一、事务
1.事务的概念
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做。
2.事务的特性ACID
A(atomicity):原子性:事务不可被划分,是一个整体,要么一起成功,要么一起失败
C(consistence):一致性,A转100给B,A减少了100,那么B就要增加100,增加减少100就是一致的意思
I(isolation):隔离性,多个事务对同一内容的并发操作。
D(durability):持久性,已经提交的事务,就已经保存到数据库中,不能在改变了
3.事务隔离及产生的问题
跟线程安全差不多,多个事务对同一内容同时进行操作,那么就会出现一系列的并发问题。
3.1、脏读:一个事务读到另一个事务没有提交的数据。
A给B转100块钱(事务A),A在ATM机上转,将100块钱放到ATM机里了,然后ATM机会最后询问A,确定转账100给B吗,A还没点确定这个时候,B在另外一个ATM机上就发现账户上多了100块钱,然后高兴的取走了这100块钱,B取钱(事务B)但是此时A觉得不行,觉得还是拿现金给B比较好,然后就点了取消,把放到ATM机中的100块钱给拿了回来。这其中,A转钱给B(事务A)、B取钱(事务B),也就发生了事务B读到了事务A没有提交的数据,也就是脏读。
3.2、不可重复读:一个事务读到另一个事务已经提交的数据(update更新语句)
解释:有时候不可重复读是一个问题,有时候却不是。这要看业务需求是怎么样的,就好比银行转钱的事情,事务A(A给B转钱),事务B(B取钱),A在ATM机上插卡转钱给B,同时B也将银行卡插入ATM机中准备查看A是否转了钱给B,当A事务结束后,也就是A转账成功后,B就查到了自己账户上多了100块钱,这就是事务B读到了事务A已经提交的数据。这个例子不可重复读就不是个问题。此业务逻辑中,就不需要解决这个问题。在别的业务中,可能这个就是个问题了。比如,一个公司,每个月15号给员工结算工资,工资数是从上个月15号到这个月15号根据每个人提交的工作量来结算的,但是会计师A在这个月15号从数据库中拿每个员工的工作记录量的数据做工资的统计的同时,员工B在次提交了一次工作量(将数据库中B的工作量增加了),此时会计师A在结算员工B的工资时,就会把前面30天的工作量和他今天提交的工作量一起算工资,到了下个月15号,又会把员工B这次提交的工作量算在它当前月的总工作量中,这样一来,就相当于给B多算了一次工作量的工资。这样就不合理了。
2.1.3.4、虚度(幻读):一个事务读到另一个事务已经提交的数据(insert插入语句)
这个跟不可重复读描述的问题是一样的,但是其针对的事务不一样,不可重复读针对的是做更新的事务,比如转钱呀等,都是做更新的事务,而这个虚读针对的是做插入的事务,比如,在工地有很多人做事,工地有规定,做了事的中午才包饭,到了中午的时候,工地负责人要去给做事的工人买盒饭,就要统计人数,现在工地也会用电脑了,负责人就到电脑上查有多少人做事,来决定买多少盒饭,就在查人数的时候,另一个专门招工人的负责人招到一个工人,就把该工人的信息输入到数据库里面,然后买盒饭的负责人在电脑上一查数据库,发现有N个人,刚招进来的工人也在其中,然后就也给那个没做事的,刚招进来的员工买了盒饭,这是不符合规定的。这只是举一个这样的例子,帮助大家理解,一个盒饭也不贵,觉得无所谓,但是如果是涉及很重要的东西时,就不能出现这种问题。
4、事务隔离级别,用于解决隔离问题
.4.1、read uncommitted :读未提交,一个事务读到另一个事务 没有提交的数据,存在问题3个,解决0个问题
4.2、read committed:读已提交,一个事务读到 另一个事务已经提交的数据,存在问题2个,解决1个问题(脏读问题)
4.3、repeatable read:可重复读,一个事务 读到重复的数据,即使另一个事务已经提交。存在问题1个,解决2个问题(脏读、不可重复读)
4.4、serializable:单事务,同时只有一个事务可以操作,另一个事务挂起(暂停),存在问题0个,解决3个问题(脏读、不可重复读、虚读)
注意:一定要搞清楚上面三个问题(脏读、不可重复读、幻读)是什么样的情况,你才能知道这四种隔离级别为什么能够解决这些问题。切记,如果看我的话还是觉得这几个问题模糊不清,就请留言告诉我你的疑问,因为如果不明白这三个问题,那么后面你将一直会混淆。
.5、使用MySQL来进行隔离级别的演示
MySQL默认的隔离级别:repeatable read Oracle默认的隔离级别:read committed
MySQL默认事务提交的,也就是在cmd中每执行一条sql语句就是一个事务,所以如果你要进行实验就必须先关闭MySQL的自动事务提交,并改为手动,set autocommit=0
5.1、read uncommitted
A隔离级别:读未提交,会发生脏读问题
AB同时开始事务,
A先查询 --正常数据
B更新,但未提交
A在查询 --读到B没有提交的数据
B回滚 --B没有提交数据,回滚的话,就相当于刚才的更新语句并没有执行
A再查询 --读到回滚后的数据,也就是原来的正常数据。
5.2、read committed
A隔离级别:读已提交
AB同时开启事务
A 先查询 --正常
B 更新,但未提交
A再查询 --得到的还是之前的数据,并没有拿到B没有提交的数据, 解决问题:脏读
B 提交
A 再查询 -- 已经提交的数据。问题:不可重复读(到这里就不要在纠结为什么不可重复读是个问题了,上面已经解释清楚了,根据不同的业务,可能是问题,也可能不是)
5.3、repeatable read
A隔离界别:可重复读,保证当前事务中读到的是重复的数据
AB 同时开启事务
A 先查询 --正常
B 更新,但未提交
A 再查询 -- 之前数据,解决:脏读
B 提交
A 再查询 -- 之前数据,解决:不可重复读
A 回滚|提交
A 再查询 -- 更新后数据,新事务获得最新数据
5.3、serializable
A隔离级别:串行化,单事务
AB 同时开启事务
A 先查询 --正常
B 更新 -- 等待 (对方事务A结束或者超时B才能进行。)
6、丢失更新问题 lost update
这个丢失更新问题也是属于事物隔离性产生的问题之一,但是不同上面所说的三个,上面所说的脏读、不可重复读、虚读,都是一个事务 拿到了 另一个事务所提交或者未提交的数据而产生的问题,而丢失更新并不拿对方事务所提交的数据,那丢失更新描述的是一个什么样的问题呢?
A 查询数据,username = 'jack' ,password = '1234'
B 查询数据,username="jack", password="1234'
A更新密码,用户名不变 username='jack',password='456' //A将密码更新完后,将其保存到数据库中了
B更新用户名,username='rose',password='1234' //B更新之后,数据库中的数据就为 username='rose',password='1234'
丢失更新:最后更新数据,将前面更新的数据给覆盖了。那A之后就发现自己刚设置的密码登录不上了,这就出现了丢失更新问题,解决的方法有两种
解决方法一:
乐观锁
认为丢失更新一定不会发生,非常乐观,在数据库表中添加一个字段,可以说是标识字段把,用于记录操作次数的,比如如果对有人拿到了该行记录做了更新操作,该字段就加1。然后下一个拿到该记录的人要先将拿到的记录的标识和数据库中该记录的标识做对比,如果一样,则可以修改,并且修改后标识(版本)+1,如果不一样,先从数据库中查询,然后在做更新。举个例子
A 查询数据,username = 'jack' ,password = '1234',version=1
B 查询数据,username="jack", password="1234',version=1 //AB同时拿到数据库中数据,且version读为1
A更新密码,用户名不变 username='jack',password='456',version=2 //先和数据库中该行记录的version做对比,拿到的version是1,跟数据库中一样,所以能做更新,A将密码更新,version+1,然后将其保存到数据库中(注意,这里写的是A更新之后的的数据。 不要搞混了。)
B更新用户名,username='rose',password='1234',version=1 //B想要更新时,先和数据库中该条记录的版本号做对比,发现不一样,然后查询
B重新查询数据, 用户名不变 username='jack',password='456',version=2 //然后在进行对比,这次version一样了,B就可以实现更新操作了。
B更新用户名,username='rose',password='456',version=3 //更新后,version+1
解决方法二:
悲观锁
认为丢失更新一定会发生,此时采用数据库锁机制,也就是相当于谁操作了该记录行,就会在上面加把锁,别人进不去,只有等你操作完之后,该锁就释放,别人就可以操作了。跟那个隔离级别单事务差不多。但是锁也分很多种。
读锁:共享锁,大家可以一起读数据,但是不能一起操作(更新,删除,插入等)
写锁:排他锁,只能一个进行写,也就是上面我们说的原理。
二、hibernate中对事务产生的隔离性问题以及解决方案
上面通过很大的篇幅讲解数据库的事务相关问题,就是为了讲解hibernate中的事务做铺垫,懂了上面这些,那么这里就顺风顺水了。
2.2.1、hibernate中设置事务隔离级别,隔离级别是为了解决事务隔离性产生的问题的。
在hiberante.cfg.xml文件中配置 hibernate.connection.isolation 隔离级别
有四种隔离级别可选择,后面的数字表示在设置隔离级别的时候,直接写数字也是可以代表对应的隔离级别的,比如 hibernate.connection.isolation 4 跟hibernate.connection.isolation Repeatable read 是一样的。
Read uncommoitted isolation 1
Read committed isolation 2
Repeatable read isolation 4
Serializable isolation 8

2.2.2、hibernate中丢失更新问题的解决
悲观锁: 就是认为一定会发生丢失更新问题,采取锁机制
User user = (User) session.load(User.class,1,LockMode.UPGRADE);
乐观锁:
hibernate 为Customer表 添加版本字段
1) 在User类 添加 private Integer version; 版本字段
2) 在User.hbm.xml 定义版本字段
<!-- 定义版本字段 -->
<!-- name是属性名 -->
<version name="version"></version>

如果产生了丢失更新就会报异常
![]()
总结:
1、如果知道了数据库中事务的知识,那么在hibernate中就非常简单,只是简单的配置一下就OK了。所以在hibernate的事务讲解这里篇幅就比较少,重要的还是需要弄懂前面的知识。很重要。
三、spring如何进行事务的管理的理论分析
PlatformTransactionManager:事务平台管理器。
spring管理事务时,必须使用平台事务管理器,它是一个接口,相当于定义一个spring使用事务的规范,也就是如果你想用spring来帮你管理事务,那么就必须遵循这个规范,spring也帮我们实现了一些常用的技术所需要的管理器,比如,jdbc有jdbc管理器,hibernate有hibernate管理器,他们都是实现spring中的PlatformTransactionManager接口的。
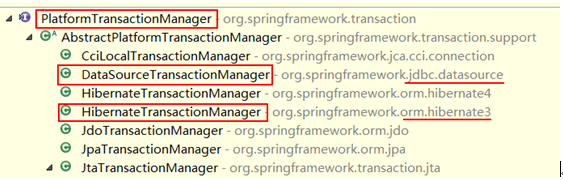
jdbc事务管理器:DataSourceTransactionManager
hibernate事务管理器:HibernateTransactionManager
PlatformTransactionManager是一个接口,那我们看它定义了哪些方法供我们使用的。
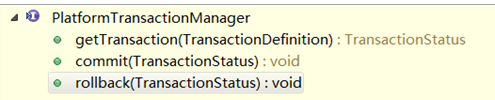
TransactionStatus getTransaction(TransactionDefinition);
获取事务,参数TransactionDefinition(事务详情),该参数是需要我们配置的,通过我们配置的内容才能知道事务如何去处理。这个下面会详解
commit(TransactionStatus);
根据状态来提交事务的操作
rollback(TransactionStatus);
根据状态来回滚事务的操作
TransactionStatus
spring使用管理器,通过状态对事务进行管理(操作),我们不必关心这个,因为这是spring内部操作的事情,但是我们可以了解一下有哪些方法

TransactionDefinition
spring管理器必须通过"事务详情"的设置,获取相应的事务,从而进行事务管理。这里这个很重要,我们需要配置这个

设置4个隔离级别就不用说了把,跟上面我们说的是一样的。解决隔离问题的四种级别。
传播行为:一个业务A,一个业务B,AB如何共享事务,不同传播行为共享方案不同。
什么意思呢?比如业务A为银行转账的业务。 业务B为转完账发短信的业务,平常我们是转完钱,那么我们就需要收到短信说我们的账户上被转走多少钱,而收钱的那一方则需要收到短信说账户被转进多少钱,那么这两个业务是使用同一个事务呢?还是分别使用不同的事务,也就是如果是使用同一个事务的话,我们转钱成功了代表业务A成功了,但是业务B发送短信时出现问题,则说明该事务失败,那么刚才转的钱就算不成功,需要回滚,但是实际生活中,是不能这样的,转钱成功了,短信没发送成功,那么短信在重新发送一次即可。不需要让业务A重新在操作一遍。这就是业务A和业务B共享事务的解决方法,让他们两个使用各自的事务。而传播行为就是提供这样的共享方案的属性。
传播行为方案
1.PROPAGATION_REQUIRED ,required ,必须使用事务 (默认值)
A 如果使用事务,B 使用同一个事务。(支持当前事务)
A 如果没有事务,B将创建一个新事务。
2.PROPAGATION_SUPPORTS,supports ,支持事务
A 如果使用事务,B 使用同一个事务。(支持当前事务)
A 如果没有事务,B 将以非事务执行。
3.PROPAGATION_MANDATORY,mandatory 强制
A 如果使用事务,B 使用同一个事务。(支持当前事务)
A 如果没有事务,B 抛异常
4.PROPAGATION_REQUIRES_NEW , requires_new ,必须是新事务
A 如果使用事务,B将A的事务挂起,再创建新的。
A 如果没有事务,B将创建一个新事务
5.PROPAGATION_NOT_SUPPORTED ,not_supported 不支持事务
A 如果使用事务,B将A的事务挂起,以非事务执行
A 如果没有事务,B 以非事务执行
6.PROPAGATION_NEVER,never 从不使用
A 如果使用事务,B 抛异常
A 如果没有事务,B 以非事务执行
7.PROPAGATION_NESTED nested 嵌套
A 如果使用事务,B将采用嵌套事务。
嵌套事务底层使用Savepoint 设置保存点,将一个事务,相当于拆分多个。比如业务A为AB两个曹祖,业务B为CD两个操作,业务AB使用同一个事务,在AB (POINT) CD,当业务B失败时,回滚到POINT处,从而业务A还是成功的,就是保持点的操作。
底层使用嵌套try方式
掌握:PROPAGATION_REQUIRED、PROPAGATION_REQUIRES_NEW、PROPAGATION_NESTED
总结:
spring事务编程的步骤
1、确定管理器
2、必须配置事务详情(是否只读,隔离级别,传播行为等)
配置好了事务详情,也确定了使用哪个管理器,那么spring就知道如何对事务进行怎样的处理了。
四、spring使用AOP技术来进行事务操作(基于xml)
上面我们知道了spring使用事务需要哪些东西,但是单纯的使用上面这些编写事务,那我们对每个需要使用事务的方法都需要写代码,岂不是累死,但是结合前面学习的AOP思想,就简单很多了。
重点看配置


重点看47到59行的代码,配置事务管理器和事务详情,然后通过aop将我们的事务应用到指定的切入点上去,使用的是表达式。指定一个范围。其中,事务详情和事务管理器的结合就相当于通知(加强的方法),所以菜在通知引用上可以写上exAdvice。这点必须想清楚。也就是我们都不需要自己手动写什么开启事务等代码,spring全帮我们写好了,我们只需要配置一下事务详情即可。
需要注意一点,因为使用的是spring内置的aop,没有使用AspectJ框架,所以如果没有使用接口,那么就需要写56行这行代码,如果使用了接口,那么就不需要写。需要通知spring使用cjlib代理
事务详情的配置

这样设置的话,就可以对不同的方法进行不同的事务处理了,很方便。比如add*,意思是add开头的方法,就使用传播行为为REQUIRED的事务进行处理,而find*,find开头的方法只能读,并且传播行为为REQUIRED。
五、spring使用AOP技术来进行事务操作(基于注解)
超级简单。三步
1、声明事务管理器
2、将事务管理器交予spring
前两步是在xml中写的

3、在目标类或方法上 使用注解即可 @Transactional
使用@Transactional(编写事务详情)
![]()
转发自http://www.cnblogs.com/whgk/p/6638192.html
http://www.cnblogs.com/whgk/p/6182742.html