Redis3.0版本之前,可以通过Redis Sentinel(哨兵)来实现高可用 ( HA ),从3.0版本之后,官方推出了Redis Cluster,它的主要用途是实现数据分片(Data Sharding),不过同样可以实现HA,是官方当前推荐的方案。
在Redis Sentinel模式中,每个节点需要保存全量数据,冗余比较多,而在Redis Cluster模式中,每个分片只需要保存一部分的数据,对于内存数据库来说,还是要尽量的减少冗余。在数据量太大的情况下,故障恢复需要较长时间,另外,内存实在是太贵了。。。
Redis Cluster的具体实现细节是采用了Hash槽的概念,集群会预先分配16384个槽,并将这些槽分配给具体的服务节点,通过对Key进行CRC16(key)%16384运算得到对应的槽是哪一个,从而将读写操作转发到该槽所对应的服务节点。当有新的节点加入或者移除的时候,再来迁移这些槽以及其对应的数据。在这种设计之下,我们就可以很方便的进行动态扩容或缩容,个人也比较倾向于这种集群模式。

一个Redis Cluster由多个Redis节点构成。不同节点组服务的数据没有交集,也就是每一个节点组对应数据的一个分片。节点组内部分为主备两类节点,对应master和slave节点。两者数据准实时一致,通过异步化的主备复制机制来保证。一个节点组有且只有一个master节点,同时可以有0到多个slave节点,在这个节点组中只有master节点,同时可以有0到多个slave节点,在这个节点组中只有master节点对用户提供写服务,读服务可以由master或者slave提供。
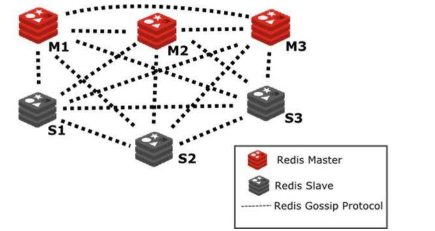
redis-cluster是基于gossip协议实现的无中心化节点的集群,因为去中心化的架构不存在统一的配置中心,各个节点对整个集群状态的认知来自于节点之间的信息交互。在Redis Cluster,这个信息交互是通过Redis Cluster Bus来完成的。
搭建集群:
Redis Cluster集群至少需要三个master节点,我将以3台主机的方式部署3个主节点及3个从节点。
1. 首先,在redis安装目录 /usr/local/redis/etc/下新建目录redisCluster,并在该目录下复制2个配置文件分别为6398,6399端口个,如下图:

具体配置拿6398做例子,其余均按照该配置进行修改:
daemonize yes #开启后台运行 port 6398 #工作端口 protected-mode no dir /usr/local/redis-cluster/6398/ #指定工作目录,rdb,aof持久化文件将会放在该目录下,不同实例一定要配置不同的工作目录 cluster-enabled yes #启用集群模式 cluster-config-file nodes-6398.conf #生成的集群配置文件名称,集群搭建成功后会自动生成,在工作目录下 cluster-node-timeout 5000 #节点宕机发现时间,可以理解为主节点宕机后从节点升级为主节点时间 appendonly yes #开启AOF模式 pidfile "/var/run/6398.pid" #pid file所在目录
logfile "6398.log"
2.将 3 台主机共 6 个服务全部启动:

3.由于创建集群需要用到redis-trib这个命令,它依赖Ruby和RubyGems,因此我们要先安装一下
yum -y install ruby ruby-devel rubygems rpm-build
gem install redis
在这里可能会报如下错误:

由于centos支持的ruby默认版本到2.0.0,因此需要安装RVM即Ruby的版本管理器:
yum install curl
curl -L get.rvm.io | bash -s stable
source /usr/local/rvm/scripts/rvm
rvm install 2.4.0
rvm use 2.4.0
gem install redis
执行以上步骤完成 安装,其中第三步骤我遇到的问题可能是由于网速原因,在多次执行后才安装成功,会提示complete。
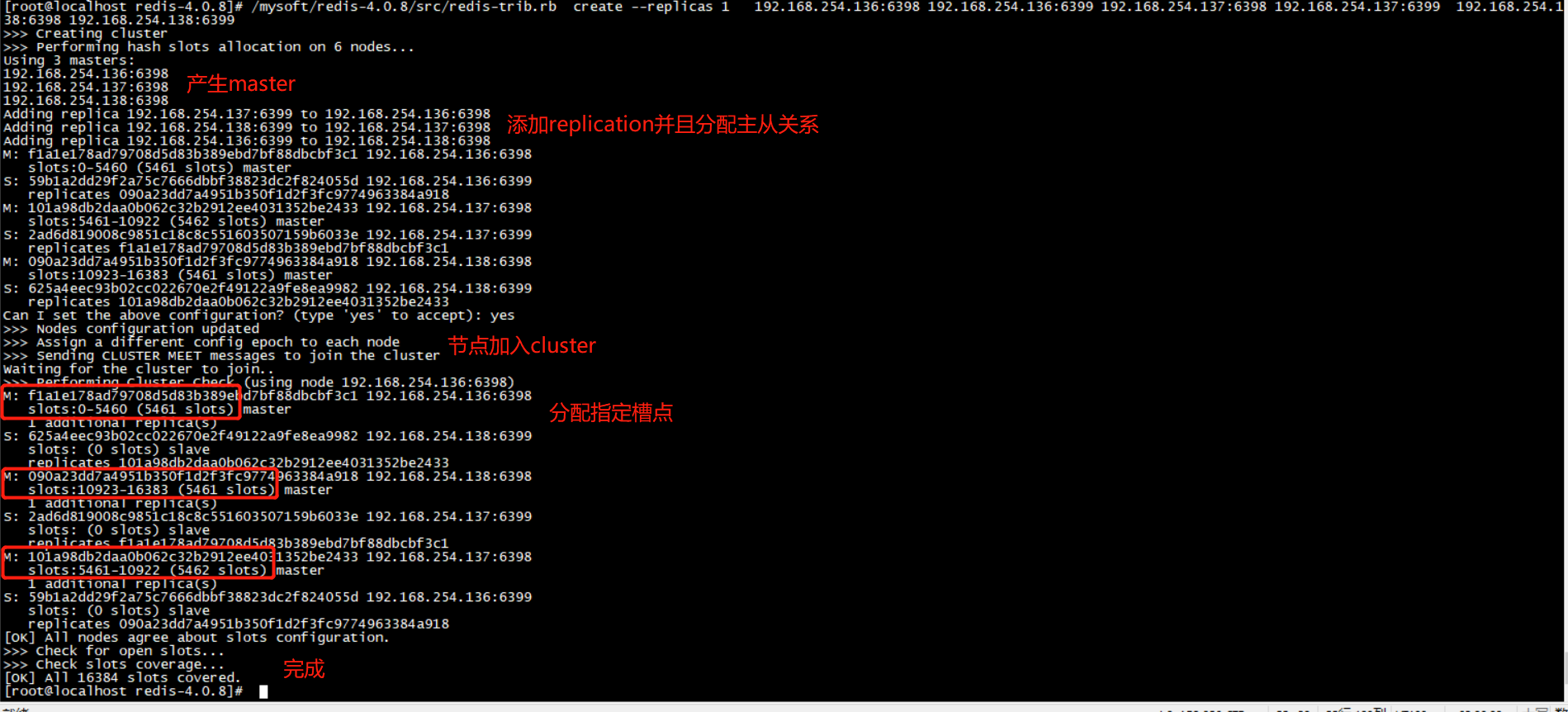
4.执行如下命令,完成 redis-cluster 集群配置,--replicas 1 这个1=主节点个数/从节点个数 。
/mysoft/redis-4.0.8/src/redis-trib.rb create --replicas 1
192.168.254.136:6398 192.168.254.136:6399
192.168.254.137:6398 192.168.254.137:6399
192.168.254.138:6398 192.168.254.138:6399
成功配置会显示如下信息:
如果遇到如下图的错误:

一直处于 waiting for the cluster to join ... 这种状态,需要开启redis集群总线端口,即redis服务节点的端口值+10000.将这些端口打开即可完成。
这里还会遇到另外一个问题,那就是 [ERR] Node 192.168.254.137:6398 is not empty.报出这种错误。
这个时候需要登录到每个节点,执行flushdb,然后删除每个节点的 .aof .rdb 以及对应的 nodes-6398.conf 。重启服务,这样子即可完成操作,然后重新分配。
如果是使用redis-trib.rb工具构建集群,集群构建完成前不要配置密码,集群构建完毕再通过config set + config rewrite命令逐个机器设置密码。如果对集群设置密码,那么requirepass和masterauth都需要设置,否则发生主从切换时,就会遇到授权问题,可以模拟并观察日志。各个节点的密码都必须一致,否则Redirected就会失败。
- config set masterauth abc
- config set requirepass abc
- config rewrite
//增加节点的顺序是先增加Master主节点,然后在增加Slave从节点。 redis-trib.rb add-node ip:port //增加节点 redis-trib.rb reshard ip:port //重新分配槽 cluster replicate 71ecd970838e9b400a2a6a15cd30a94ab96203bf(主节点的ID) //将节点设置为从节点 //删除的顺序是先删除Slave从节点,然后在删除Master主节点 redis-trib.rb del-node 192.168.127.130:7007 991ed242102aaa08873eb9404a18e0618a4e37bd(该节点ID) // 删除节点
一致性哈希:
如果是希望数据分布相对均匀的话,我们首先可以考虑哈希后取模。例如,hash(key)%N,根据余数,决定映射到那一个节点。这种方式比较简单,属于静态的分片规则。但是一旦节点数量变化,新增或者减少,由于取模的 N 发生变化,数据需要重新分布。为了解决这个问题,我们又有了一致性哈希算法。
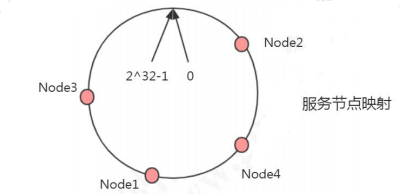
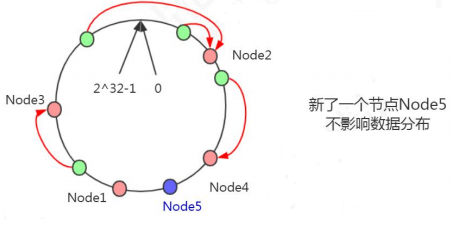
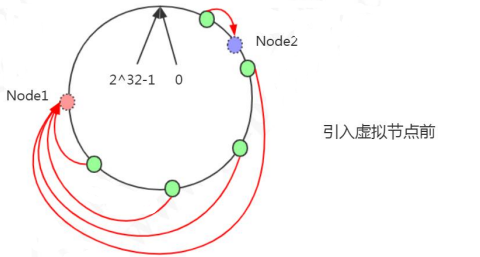
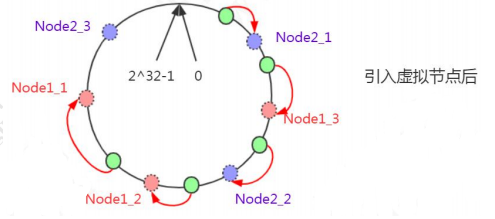
一致性哈希的原理:把所有的哈希值空间组织成一个虚拟的圆环(哈希环),整个空间按顺时针方向组织。因为是环形空间,0 和 2^32-1 是重叠的。假设我们有四台机器要哈希环来实现映射(分布数据),我们先根据机器的名称或者 IP 计算哈希值,然后分布到哈希环中(红色圆圈)。
现在有 4 条数据或者 4 个访问请求,对 key 计算后,得到哈希环中的位置(绿色圆圈)。沿哈希环顺时针找到的第一个 Node,就是数据存储的节点。
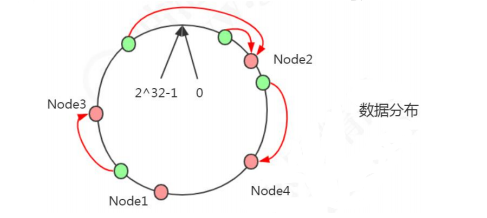
在这种情况下,新增了一个 Node5 节点,不影响数据的分布。
HashTags:
通过分片手段,可以将数据合理的划分到不同的节点上,这本来是一件好事。但是有的时候,我们希望对相关联的业务以原子方式进行操作。举个简单的例子我们在单节点上执行MSET , 它是一个原子性的操作,所有给定的key会在同一时间内被设置,不可能出现某些指定的key被更新另一些指定的key没有改变的情况。但是在集群环境下,我们仍然可以执行MSET命令,但它的操作不在是原子操作,会存在某些指定的key被更新,而另外一些指定的key没有改变,原因是多个key可能会被分配到不同的机器上。
所以,这里就会存在一个矛盾点,及要求key尽可能的分散在不同机器,又要求某些相关联的key分配到相同机器。这个也是在面试的时候会容易被问到的内容。怎么解决呢?从前面的分析中我们了解到,分片其实就是一个hash的过程,对key做hash取模然后划分到不同的机器上。所以为了解决这个问题,我们需要考虑如何让相关联的key得到的hash值都相同呢?如果key全部相同是不现实的,所以怎么解决呢?在redis中引入了HashTag的概念,可以使得数据分布算法可以根据key的某一个部分进行计算,然后让相关的key落到同一个数据分片
举个简单的例子,加入对于用户的信息进行存储, user:user1:id、user:user1:name/ 那么通过hashtag的方式,user:{user1}:id、user:{user1}.name; 表示当一个key包含 {} 的时候,就不对整个key做hash,而仅对 {} 包括的字符串做hash。
重定向客户端:
Redis Cluster并不会代理查询,那么如果客户端访问了一个key并不存在的节点,这个节点是怎么处理的呢?比如我想获取key为msg的值,msg计算出来的槽编号为6383,当前节点正好不负责编号为6383的槽,那么就会返回客户端下面信息:
(error) MOVED 6383 192.168.254.137:6398
表示客户端想要的254槽由运行在IP为192.168.254.137,端口为6398的Master实例服务。如果根据key计算得出的槽恰好由当前节点负责,则当期节点会立即返回结果.
redis客户端给我们提供了一个命令解决该问题
/mysoft/redis-4.0.8/src/redis-cli -h 192.168.254.138 -c -p 6398
执行 set 方法后会显示如下信息:

这里会帮我们重定向 指定的 槽点来完成数据的存储。
分片迁移:
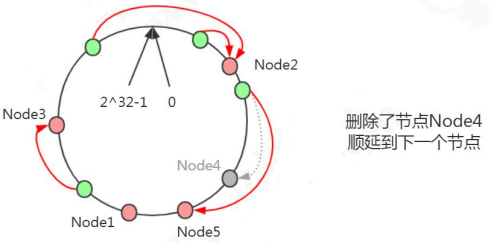
在一个稳定的Redis cluster下,每一个slot对应的节点是确定的,但是在某些情况下,节点和分片对应的关系会发生变更
1. 新加入master节点
2. 某个节点宕机
也就是说当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也要迁移。当然,这一过程,在目前实现中,还处于半自动状态,需要人工介入。新增一个主节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot到D上。大致就会变成这样:节点A覆盖1365-5460,节点B覆盖6827-10922,节点C覆盖12288-16383,节点D覆盖0-1364,5461-6826,10923-12287
删除一个主节点先将节点的数据移动到其他节点上,然后才能执行删除
槽迁移的过程:
槽迁移的过程中有一个不稳定状态,这个不稳定状态会有一些规则,这些规则定义客户端的行为,从而使得RedisCluster不必宕机的情况下可以执行槽的迁移。下面这张图描述了我们迁移编号为1、2、3的槽的过程中,他们在MasterA节点和MasterB节点中的状态。

简单的工作流程:
1. 向MasterB发送状态变更命令,把Master B对应的slot状态设置为IMPORTING
2. 向MasterA发送状态变更命令,将Master对应的slot状态设置为MIGRATING
当MasterA的状态设置为MIGRANTING后,表示对应的slot正在迁移,为了保证slot数据的一致性,MasterA此时对于slot内部数据提供读写服务的行为和通常状态下是有区别的,
MIGRATING状态:
1. 如果客户端访问的Key还没有迁移出去,则正常处理这个key
2. 如果key已经迁移或者根本就不存在这个key,则回复客户端ASK信息让它跳转到MasterB去执行
IMPORTING状态
当MasterB的状态设置为IMPORTING后,表示对应的slot正在向MasterB迁入,及时Master仍然能对外提供该slot的读写服务,但和通常状态下也是有区别的
1. 当来自客户端的正常访问不是从ASK跳转过来的,说明客户端还不知道迁移正在进行,很有可能操作了一个目前还没迁移完成的并且还存在于MasterA上的key,如果此时这个key在A上已经被修改了,那么B和A的修改则会发生冲突。所以对于MasterB上的slot上的所有非ASK跳转过来的操作,MasterB都不会处理,而是通过MOVED命令让客户端跳转到MasterA上去执行这样的状态控制保证了同一个key在迁移之前总是在源节点上执行,迁移后总是在目标节点上执行,防止出现两边同时写导致的冲突问题。而且迁移过程中新增的key一定会在目标节点上执行,源节点也不会新增key,使得整个迁移过程既能对外正常提供服务,又能在一定的时间点完成slot的迁移。
总结 :
优势
- 无中心架构。
- 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
- 可扩展性,可线性扩展到 1000 个节点(官方推荐不超过 1000 个),节点可动态添加或删除。
- 高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做 standby 数据副本,能够实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的角色提升。
- 降低运维成本,提高系统的扩展性和可用性。
不足
- Client 实现复杂,驱动要求实现 Smart Client,缓存 slots mapping 信息并及时更新,提高了开发难度,客户端的不成熟影响业务的稳定性。
- 节点会因为某些原因发生阻塞(阻塞时间大于 clutser-node-timeout),被判断下线,这种 failover 是没有必要的。
- 数据通过异步复制,不保证数据的强一致性。
- 多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的情况。