论文来源:https://arxiv.org/abs/1704.05194v1
阿里技术:https://mp.weixin.qq.com/s/MtnHYmPVoDAid9SNHnlzUw?scene=25#wechat_redirect
写在前面的观后感:该篇论文是阿里妈妈提出来的MLR模型,总体感觉不到什么新意啊,也就是分段线性+级连(级连的部分貌似那篇论文没有说,阿里技术那里面说了)
貌似理论上百度凤巢的ctr比较牛吧,看网上说是lr,gbdt,fm,dnn一起“乱搞”,腾讯我实习的部门貌似现在还是LR+gbdt,其实我在的时候它们还只是分开试验,LR+gbdt都没有做
Introduction
LR模型不能处理非线性特征,所以需要特征工程去加入非线性特征
基于树的模型虽然能够引入非线性特征,但是不适合非常稀疏高纬度的特征
FM模型虽然能够解决高维稀疏且非线性的问题,但是FM不能适应所以的非线性模式(如更高纬度的)
采用分而治之的思想,首先将特征分成几个区域,然后在每个区域里面添加一个线性模型:
Large Scale Piecewise Linear Model (LS-PLM). LS-PLM follows the divide-and-conquer strategy, that is, first divides the feature space into several local regions, then fits a linear model in each region,
LS_PLM算法的优点:
-
非线性 :分成足够的区域,能够拟合任何复杂的非线性函数
- 可扩展性:分布式训练,能够处理高维大数据
- 稀疏性:LS_PLM在L1,L2正则下能够达到很好的稀疏性
LS_PLM是一个非凸不可微的优化问题,该论文采用了直接求导和quis_newton方法求解

给了这张图,来说明LS_PLM模型能够捕捉数据非线性分布(话说LR引入非线性核函数也是可以解决的啊,卧槽
Method
模型公式: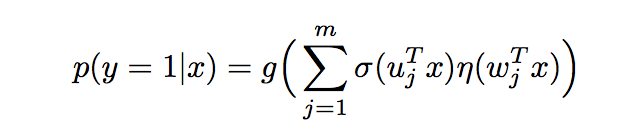
g是最后用于求概率的函数,分成两部分:一、delta是分成到不同region的函数 二、eta是线性模型函数
假设g(x)=x,一是softmax,eta是sigmoid,那么上面的式子就可以变成
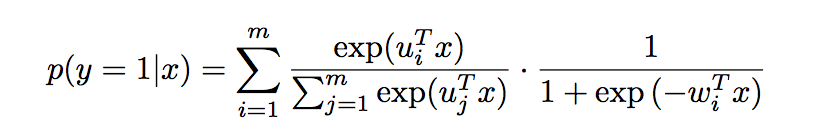
进一步
损失函数加上正则化后也就可以定义为:

后面的优化就不说了
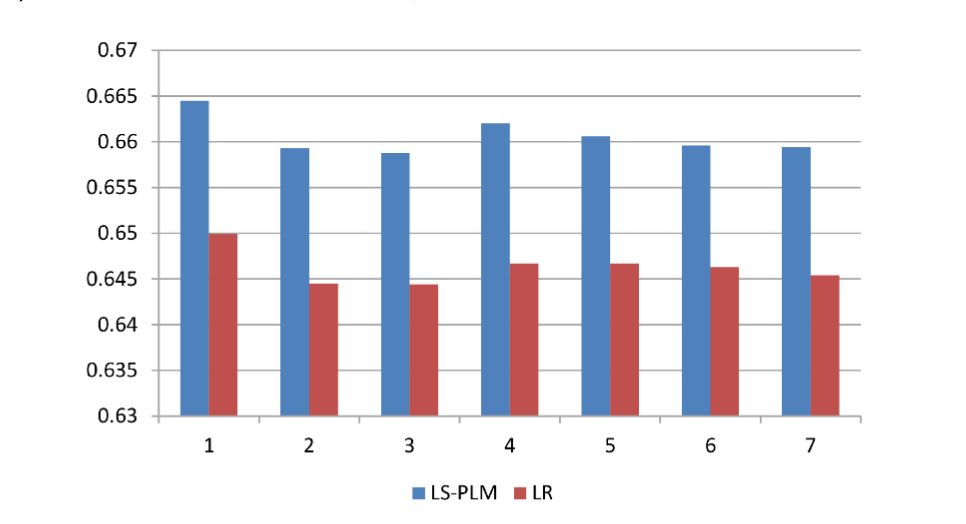
试验结果: