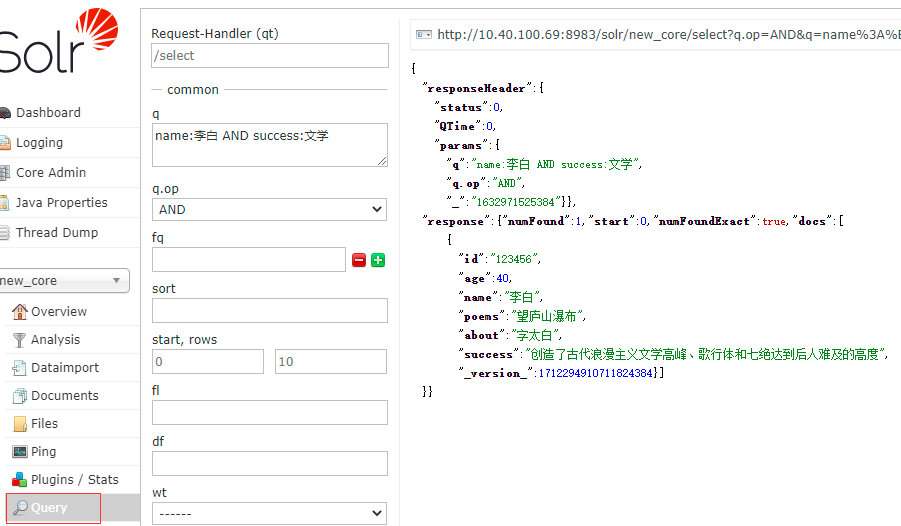
Solr 是基于 Lucene 的流行、高性能的开源企业级搜索平台。本文主要介绍 Solr 的基本概念及安装,文中使用到的软件版本:Solr 8.9.0、jdk1.8.0_181。
1、Solr 简介
Solr 是一个基于 Apache Lucene 之上的搜索服务器,它是一个开源的、基于 Java 的信息检索库。它旨在提供功能强大的文档检索服务。Solr 基于开放标准,是高度可扩展的。Solr 查询是简单的 HTTP 请求 URL,响应是一个结构化文档:主要是 JSON,但也可以是 XML、CSV 或其他格式。任何能够使用 HTTP 的平台都可以与 Solr 对话。
1.1、Solr 架构
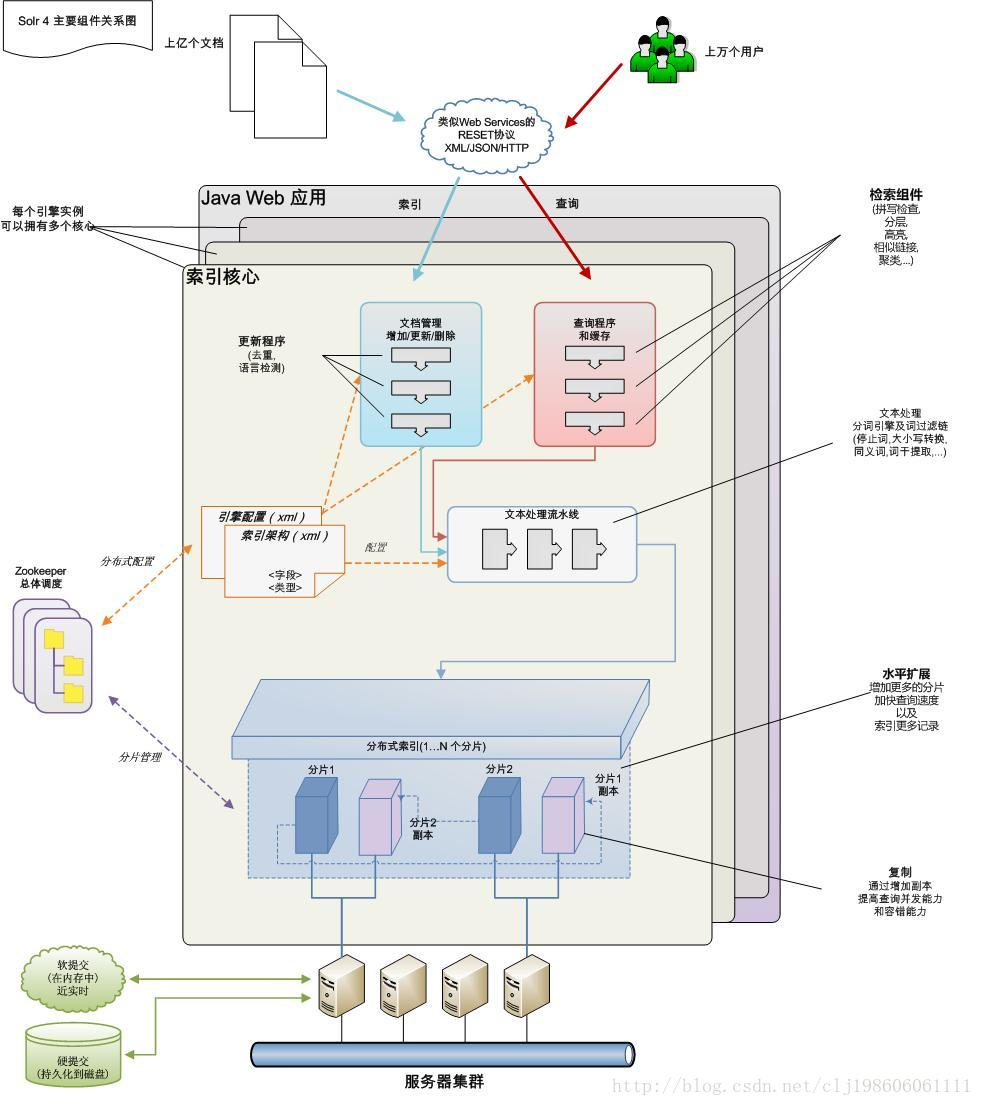
1.2、Solr 特点
a、Solr 基于已有的 XML、JSON 和 HTTP 标准,提供简单的类似 REST 的服务,这使得 Solr 可以被不同编程语言的应用访问。
b、Solr 可以使用 Zookeeper 实现简易分片和复制,统一配置。
c、为了提高查询速度和处理更多的文档,Solr 可以通过索引分片来实现分布式查询。
d、为了提高吞吐量和容错能力,可以为每个索引分片增加副本,同时,把所有的索引复制到其他的服务器搭建成一个服务器集群,提高吞吐量。
e、可通过缓存来提高查询速度,达到近实时查询。并写入到硬盘以达到持久化索引。
1.3、内核/集合
Solr 的内核是运行在 Solr 服务器中的具有唯一命名的、可管理的和可配置的索引。一台 Solr 服务器可以托管一个或多个内核。内核典型的用途是为了区分不同模式的文档。单机模式下,内核可以理解为一个索引库。
SolrCloud 引入了集合的概念,集合将具有唯一命名的、可管理的和可配置的索引扩展成不同的分片,并且分配到多台服务器上。分布式索引的每一个分片都托管在一个 Solr 的内核中,即多个内核可以组成一个索引库。
2、Solr 安装
2.1、下载安装包并解压
https://solr.apache.org/downloads.html
tar zxvf solr-8.9.0.tgz
2.2、目录说明
bin/ 该目录中包含几个重要的脚本:
solr/solr.cmd 这是 Solr 的控制脚本,用于启动和停止 Solr 服务。在 SlorCloud 模式下运行时,可以创建集合或内核,配置身份验证以及使用配置文件。
post 用于发布内容到 solr 的一个简单的命令行工具。
solr.in.sh/solr.in.cmd 此处配置 Java,Jetty 和 Solr 的系统级属性,即全局属性。
install_solr_services.sh 在 *nix 系统上将 Solr 安装为服务。
contrib/ 该目录包含 Solr 专用功能的附加插件。
dist/ 该目录包含主要的 Solr jar 文件。
docs/ solr 帮助文档。
example/ 包含几种演示各种 Solr 功能的示例。
licenses/ 包含 Solr 使用的第三方库的所有许可证。
server/ 该目录是 Solr 应用程序的核心所在:
Solr 的 Admin UI(server/solr-webapp)
Jetty 库(server/lib)
日志文件(server/logs)和日志配置(server/resources)
示例配置(server/solr/configsets)
2.3、启动/停止 Solr
bin/solr start [-p port]
bin/solr stop [-p port]
如果不指定端口,默认为 8983
2.4、控制台
http://10.40.10.66:8983/solr
2.5、创建/删除内核
bin/solr create -c new_core [-p port]
bin/solr delete -c new_core
默认在 server/solr 下会生成内核目录,内核目录下包含两个目录一个文件:
conf/:存放内核的配置文件。
data/:存放索引数据,相当于 lucene 中定义 IndexWriter 对象的第一个 Directory 参数。
core.preperties:内核的一些参数定义。
2.6、配置 IK 分词器
1、下载 IK 分词器的 jar 包放入 server/solr-webapp/webapp/WEB-INF/lib 目录下;可到 Maven 中央仓库(https://search.maven.org/)下载 jar 包:
<dependency> <groupId>com.github.magese</groupId> <artifactId>ik-analyzer</artifactId> <version>8.4.0</version> </dependency>
2、将 resources 目录下的 5 个配置文件放入 server/resources 目录下;可以在 github(https://github.com/magese/ik-analyzer-solr) 上下载这些配置文件:
IKAnalyzer.cfg.xml ext.dic stopword.dic ik.conf dynamicdic.txt
3、修改 Solr 的 managed-schema,添加 IK 分词器:
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
IK 分词器详细的使用可参考官网说明:https://github.com/magese/ik-analyzer-solr
3、Solr 控制台使用
3.1、添加核心
可以通过命令行来添加核心:
bin/solr create -c new_core
3.2、在核心中添加 schema 信息

可以在 managed-schema 中查看添加的字段信息:
<field name="about" type="text_ik" uninvertible="true" indexed="true" stored="true"/> <field name="age" type="pint" uninvertible="true" indexed="true" stored="true"/> <field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/> <field name="name" type="text_ik" uninvertible="true" indexed="true" stored="true"/> <field name="poems" type="text_ik" uninvertible="true" indexed="true" stored="true"/> <field name="success" type="text_ik" uninvertible="true" indexed="true" stored="true"/>
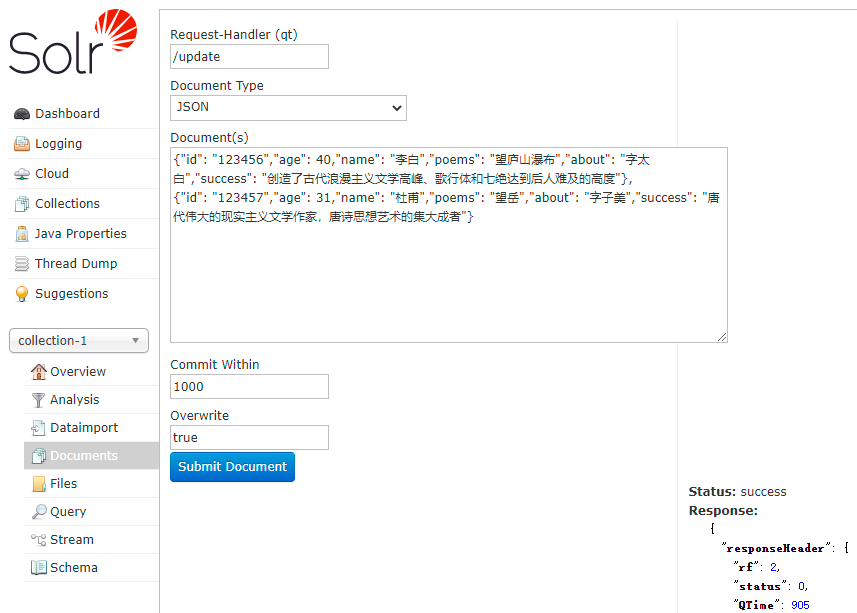
3.3、添加/更新文档
{"id": "123456","age": 40,"name": "李白","poems": "望庐山瀑布","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"},
{"id": "123457","age": 31,"name": "杜甫","poems": "望岳","about": "字子美","success": "唐代伟大的现实主义文学作家,唐诗思想艺术的集大成者"}
3.4、查询文档