强化学习传说:第五章 基于模型的强化学习
无模型的方法是通过agent不断探索环境,不断试错,不断学习,因此导致了无模型的方法数据效率不高。而基于模型的方法则相反,它能够充分利用已有的模型,高效地利用数据。
简单的思路:
先训练得到环境模型,再利用规划求解。但是本来专家算法就是这么做的。
但是可以考虑基于模型的方法,缩少训练时间,因为环境可以快速给出结果,但是积分本身应该也挺快的。
- 通过某种策略\(\pi (a_t|s_t)\)例如随机策略来获取大量数据\(D=((s_t,a_t)s_{t+1})\)
- 学习一个模型\(f(s_t,a_t)\)来最小化误差\(\sum \left \| f(s_t,a_t)-s_{t+1} \right \|^2\)
- 运用模型\(f(s_t,a_t)\)来进行计划
- 执行计划获得新数据,并将新数据加入到D中回到步骤2
注意这个方法和DAgger的不同:这里我们的目标是学习模型,而DAgger是学习策略。
Model Predictive Control
每次我们只执行计划中的第一步来获取新的数据。
基于模型的强化学习(一)
model based RL主要可以分为四种方法:
- Dyna-style methods
- Dyna类的方法的特点是可以将Model free的方法和world model结合,world model可以提供大量的模拟数据给model free的算法进行对policy的学习,属于一种显式的策略训练方法;
- Analytical gradient
- Analytical类的方法的特点是利用了模型产生数据的可微性(differentiability),直接对trajectory的return进行优化来对策略进行训练;
- Planning
- Planning类的方法是不显式的对策略进行训练,而是基于world model用简单的规划方法得到一系列动作,能够快速的迁移到相似的任务场景上;
- Model-based value expansion
- 通过对动作价值或者状态价值更好的估计来减小world model和真实环境中的误差,能够控制模型的使用来平衡偏差和方差。
Dyna-style Methods
使用world model在各个状态基于预测想象,来得到智能体与环境的交互数据,尽管由于模型和真实环境有一定偏差,但是这个交互数据依然有相当的可信度能够用来充当强化学习算法的训练数据。
这种方式能很好的补充model free方法中策略训练所需要的数据,减少与真实环境的交互和成本,提高sample efficiency。
MBPO(Model Based Policy Optimization)
根据对模型error的估计和,通过控制模型rollout的长度来有限度的使用环境model,最大化的利用学到的环境model。
作者实验发现single-step model rollouts的效果是最好的。
AMPO(Adaptation Augmented Model-based Policy Optimization)
针对环境模型的model error带来的distribution mismatch,有较多工作来解决:
第一类是从环境模型的训练学习(Model Learning)本身提升,比如不同的网络架构或者损失函数来缓解overfitting或者提升multi step prediction来让环境模型与真实环境更加相似;
第二类是从环境模型的使用(Model Usage)着手,根据环境模型离真实分布的偏离程度,来控制对环境模型的使用程度。
提出unsupervised model adaptation来找到真实数据和虚拟想象数据中的不变量表征,鼓励学到两种数据中更加一致的特征,产生虚拟数据时能预测的更准确,缓解model bias,从而提升了性能表现。
基于模型的强化学习(二):Model-based Value Estimation
Model-based value estimation(MVE)
通过仅将利用 model 的 imagination 保持在fixed length来控制 model 的不确定性。使用 learned model 来估计 short-term horizon,用传统的 Q-learning 估计 long-term horizon。并将二者结合起来,实现 data-efficient。
Stochastic Ensemble Value Expansion (STEVE)
STEVE提出的改进就是在不同长度的 H 使用动态插值的办法,使用emsemble替换模型和Q函数,用emsemble样本的方差估计不确定性。(用多个模型来计算轨迹的经验均值和方差)。
Dynamic-horizon Model-based Value Estimation(DMVE)
作者想改进的点就在于,根据不同的 \(s_t\)来挑选不同的H。
作者引入多一个超参数 K ,来选取top K个值估计更准确的后续状态 \(s_{t+h}\) ,求均值来作为最终value estimation对当前状态 \(s_t\) 的值估计,只能说删除了一些rollout过程中明显不准确的后续state,在有限H步的rollout length中进一步筛到较准确的K个后续状态来代表当前状态。
基于模型的强化学习方法学习得到的模型有哪些,具体形式是什么?
包括CEM和MCTS在内的这种采样路径然后通过选择动作或者说策略来得到最优路径的方法在控制领域称为打靶法(shooting method)。
一种避免模型预测误差的方式是不明确使用模型预测,而是使用模型的梯度。
- SVG(Stochastic Value Gradients, 2015)。状态价值的时间差分估计与下一状态价值相关,而下一状态价值可用模型和策略表示,于是在模型对状态和动作可微时,状态价值的梯度可以表示为模型梯度和策略梯度的函数。
- MVE(Model Value Expansion, 2018)。模型的预测能够提供更遥远的状态动作价值(Q值)估计,于是基于单步预测更新的Q值能够使用多步的预测,从而带来更准确的估计。
- STEVE(Stochastic Ensemble Value Expansion, 2019)。在MVE基础上加入了模型集成,用于估计模型的不确定性。
另一种避免直接使用模型预测的方式是使用模型在各状态基于预测想象得到智能体与环境的交互数据,用于充当无模型强化学习算法额外的训练数据(Dyna-style)。
- Dyna:将用模型生成想象的数据用于无模型算法训练的算法称为Dyna系算法。还有个名字很像的算法叫DAgger,基于模仿学习中对每次策略采样数据进行人工重标记的思想。
- ME-TRPO(Model Ensemble Trust-Region Policy Optimization, 2018)。使用模型集成来得到模型的不确定性,这样模型生成的数据就有了重要与不重要之分,从而降低模型预测误差的影响。
- MBPO(Model-Based Policy Optimization, 2019)。同样使用模型集成估计不确定性,建模输出高斯分布,模型基于真实采样数据中的状态进行有限步长的预测,然后使用这些一定步长的预测数据作为想象数据与真实交互数据共同训练无模型RL算法。
- AMPO(Adaptation augmented Model-based Policy Optimization, 2020)。这篇是给模型学习过程加入了一项正则约束,鼓励模型去学习那些想象数据和真实数据更一致的特征,也就是说鼓励模型去学习模型更容易想象出来的场景,减少了模型不分主次学习场景的负担。
在RL中,学习模型的最终目的还是为了求策略。所以涉及到怎么用模型的问题。一般就是利用模型来做规划。当然也可以把模型嵌入到策略中来直接求策略。
2021:Model-based Reinforcement Learning: A Survey.
规划(planning)方法之间的一个重要区别是它们是否需要模型的可微性:
类型:
- 离散任务规划
- 可微规划:
- 如果转移模型和奖励模型是可微的,并且我们指定了可微的策略,那么我们可以直接取累积奖励目标相对于策略参数的梯度。因此,基于模型的RL可以突然利用微分规划方法,利用所学模型的可微性。注意,可微模型也可以从物理规则中获得,例如在可微物理引擎中。
- 使用差分规划的基于模型的 RL 的成功示例是 PILCO,它通过高斯过程动力学模型进行微分,以及 Dreamer 和时间段模型,它通过(潜在)神经网络动力学模型进行微分。
- Dreamer就是把在模型中学到的样本加入buffer中。
规划的方向:前向模拟、反向(s′ → s, a),其中规划算法遵循估值变化最大的方向。最近,用神经网络近似的方法研究了高维问题中的逆向模型。
广度和深度:对于无模型 RL 方法,宽度并不是真正需要考虑的因素,因为我们只能在一个状态下尝试单个动作(宽度为一个)。然而,根据定义,模型是可逆的,我们现在可以自由选择并自适应地平衡计划的广度和深度。
广度:
- Breadth = 1:Dyna,采样的额外一步数据用于无模型Q-learning
- Breadth = adaptive:许多规划方法自适应地衡量规划的广度。 当然,问题是我们不能进行全广度和全深度的搜索,因为穷举搜索在计算上是不可行的。一种自适应扩大搜索广度的方法是,例如蒙特卡罗树搜索(Browne et al., 2012),通过置信上限公式。
- Breadth = full:最后,在考虑更深层次的搜索之前,我们当然可以全面探索行动空间。很少采用。
深度:
- Depth = 1:Dyna
- Depth = intermediate(适当的):当然,我们应该注意,更深的轨迹不会偏离模型准确的区域。
- Depth = adaptive:MCTS tree,深度与宽度相结合
- Depth = full:这种方法对模型中的轨迹进行采样,直到一个episode终止,或者直到一个大范围。
但是,本次调查的重点是规划和学习的结合,而不是实际的规划方法本身。
从基于模型的 RL 的角度来看,关键的实现是,与无模型 RL 相比,我们可以突然使用大于 1 的宽度。然而,许多基于模型的RL方法仍然选择在其模型样本中坚持1的宽度,可能是因为这提供了与无模型更新的无缝集成。
处理不确定性:
- Data-close planning:第一种方法是确保规划迭代接近于我们实际观察到数据的区域。例如,Dyna 在之前访问过的状态的位置对开始状态进行采样,并且只对一步转换进行采样,这样可以确保我们不会偏离状态空间的已知区域。其他方法,如Guided Policy Search (Levine和Abbeel, 2014),明确地限制新计划与当前策略接近。
- Uncertainty propagation:我们也可以明确地估计模型的不确定性,这允许我们在长期的范围内进行稳健的计划。
- Parametric:这种传播方法在每个时间步长的不确定性上都符合一个参数分布。然而,解析参数传播对于更复杂的模型是不可能的,例如神经网络。PILCO
- Sample-based:Deep PILCO(2016)、PETS
我们也可以使用不确定性来确定价值估算的深度。随机集合值扩展(STEVE) (Buckman et al., 2018)根据不同深度的值目标的相关不确定性重新加权,该不确定性来自于值函数和过渡动力学的不确定性。因此,我们将我们的价值评估建立在那些具有最高可信度的预测之上。
How to integrate planning in the learning and acting loop?
Planning input from learned functions
- Value priors:The most common way to incorporate value information is through
bootstrapping. - Policy priors:
引导策略搜索 (GPS) (Levine and Koltun, 2013) 会惩罚新规划的轨迹,因为它与当前策略网络生成的轨迹偏离太多。
最后一个例子是,Guo等人(2014)让当前的政策网络决定在哪个位置执行下一个搜索,即政策网络影响作为规划起点的状态分布。
Planning update for policy or value update:
基于模型的RL方法最终寻求最优值或策略函数的全局逼近。规划结果可用于更新这种全局近似。
Value update:
Policy update:
Planning output for action selection in the real environment:
有些方法只将规划用于行动选择,而不是用于价值/策略更新。
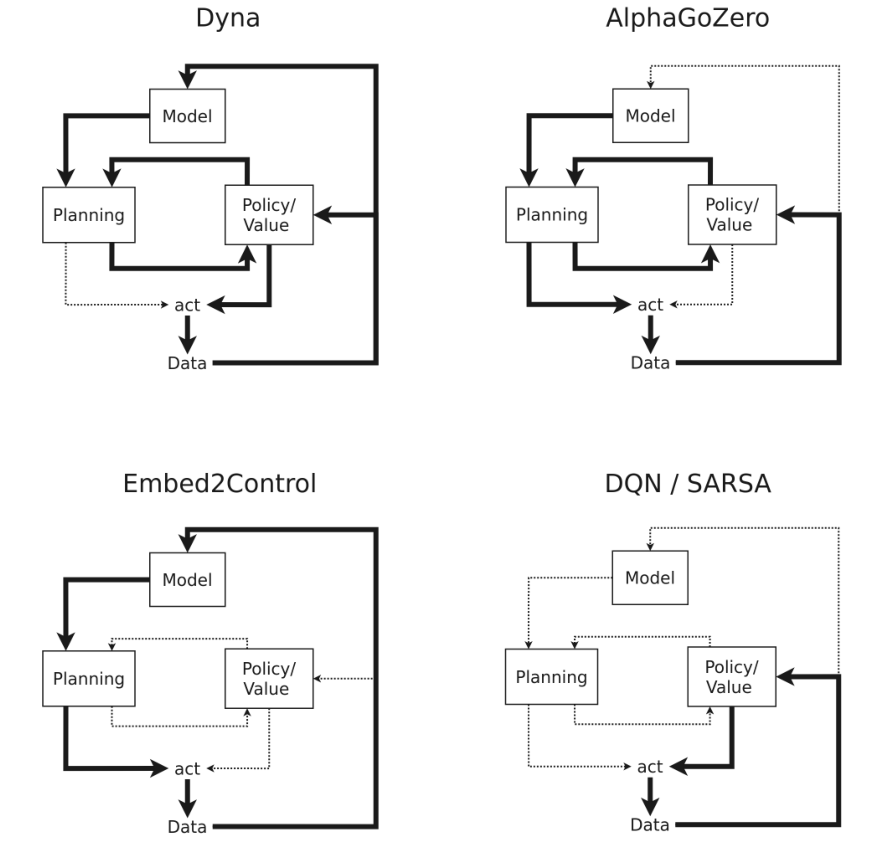
Implicit Model-based Reinforcement Learning(隐式基于模型的强化学习)
关于上述过程的一个有趣观察是,尽管我们可以手工设计基于模型的RL算法的各个方面,但我们最终只关心一件事:确定(最优)值或策略。换句话说,整个基于模型的RL过程(模型学习、计划,以及可能的值/策略逼近的整合)可以从外部被视为一个无模型的RL问题。最终,我们希望我们的整个系统能够预测一个(最优)操作或值。
这种直觉将我们引向基于隐式模型的RL领域。所有这些方法的共同思想是采用基于模型的RL过程的一个或多个方面,并为最终目标优化这些方面,即(最优)值或策略计算。
特别地,我们将关注使用基于梯度的优化的方法。在这种情况下,我们将基于模型的RL流程(部分)嵌入到计算图中,最终输出一个值或操作建议。
我们可以使用隐式基于模型的RL来替换显式基于模型的RL的每一个(或两个)
- 步骤:1)学习隐式转换模型,即价值等效模型(第6.1节)
- 步骤2)隐式学习如何计划(第6.2节)
- 我们将首先单独讨论每个类别,然后讨论如何将它们合并(第6.3节)。
Value equivalent models:
标准的模型学习方法,如第4节所讨论的,学习一个预测环境下一个状态的前向模型。预测环境的下一个状态。然而,这种模型可能会预测与价值无关的状态的几个方面。
在某些领域,前向动态学起来可能很复杂,但与价值预测相关的动态方面可能更平滑,也更容易学。值等效模型在计算图中展开,以预测未来的值,而不是未来的状态。它们也可以与任何其他类型的损失函数相结合,比如预测未来奖励的能力。
价值预测网络(VPN) (Value prediction network.)采用了非常类似的方法,但在模型上指定了b-best、depth-d搜索(其中b和d是超参数)。
另一个方法它只接收一个状态作为输入(而不是一个行动序列),并在内部展开其模型来预测该状态的值。当我们想选择一个最佳行动(计划)时,我们可以 为一个状态中的每个可用行动展开Predictron。
Implicit planning
我们称这个想法为,将整个规划循环嵌入到计算图中,称为隐式规划。当图中的规划操作是可微的,我们仍然可以使用端到端微分。
隐式规划图应该输出1)最优行动或策略2)最优值。因此,我们可以对他们进行两种类型的损失训练。
在第一种情况下,我们可以使用具有真实最优动作的模仿学习损失。 其基本思想是在一系列我们已经知道最佳解决方案的任务上进行训练,然后将获得的解决方案应用于新问题。
其次,当我们没有可用的专家演示时,我们可以让我们的规划图输出最优值,并在标准的无模型 RL 目标(RL 损失)上进行训练。标准的无模型 RL 目标将逐渐开始估计最优值,这将为我们的规划图生成训练信号。
Value equivalent models from an implicit planning graph
Value iteration networks.
Universal planning networks.
Learning to plan
我们也可以利用隐式规划思想对规划操作本身进行优化。
到目前为止,我们遇到了两种学习可能进入基于模型的 RL 的方式:
i)学习动态模型(第 4 节),
ii)学习价值或策略函数(从规划输出)(第 5 节)。
我们现在遇到了学习可能进入基于模型的 RL 的第三个层次:学习计划。
这个想法是在一系列任务上优化我们的规划器,最终获得更好的规划算法,这是元学习的一种形式。
我们将讨论三个学习计划的例子:MCTSNets, 想象增强agent (I2A) 和基于想象的计划者(IBP)。
Combined learning of models and planning
如果我们指定一个参数化可微模型和一个参数化可微规划过程,那么我们就可以为模型和规划操作联合优化得到的计算图。这当然会产生一个更难的优化问题,因为计划者的梯度取决于模型的质量,反之亦然。
TreeQN
Model-based Reinforcement Learning--A survey
如果模型已知,那么只需要考虑如何根据模型进行决策,如果模型未知,那么首先要学习模型,进而进行决策。而决策的方法,既有直接planning的方法,亦有根据决策网络直接输出action的方法。
状态空间的表征
首先要确保预测的下一步隐变量 \(z_{t+1}\)和当前的隐变量 \(z_t\)在同一个embedding space。常用的方法是加入一个额外的损失函数以保证 \(z_{t+1}=f^{enc}_\phi (s_{t+1})\),这里的 \(s_{t+1}\)指真实值而不是预测值。
策略的学习
如果模型是可微分的,那么可以之间根据optimal control等方法得到最优策略的解析解,即可以直接通过planning输出策略;如果模型过于复杂,也可以通过训练一个策略函数和价值函数,直接用策略函数输出动作。而在这过程中,策略函数/价值函数和planning的方法可以进行互补,因此产生了多样的方法。
1.Planning input from learned functions
如何从学习到的策略函数/价值函数来优化planning?主要有两种方法:
- 价值函数的先验:最常见的方法是把价值函数融入于planning中,通过bootstrapping就可以将未来多帧的累积奖励通过当前奖励与价值函数之和表示,从而实现planning的高效搜索。
- 策略函数的先验:学习的策略函数可以作为一种先验指导planning的树的构建,比如AlphaGo Zero中用策略函数输出的分布作为蒙特卡洛树搜索的upper confidence bound. Guided Policy search中惩罚planning得到的路径与策略函数得到的路径的过大差别。
2.Planning update for policy or value update
那如何通过planning的结果来指导策略函数或价值函数的迭代呢?
- 价值函数的迭代:常见的选择是将planning搜索到的最优累积奖励作为价值函数的目标值(ground truth),从而用regression的方法更新价值函数。
- 策略函数的迭代:AlphaGo Zero中首先用蒙特卡洛树搜索的planning得到target action,再通过计算访问次数得到策略的分布函数,然后用cross entropy loss将策略函数与这一分布函数相一致来学习。Guided Policy Search中直接通过减小策略函数和planning得到的轨迹分布的KL离散度进行训练。
3.Planning output for action selection in the real environment
直接根据模型用planning的方法输出策略,最常见的是Model Predictive Control,即最优化预测的后n帧下的一系列最优动作,然后选择执行第一个最优动作,每次都如此迭代计算。
Value Prediction Network (NIPS 2017)
面对上述这个问题,这篇文章的假设就是,planning真正需要的,只是预测rewards和state values的能力。
对比于observation-prediction model,rewards和state values都依赖于predict出的observations,而如果能直接对rewards和state values进行预测,就能在复杂和随机任务中可能更learnable一点,这种model称为value-prediction model
区别于observation-prediction model,VPN是value-prediction model,其architecture也是要绕开对observation,而直接对rewards和state values进行prediction。
如果是单一agent的场景下,state和observation并没有区别
如果是多agent的场景下,则每个agent的observation与全局的state是不一样的
a. Encoding modules:对原始observation变换到abstract state(paper中的说法)
b. value module:对state values 进行prediction
c. transition module:在abstract state space 对option-conidtional的k-step transition的prediction
d. outcome module:predict option 的k-step累计收益,以及discount,对于option的k-step execution而言,discount即是execution step的一种等价表现
\(f^{core}_\theta :s,o\rightarrow r,\gamma V_\theta ({s}'),{s}'\)
如何用VPN的models来induce a policy和计算value function拟合时的target value?
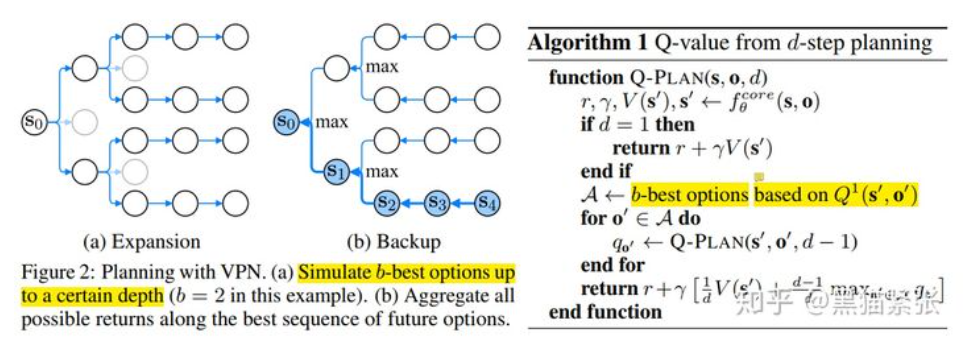
文中给出了一种planning 的方法:用VPN rollout 一定planning depth,并且aggregate all immediate value estimates,来计算Q values from n-step planning,从而能够根据Q values来得到policy(e.g., epsilon greedy)
在d-step planning 计算中,越近的search得到的value estimates对Q value contribution越大,越近的越依赖value function的prediction。
Expansion即用core module进行rollout,每个step只对b-best option进行rollout,以约减搜索空间,rollout至最大depth d;backup即按照上述Equation 1,进行d-step planning Q value的计算.
VPN 则是首先将真实环境中获得的 state/observation 通过一个 encoding network 转化到 abstract state space 中的一个 absract state,而 dynamics model 是一直在 abstract state space 进行未来若干步的 transition 与 reward 的预测,value prediction network 也是对 abstract state 进行 value 的预测。
Encoding network 的训练目标并不是显式地使输出的 abstract state 与真实环境中的 state 尽量接近或一一对应,而是使在 abstract state space 中训练的 dynamics model 及 value prediction network 在给定初始 abstract state (将真实环境中获得的初始 state/observation 输入 encoding network 得到的) 及未来 k 步的 action 序列后,对未来 k 步的 reward 与 value 的预测与真实环境中获得的 reward 及 value 尽量接近。这样做的道理是我们学一个 dynamics model 的目的是用它来做 planning,我们实际上并不关心这个 dynamic model 是否准确地还原了真实环境中的 state transition,只要这个 dynamics model 给出的未来每一步的 reward 接近真实环境中的值,那么就能作为 planning 中的模拟器来使用。
如何评价DeepMind新提出的MuZero算法?

