一、HDFS的读写机制
1.HDFS的写入流程图

2.详解
首先我要将一个200M文件存到HDFS集群中。
- 客户端通过RPC(远程服务)访问NameNode,请求写入一个文件。
- NameNode检查客户端是否有权限写入,如果有权限返回一个响应。如果没有客户端就会抛出一个异常。
- 客户端会将文件按BlckSize大小(默认128M)将文件切分成一个一个Block块,然后请求写入第一个Block块。
- NameNode会根据它的负载均衡机制,给客户端返回满足其副本数量(默认是3)的列表(BlockId:主机,端口号,存放的目录)。
- 客户端根据返回的列表,开始建立管道(pipeline)。客户端->第一个节点->第二个节点->第三个节点。
- 开始传输数据,Block按照Packet一次传输,当一个Packet成功传输到第一个DataNode上以后,第一个DodaNode就把这个Packet开始进行复制,并将这个Packet通过管道传输到下一个DataNode上,下一个DataNode接收到Packet后,继续进行复制,再传输到下一个DataNode上。
- 当一个Block块成功传输完以后,从最后一个DataNode开始,依次从管道返回ACK队列,到客户端。
- 客户端会在自己内部维护着一个ACK队列,跟返回来的ACK队列进行匹配,只要有一台DataNode写成功,就认为这次写操作是完成的。
- 开始进行下一个Block块的写入。重复3-8。
如果在传输的时候,有的DataNode宕机了,这个DataNode就会从这个管道中退出。剩下的DataNode继续传输。然后,等传输完成以后,NameNode会再分发出一个节点,去写成功的DataNode上复制出一份Block块,写到新的DataNode上。
3.HDFS的读机制流程图
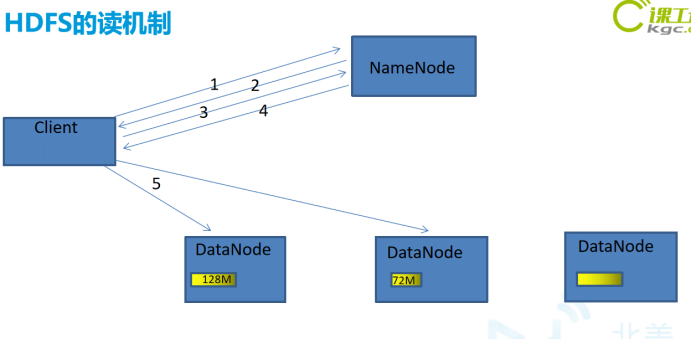
4.详解
- 客户端向NameNode通过RPC发送读请求。
- NameNode确认客户端是否有读权限,如果有,给客户端返回一个响应,如果没有,客户端抛出一个异常。
- 客户端向NameNode请求需要读取的文件。
- NameNode返回存储此文件的每个Block块所在的位置的列表。
- 客户端会从返回的列表中挑选一台最近的,建立连接,读取Block块。读取的时候会将Block块统计目录下的校验信息,一起读取过来。
- 客户端读取完Block块信息以后,会计算出一个校验和跟读取过来的校验和进行对比,如果能匹配上,就说明正确。如果匹配不上,就从其他节点上读取Block块。
二、MapReduce的运行原理
1.流程图
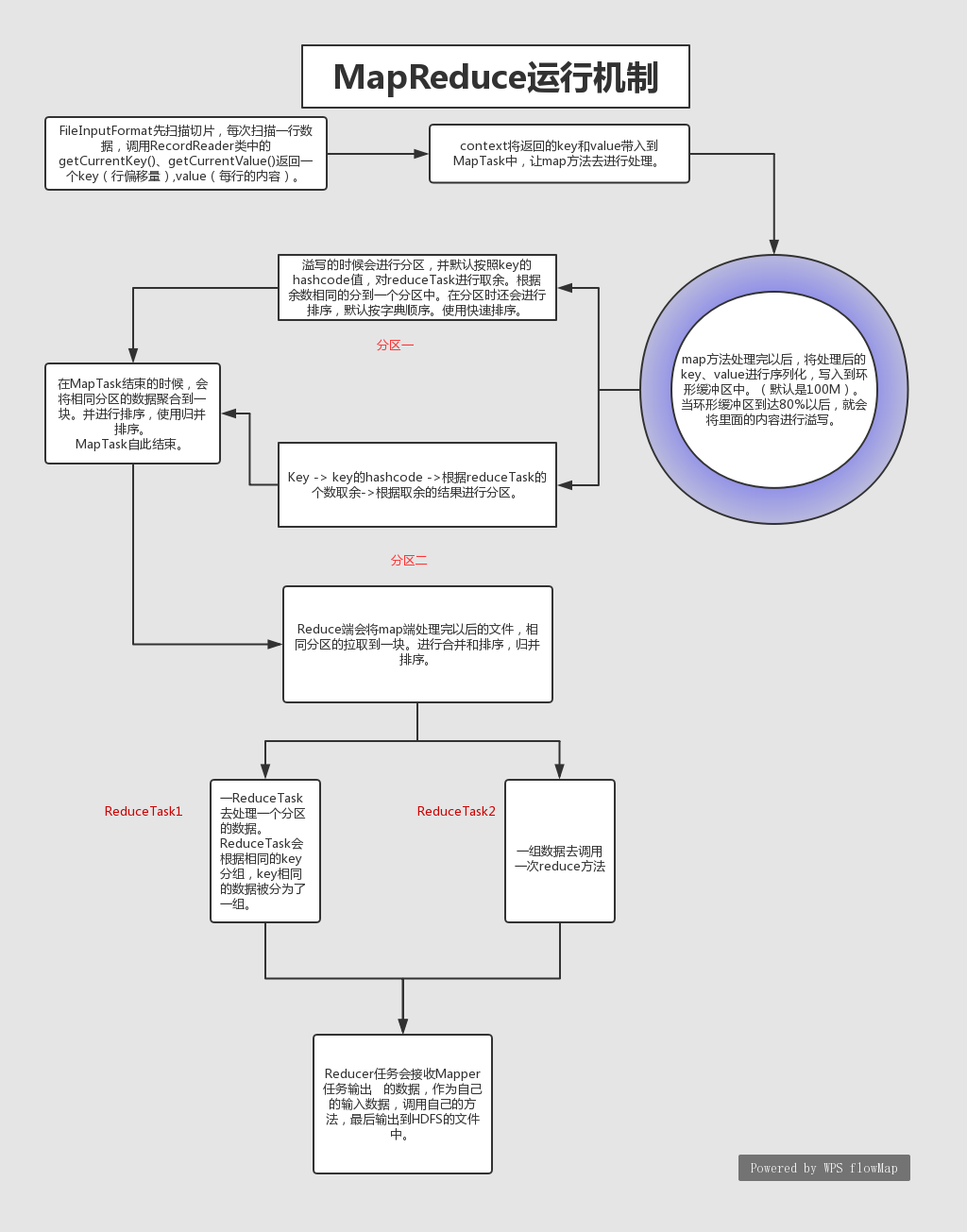
2.详解
1.在HDFS存好文件后,当开始MapReduce的计算时首先通过FileInputFormat先扫描切片,每次扫描一行数据,调用RecordReader类中的getCurrentKey()、getCurrentValue()返回一个key(行偏移量),value(每行的内容)。context将返回的key和value带入到MapTask中,让map方法去进行处理。
切片的计算:long splitSize = Math.max(minSize, Math.min(maxSize, blockSize));每个切片的大小可以自定义但是为了优化效率 默认将切片的大小与HDFS的分割的block的大小一致
2.map方法处理完以后,将处理后的key、value进行序列化,写入到环形缓冲区中。(默认是100M)。当环形缓冲区到达80%以后,就会将里面的内容进行溢写。溢写的时候会进行分区,并默认按照key的hashcode值,对reduceTask进行取余。根据余数相同的分到一个分区中。在分区时还会进行排序,默认按字典顺序。使用快速排序。Key -> key的hashcode ->根据reduceTask的个数取余->根据取余的结果进行分区。
3.在MapTask结束的时候,会将相同分区的数据聚合到一块。并进行排序,使用归并排序。MapTask自此结束。
4.Reduce端会将map端处理完以后的文件,相同分区的拉取到一块。进行合并和排序,归并排序。一个ReduceTask去处理一个分区的数据。
5.ReduceTask会根据相同的key分组,key相同的数据被分为了一组。一组数据去调用一次reduce方法。一个reduceTask处理完以后写入到一个reduceTask文件中。
3.注意事项
1.Shuffle:从数据进入缓冲区开始到reducetask调用reduce方法之前。
三、Yarn的运行原理
1.Yarn的流程图
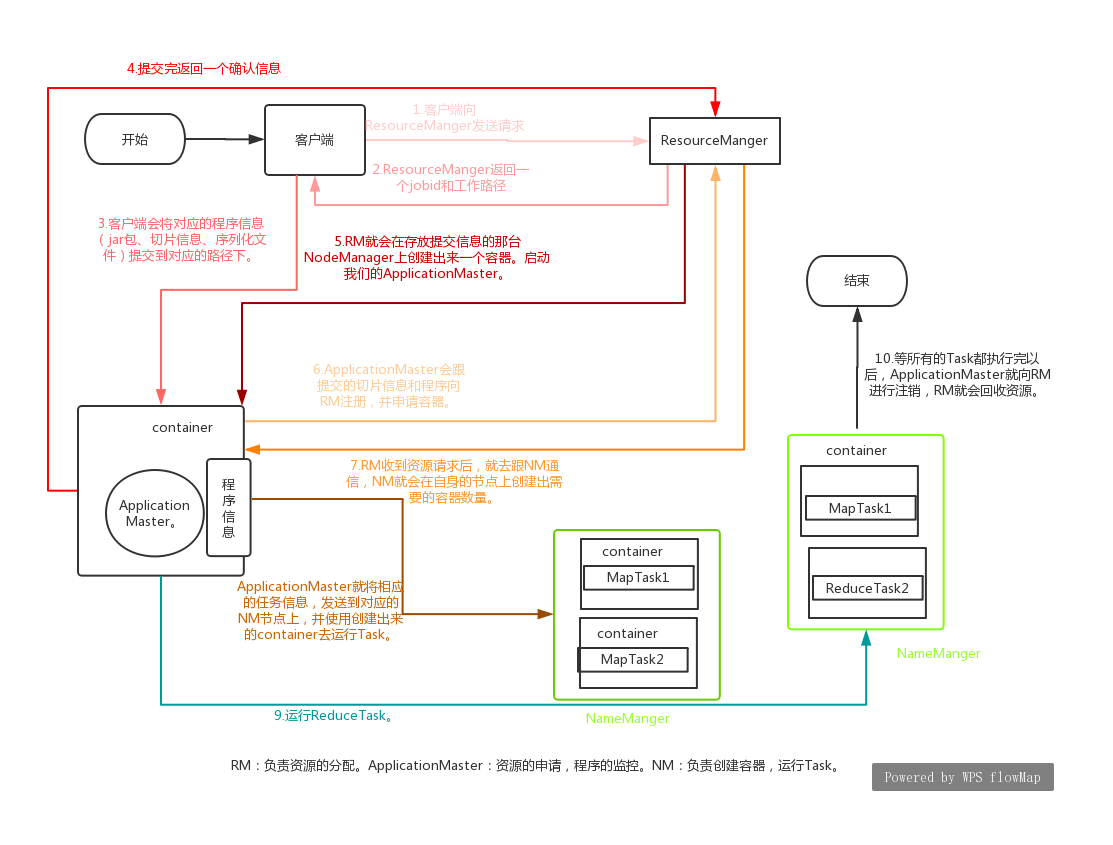
2.详解
-
客户端将它的程序提交给Yarn。
-
RM会给客户端返回一个jobid以及一个路径。
-
客户端会将对应的程序信息(jar包、切片信息、序列化文件)提交到对应的路径下。
-
提交完以后给RM返回一个确认。
-
RM就会在存放提交信息的那台NodeManager上创建出来一个容器。启动我们的ApplicationMaster。
-
ApplicationMaster会跟提交的切片信息和程序向RM注册,并申请容器。
-
RM收到资源请求后,就去跟NM通信,NM就会在自身的节点上创建出需要的容器数量。
-
ApplicationMaster就将相应的任务信息,发送到对应的NM节点上,并使用创建出来的container去运行Task。
-
运行ReduceTask。
-
等所有的Task都执行完以后,ApplicationMaster就向RM进行注销,RM就会回收资源。
-