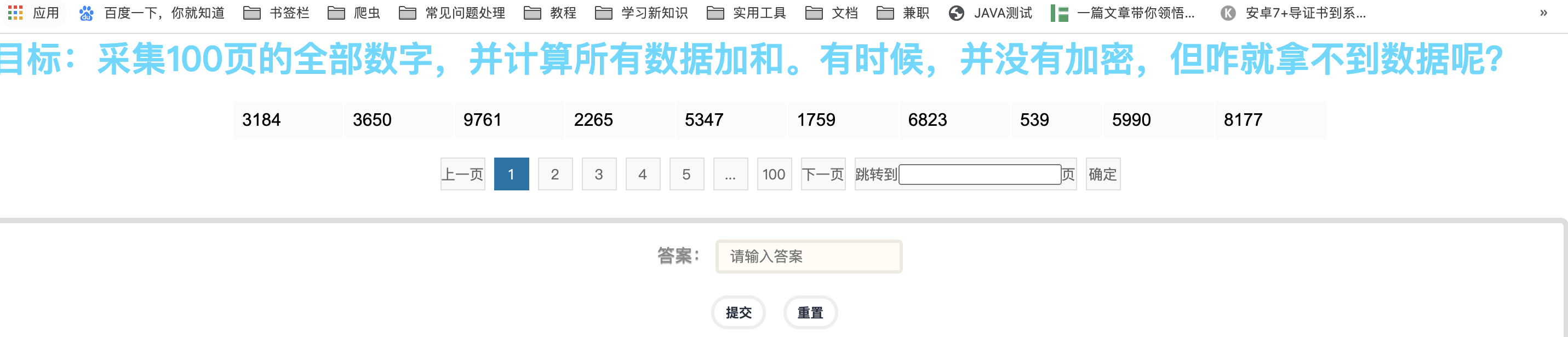
像这一题
我们正常使用charles访问网页是能正常拿到数据的
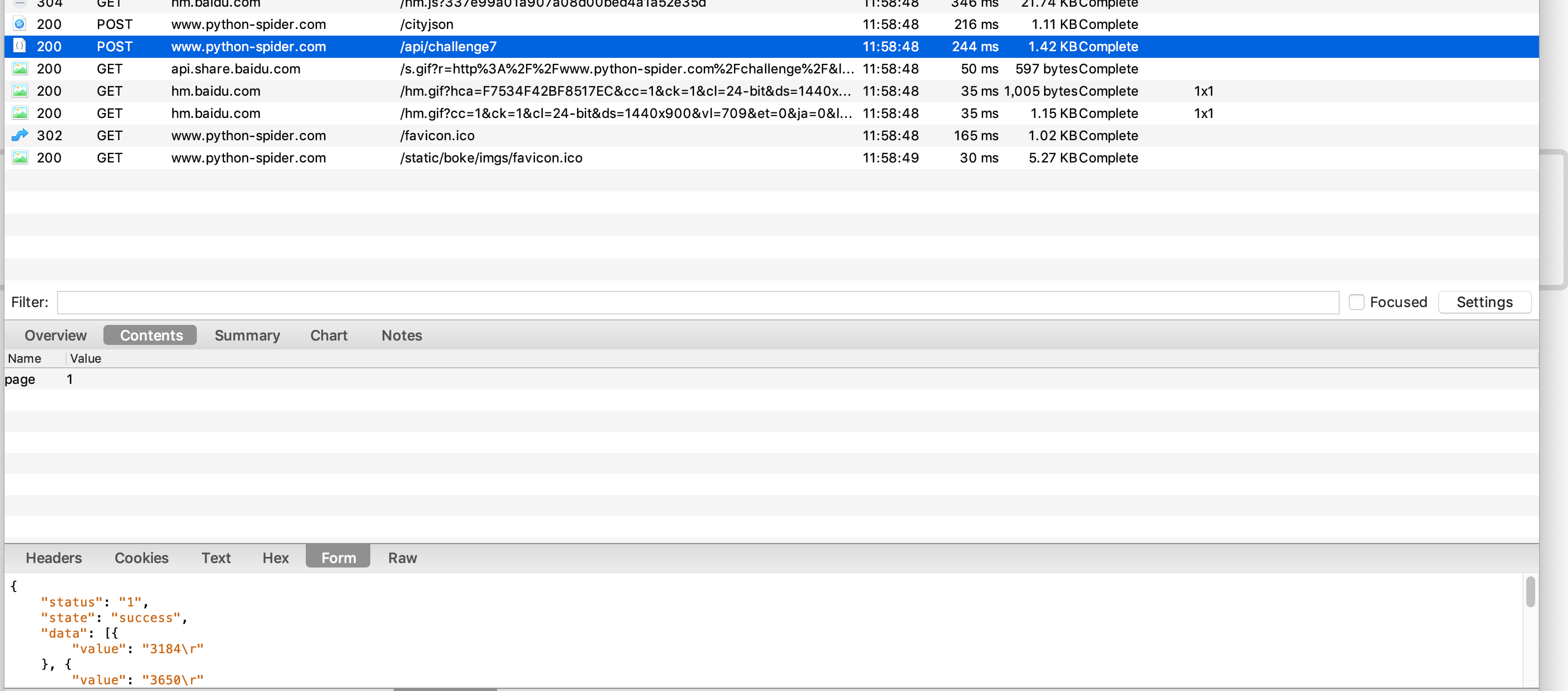
但是我们使用爬虫抓取的时候发现并没有得到自己想要的数据.像这样

于是我们对该网页进行重放攻击
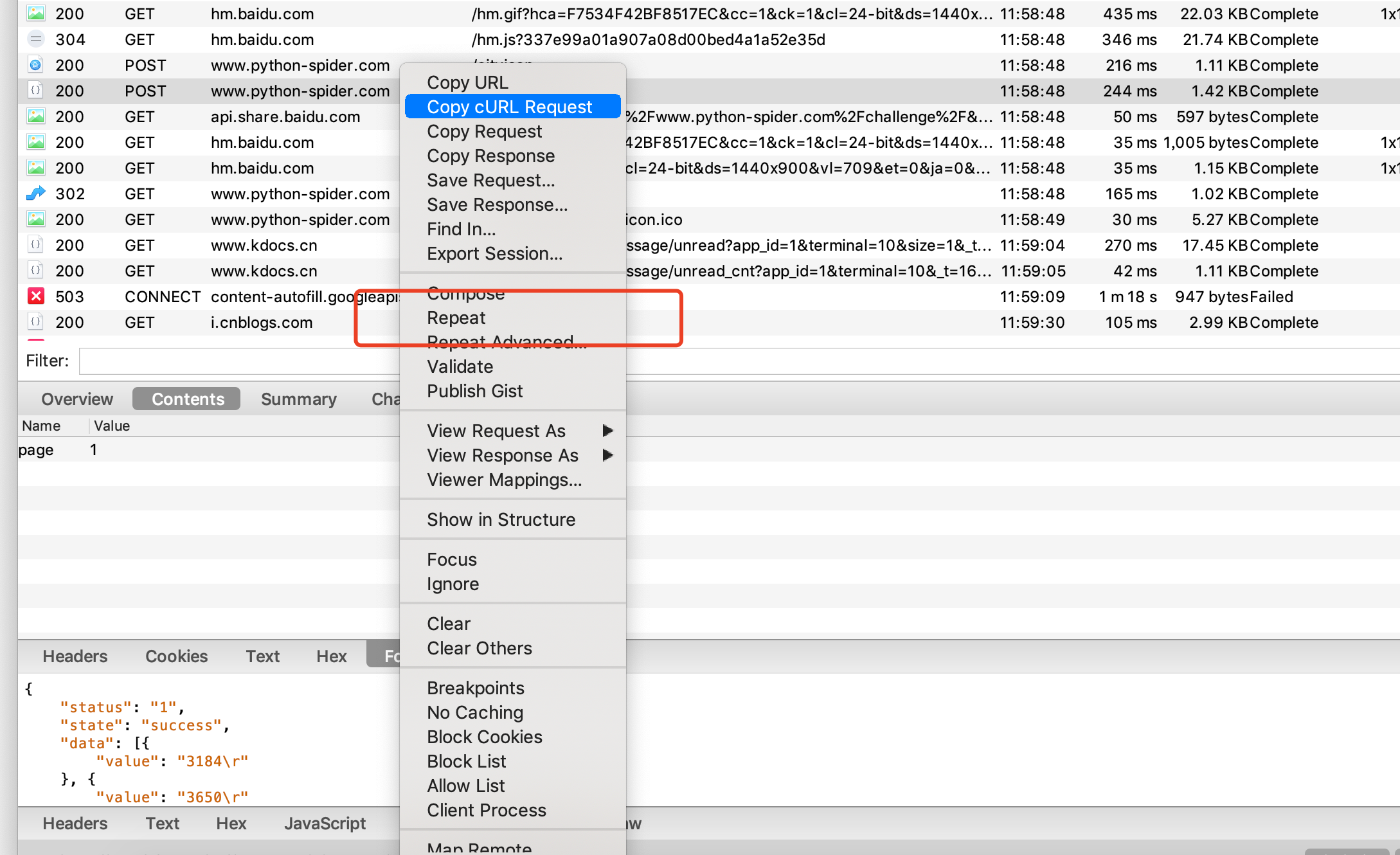
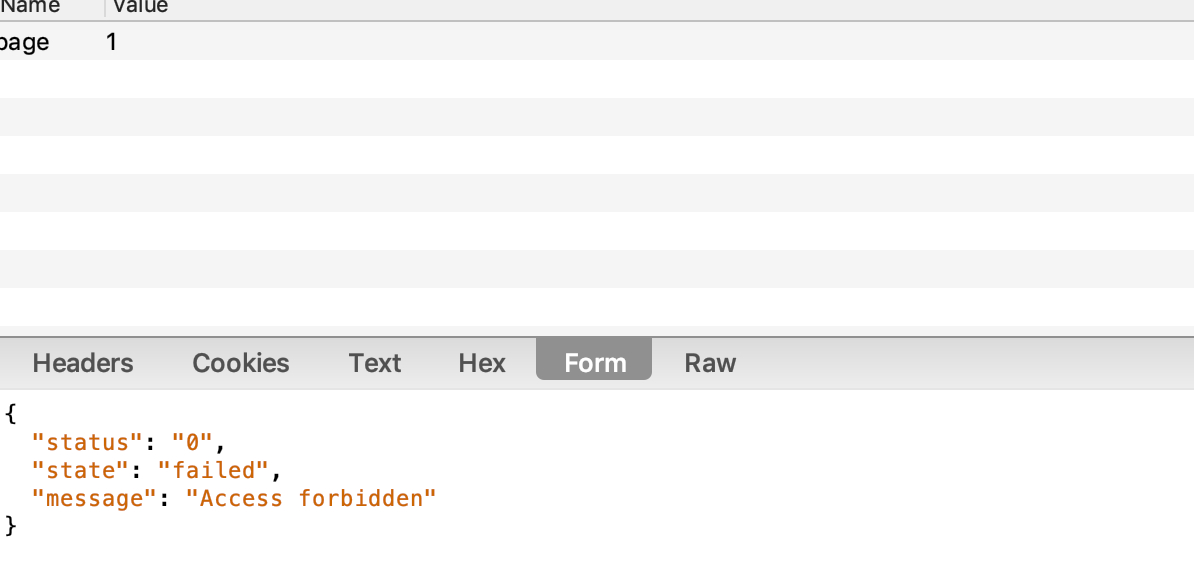
得到对网页像这样,和爬虫得到对数据是一样的
我们在刷新查看 ,发现每次在加载之前,网页还会加载另外一个html
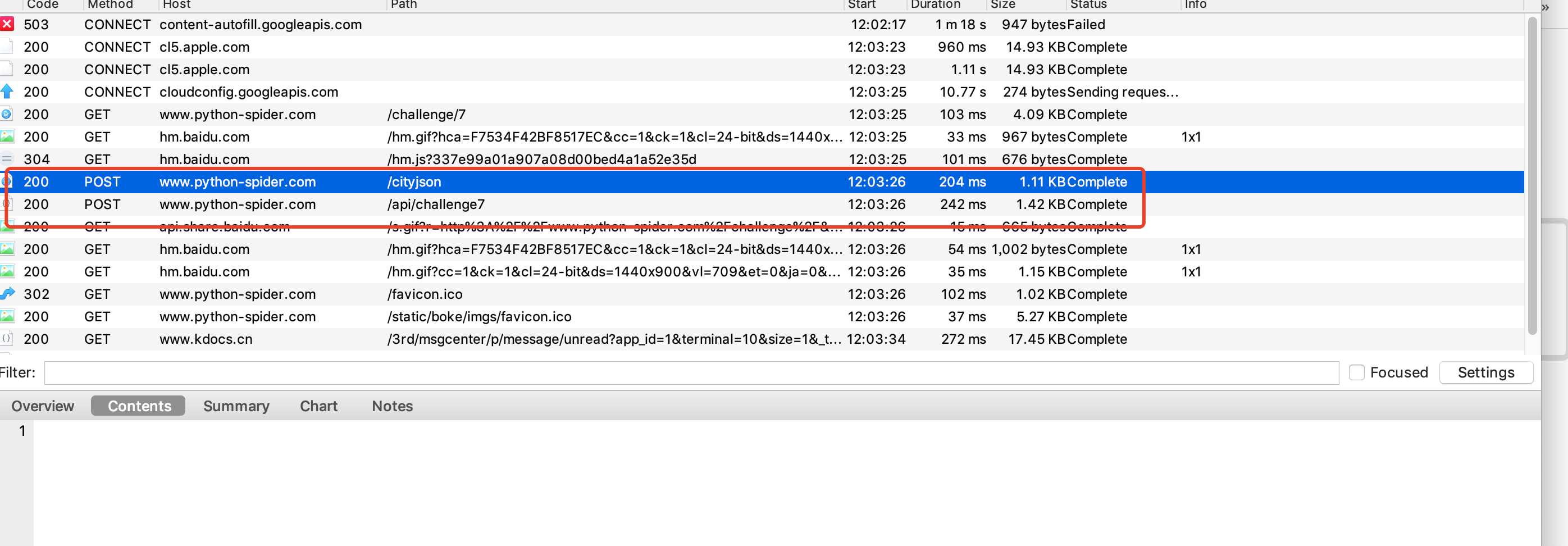
我们猜想是不是必须要现加载这个之后才能正常加载需要对网页呢。,现在对另一个url 进行重放攻击,重放攻击后在对需要对网页进行重放攻击,查看结果
最后发现得到的参数和自己想要的是一样的,猜测正确,现在需要爬虫代码
# import requests
import time
# cookies = {
# 'Hm_lvt_337e99a01a907a08d00bed4a1a52e35d': '1612403505,1614750119,1614845635',
# 'no-alert': 'true',
# 'sessionid': '40i9rwbomm53y06qvx3pom4qjz66goog',
# 'sign': '1614869444070~2481b44694ab8c3d2192a13d854868d1',
# 'Hm_lpvt_337e99a01a907a08d00bed4a1a52e35d': '1614870815',
# }
# session=requests.session()
# headers = {
# 'Host': 'www.python-spider.com',
# 'Accept': 'application/json, text/javascript, */*; q=0.01',
# 'X-Requested-With': 'XMLHttpRequest',
# 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
# 'Origin': 'http://www.python-spider.com',
# 'Referer': 'http://www.python-spider.com/challenge/10',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# }
# session.headers=headers
# data = 'page=1'
#
# response = requests.post('http://www.python-spider.com/api/challenge10', cookies=cookies, data=data)
# print(response.text)
class A():
def __init__(self):
pass
def get(self,data):
import requests
cookies = {
'Hm_lvt_337e99a01a907a08d00bed4a1a52e35d': '1612403505,1614750119,1614845635',
'no-alert': 'true',
'sign': '1614869444070~2481b44694ab8c3d2192a13d854868d1',
'_i': 'MTYxNDg2OTQ0ND$3MH4yNDgxYjQ0Njk0YWI4YzNkMjE5MmExM2Q4NTQ4NjhkMQ',
'_v': 'TVRZeE5EZzJPVFEwTkQkM01INHlORGd4WWpRME5qazBZV0k0WXpOa01qRTVNbUV4TTJRNE5UUTROamhrTVE',
'sessionid': 'kedr8ad9jrl4cgh71peu4zhkwixjaw2n',
'Hm_lpvt_337e99a01a907a08d00bed4a1a52e35d': '1614917004',
}
headers = {
'Host': 'www.python-spider.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36',
'Accept': '*/*',
'Origin': 'http://www.python-spider.com',
'Referer': 'http://www.python-spider.com/challenge/7',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
response = requests.post('http://www.python-spider.com/cityjson', headers=headers, cookies=cookies)
cookies1 = {
'Hm_lvt_337e99a01a907a08d00bed4a1a52e35d': '1612403505,1614750119,1614845635',
'no-alert': 'true',
'sign': '1614869444070~2481b44694ab8c3d2192a13d854868d1',
'_i': 'MTYxNDg2OTQ0ND$3MH4yNDgxYjQ0Njk0YWI4YzNkMjE5MmExM2Q4NTQ4NjhkMQ',
'_v': 'TVRZeE5EZzJPVFEwTkQkM01INHlORGd4WWpRME5qazBZV0k0WXpOa01qRTVNbUV4TTJRNE5UUTROamhrTVE',
'sessionid': 'kedr8ad9jrl4cgh71peu4zhkwixjaw2n',
'Hm_lpvt_337e99a01a907a08d00bed4a1a52e35d': '1614916609',
}
headers1 = {
'Host': 'www.python-spider.com',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Origin': 'http://www.python-spider.com',
'Referer': 'http://www.python-spider.com/challenge/7',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
response1 = requests.post('http://www.python-spider.com/api/challenge7', headers=headers1, cookies=cookies1,
data=data)
html=response1.json()['data']
data_List=[]
for i in html:
value=int(i['value'])
print(value)
data_List.append(value)
return sum(data_List)
def run(self):
dd_list=[]
for page in range(1, 101):
data = 'page={}'.format(page)
dd=self.get(data=data)
time.sleep(0.5)
print(dd)
dd_list.append(int(dd) )
print(sum(dd_list))
if __name__ == '__main__':
s=A()
s.run()
