一、在进行网络通信时是否需要进行字节序转换?
相同字节序的平台在进行网络通信时可以不进行字节序转换,但是跨平台进行网络数据通信时必须进行字节序转换。
原因如下:网络协议规定接收到得第一个字节是高字节,存放到低地址,所以发送时会首先去低地址取数据的高字节。小端模式的多字节数据在存放时,低地址存放的是低字节,而被发送方网络协议函数发送时会首先去低地址取数据(想要取高字节,真正取得是低字节),接收方网络协议函数接收时会将接收到的第一个字节存放到低地址(想要接收高字节,真正接收的是低字节),所以最后双方都正确的收发了数据。而相同平台进行通信时,如果双方都进行转换最后虽然能够正确收发数据,但是所做的转换是没有意义的,造成资源的浪费。而不同平台进行通信时必须进行转换,不转换会造成错误的收发数据,字节序转换函数会根据当前平台的存储模式做出相应正确的转换,如果当前平台是大端,则直接返回不进行转换,如果当前平台是小端,会将接收到得网络字节序进行转换。
二、大端和小端
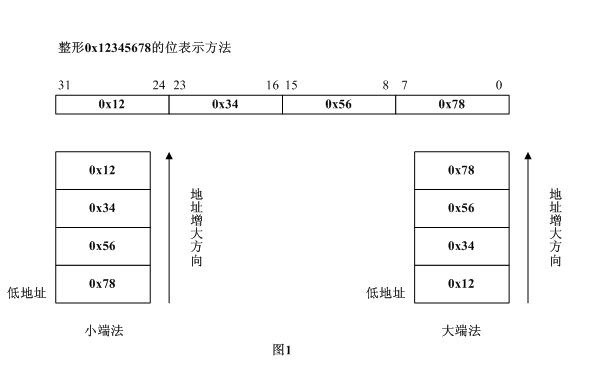
"大端"和"小端"表示多字节值的哪一端存储在该值的起始地址处;小端存储在起始地址处,即是小端字节序;大端存储在起始地址处,即是大端字节序; 或者说: 1.小端法(Little-Endian)就是低位字节排放在内存的低地址端(即该值的起始地址),高位字节排放在内存的高地址端; 2.大端法(Big-Endian)就是高位字节排放在内存的低地址端(即该值的起始地址),低位字节排放在内存的高地址端; 举个简单的例子,对于整型数据0x12345678,它在大端法和小端法的系统中,各自的存放方式如下图1所示:
三、网络字节序
网络上传输的数据都是字节流,对于一个多字节数值,在进行网络传输的时候,先传递哪个字节?也就是说,当接收端收到第一个字节的时候,它将这个字节作为高位字节还是低位字节处理,是一个比较有意义的问题; UDP/TCP/IP协议规定:把接收到的第一个字节当作高位字节看待,这就要求发送端发送的第一个字节是高位字节;而在发送端发送数据时,发送的第一个字节是该数值在内存中的起始地址处对应的那个字节,也就是说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节(即:高位字节存放在低地址处);由此可见,多字节数值在发送之前,在内存中因该是以大端法存放的; 所以说,网络字节序是大端字节序; 比如,我们经过网络发送整型数值0x12345678时,在80X86平台中,它是以小端发存放的,在发送之前需要使用系统提供的字节序转换函数htonl()将其转换成大端法存放的数值
转发自:https://www.cnblogs.com/fuchongjundream/p/3914770.html