在分布式服务中,要实现数据源得选择有如下相关方案
- DAO:继承 AbstractRoutingDataSource 类,实现对应的切换数据源的方法,结合自定义注解 + 切面实现动态数据源切换。
- ORM:MyBatis 插件进行数据源切换
- JDBC:Sharding-JDBC 基于客户端的分库分表方案
- Proxy:Mycat、Sharding-Proxy 基于代理的分库分表方案
- Server:特定数据库或者版本
- .........
基本概念及架构:
Sharding JDBC 是从当当网的内部架构 ddframe 里面的一个分库分表的模块脱胎出来的,用来解决当当的分库分表的问题,把跟业务相关的敏感的代码剥离后,就得到了 Sharding-JDBC。它是一个工作在客户端的分库分表的解决方案。
DubboX,Elastic-job 也是当当开源出来的产品。

2018 年 5 月,因为增加了 Proxy 的版本和 Sharding-Sidecar(尚未发布),Sharding-JDBC 更名为 Sharding Sphere,从一个客户端的组件变成了一个套件。
2018 年 11 月,Sharding-Sphere 正式进入 Apache 基金会孵化器,这也是对Sharding-Sphere 的质量和影响力的认可。不过现在还没有毕业(名字带 incubator),
一般我们用的还是 io.shardingsphere 的包。因为更名后和捐献给 Apache 之后的 groupId 都不一样,在引入依赖的时候千万要注意。主体功能是相同的,但是在某些类的用法上有些差异,如果要升级的话 import 要全部修改,有些类和方法也要修改。
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
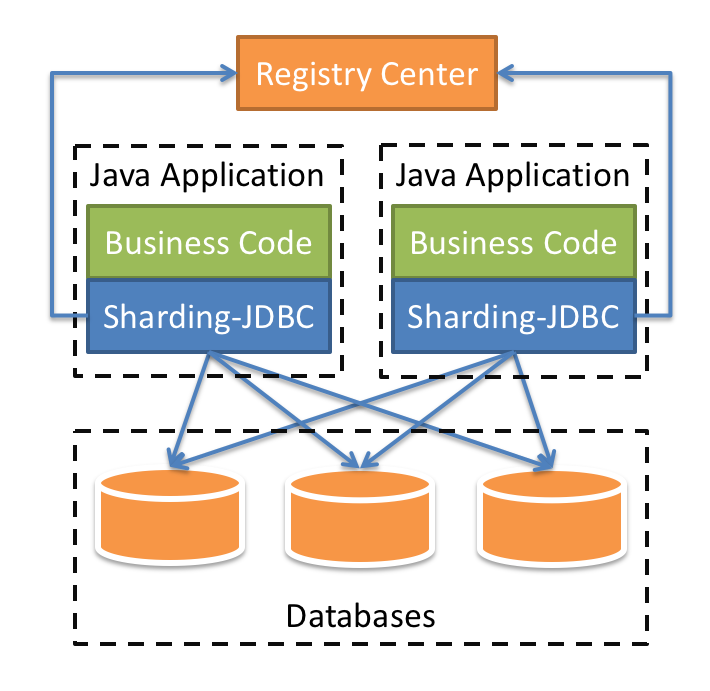
在 maven 的工程里面,我们使用它的方式是引入依赖,然后进行配置就可以了,不用像 Mycat 一样独立运行一个服务,客户端不需要修改任何一行代码,原来是 SSM 连接数据库,还是 SSM,因为它是支持 MyBatis 的。
我们在项目内引入 Sharding-JDBC 的依赖,我们的业务代码在操作数据库的时候,就会通过 Sharding-JDBC 的代码连接到数据库。分库分表的一些核心动作,比如 SQL 解析,路由,执行,结果处理,都是由它来完成的。它工作在客户端。
在 Sharding-Sphere 里面同样提供了代理 Proxy 的版本,跟 Mycat 的作用是一样的。Sharding-Sidecar 是一个 Kubernetes 的云原生数据库代理,正在开发中。

核心功能 :
分库分表后的几大问题:跨库关联查询、分布式事务、排序翻页计算、全局主键。
数据分片
- 分库 & 分表
- 读写分离:https://shardingsphere.apache.org/document/current/cn/features/read-write-split/
- 分片策略定制化
- 无中心化分布式主键(包括 UUID、雪花、LEAF)
分布式事务:https://shardingsphere.apache.org/document/current/cn/features/transaction/
- 标准化事务接口
- XA 强一致事务
- 柔性事务
核心概念:
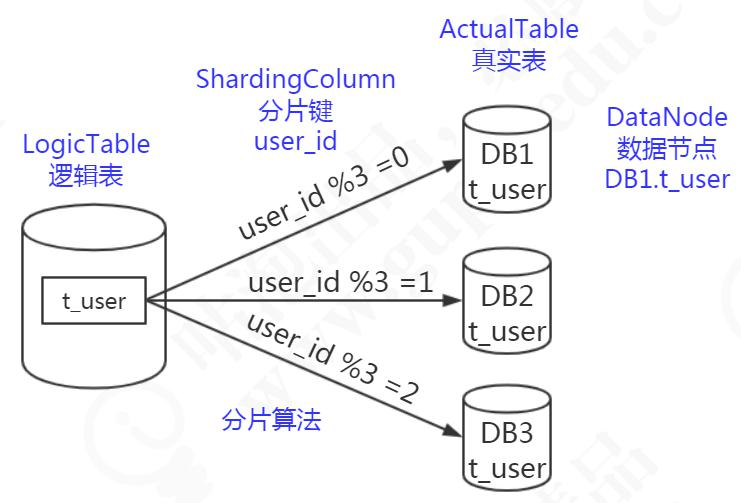
- 逻辑表:水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为 10 张表,分别是
t_order_0到t_order_9,他们的逻辑表名为t_order。 - 真实表:在分片的数据库中真实存在的物理表。即上个示例中的
t_order_0到t_order_9。 - 数据节点:数据分片的最小单元。由数据源名称和数据表组成,例:
ds_0.t_order_0。 - 绑定表:指分片规则一致的主表和子表。例如:
t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 - 广播表:指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
- 分片键:根据指定的分片键进行路由。分片键不一定是主键,也不一定有业务含义。
使用规范 :
虽然 Apache ShardingSphere 希望能够完全兼容所有的SQL以及单机数据库,但分布式为数据库带来了更加复杂的场景。包括一些特殊的 sql 或者分页都带来了巨大的挑战。对于这方面sharding-jdbc也做出了相关的说明
https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/
与 Mycat 对比 :
| Sharding-JDBC | Mycat | |
| 工作 层面 | JDBC 协议 | MySQL 协议/JDBC 协议 |
| 运行方式 | Jar 包,客户端 | 独立服务,服务端 |
| 开发 方式 | 代码/配置改动 | 连接地址(数据源) |
| 运维 方式 | 无 | 管理独立服务,运维成本高 |
| 性能 | 多线程并发按操作,性能高 | 独立服务+网络开销,存在性能损失风险 |
| 功能 范围 | 协议层面 | 包括分布式事务、数据迁移等 |
| 适用 操作 | OLTP | OLTP+OLAP |
| 支持 数据库 | 基于 JDBC 协议的数据库 | MySQL 和其他支持 JDBC 协议的数据库 |
| 支持 语言 | Java 项目中使用 | 支持 JDBC 协议的语言 |
| 维度 | 二维,支持分库又分表,比如user表继续拆分为user1、user2 | 一维,分了库后表不可以继续拆分,或者单库分表 |
从易用性和功能完善的角度来说,Mycat 似乎比 Sharding-JDBC 要好,因为有现成的分片规则,也提供了 4 种 ID 生成方式,通过注解可以支持高级功能,比如跨库关联查询。
建议:小型项目,分片规则简单的项目可以用 Sharding-JDBC。大型项目,可以用Mycat。
Sharding-JDBC 案例 :
Sharding-JDBC要实现分库分表的方案主要分为以下几个步骤:
- 配置数据源。
- 配置表规则 TableRuleConfiguration。
- 配置分库+分表策略 DatabaseShardingStrategyConfig,TableShardingStrategyConfig。
- 获取数据源对象。
- 执行数据库操作。
1.首先我们创建一个标准的springboot工程。还需要引入相关依赖:
<dependencies>
<!--sharding-jdbc -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
2.编写类 :
1 public class ShardJDBCTest {
2 public static void main(String[] args) throws SQLException {
3 // 1. 配置真实数据源
4 Map<String, DataSource> dataSourceMap = new HashMap<>();
5
6 // 配置第一个数据源
7 DruidDataSource dataSource1 = new DruidDataSource();
8 dataSource1.setDriverClassName("com.mysql.jdbc.Driver");
9 dataSource1.setUrl("jdbc:mysql://192.168.1.101:3306/shard0");
10 dataSource1.setUsername("root");
11 dataSource1.setPassword("123456");
12 dataSourceMap.put("ds0", dataSource1);
13
14 // 配置第二个数据源
15 DruidDataSource dataSource2 = new DruidDataSource();
16 dataSource2.setDriverClassName("com.mysql.jdbc.Driver");
17 dataSource2.setUrl("jdbc:mysql://192.168.1.104:3306/shard1");
18 dataSource2.setUsername("root");
19 dataSource2.setPassword("123456");
20 dataSourceMap.put("ds1", dataSource2);
21
22 // 2. 配置Order表规则
23 TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
24 orderTableRuleConfig.setLogicTable("order");
25 orderTableRuleConfig.setActualDataNodes("ds${0..1}.order${0..1}");
26
27
28 // 3. 配置分库 + 分表策略
29 orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "ds${order_id % 2}"));
30 orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "order${order_id % 2}"));
31
32 // 配置分片规则
33 ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
34 shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
35
36 Map<String, Object> map = new HashMap<>();
37
38 // 4.获取数据源对象
39 DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, map, new Properties());
40
41 String sql = "SELECT * from order WHERE user_id=?";
42 try (
43 Connection conn = dataSource.getConnection();
44 PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
45 preparedStatement.setInt(1, 2673);
46 System.out.println();
47 // 5.执行sql
48 try (ResultSet rs = preparedStatement.executeQuery()) {
49 while (rs.next()) {
50 // %2结果,路由到 shard1.order1
51 System.out.println("order_id---------" + rs.getInt(1));
52 System.out.println("user_id---------" + rs.getInt(2));
53 System.out.println("create_time---------" + rs.getTime(3));
54 System.out.println("total_price---------" + rs.getInt(4));
55 }
56 }
57 }
58 }
59 }
3.在两个库上都建立对应的 order1、order2 表,表结构一致。字段自己调整就行
运行上述main方法可以查看到相应的效果。
总结:ShardingRuleConfiguration 可以包含多个 TableRuleConfiguration(多张表),也可以设置默认的分库和分表策略。每个 TableRuleConfiguration 可以针对表设置 ShardingStrategyConfiguration,包括分库分分表策略。
ShardingStrategyConfiguration 有 5 种实现(标准、行内、复合、Hint、无)。ShardingDataSourceFactory 利用 ShardingRuleConfiguration 创建数据源。有了数据源,就可以走 JDBC 的流程了。
更多配置可以参考 https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/configuration/
整合SpringBoot :
Sharding-JDBC 进行与 SpringBoot 的整合是方便的,主要是进行配置文件的配置。
1.创建标准的SpringBoot 工程,再加入以下依赖:
<dependencies>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
<!--xa分布式事务-->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-transaction-2pc-xa</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-transaction-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
</dependencies>
2.进行 分库分表规则配置,新建 application-sharding.yml 文件 :
sharding:
jdbc:
datasource:
# 数据源
names: ds0,ds1
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.1.101:3306/shard0
username: root
password: 123456
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.1.104:3306/shard1
username: root
password: 123456
config:
sharding:
# 默认数据源,不分库分表到达这个数据源
default-data-source-name: ds0
#【默认分库策略】对user_id取模
default-database-strategy:
inline:
sharding-column: user_id
algorithm-expression: ds$->{user_id % 2}
# 【分表策略】
tables:
# dictionary是广播表
dictionary:
key-generator-column-name: dictionary_id
actual-data-nodes: ds$->{0..1}.dictionary
# user表只分库不分表
user:
key-generator-column-name: user_id
actual-data-nodes: ds$->{0..1}.user
# order表分库分表
order:
key-generator-column-name: order_id
actual-data-nodes: ds$->{0..1}.order$->{0..1}
table-strategy:
inline:
sharding-column: order_id
algorithm-expression: order$->{order_id%2}
# order_item表分库分表
order_item:
key-generator-column-name: order_item_id
actual-data-nodes: ds$->{0..1}.order_item$->{0..1}
table-strategy:
inline:
sharding-column: order_id
algorithm-expression: order_item$->{order_id%2}
props:
sql.show: true
3.其他关于 mybatis 的相关配置这里就不贴出来了。然后在数据库中创建对应的表。编写 dao、service 进行测试。关于事务、全局ID、自定义分片策略下篇博客中会详细介绍。