure_ascii=False就不会乱码了
1 import json 2 3 data = { 4 'name':'吴某人', 5 'gender':'男', 6 'birthday':'1993-11-24', 7 } 8 print(json.dumps(data)) 9 with open('data.json','w',encoding='utf-8') as f: 10 f.write(json.dumps(data,ensure_ascii=False,indent=2))