为什么需要线程
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
-
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
-
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
什么是线程
线程,有时被称为轻量进程(Lightweight Process,LWP),是程序执行流的最小单元,也是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
线程与进程的区别:
- 根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
- 在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
- 所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
- 内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
- 包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
Python之GIL(Global Interpreter Lock)
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL。
那么什么是GIL呢,下面是官方文档给出的解释:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
为什么会有GIL的原因:
- 由于物理上得限制,各CPU厂商在核心频率上的比赛已经被多核所取代。为了更有效的利用多核处理器的性能,就出现了多线程的编程方式,而随之带来的就是线程间数据一致性和状态同步的困难。即使在CPU内部的Cache也不例外,为了有效解决多份缓存之间的数据同步时各厂商花费了不少心思,也不可避免的带来了一定的性能损失。
- Python当然也逃不开,为了利用多核,Python开始支持多线程。而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。
- 慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,并且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
- 所以简单的说GIL的存在更多的是历史原因。如果推倒重来,多线程的问题依然还是要面对,但是至少会比目前GIL这种方式会更优雅。
Python多线程
多线程的调用方式
1、直接调用多线程
import threading import time def run(n): time.sleep(3) print('task',n) t1 = threading.Thread(target=run,args=('t1',)) t2 = threading.Thread(target=run,args=('t2',)) t1.start() t2.start()
t1.join() #等待线程t1执行完毕
PS:
#threading.current_thread() 打印当前线程
#threading.active_count() 打印当前活跃线程数
2、继承式调用多线程(一般这种用的比较少)
import threading import time class MyThread(threading.Thread): def __init__(self, num): threading.Thread.__init__(self) self.num = num def run(self): time.sleep(3) print("running on number:%s" % self.num) if __name__ == '__main__': t1 = MyThread(1) t2 = MyThread(2) t1.start() t2.start()
守护线程
在线程start之前,可以把线程变成守护线程,守护线程服务于非守护线程,当非守护线程执行完毕之后,程序直接结束,不会管非守护线程是否执行完。t.setDaemon(True),t为生成的线程。
互斥锁(Mutex)
python在使用多线程的时候已经有了GIL为什么还需要线程锁呢?因为python 的GIL只能控制同一时间只能有一个线程在运行,但是不能控制同一时间只有一个线程在修改数据。有人会问,既然都已经只有一个线程在运行,为什么还会有多个线程在修改数据呢?我们看下面的图。。。
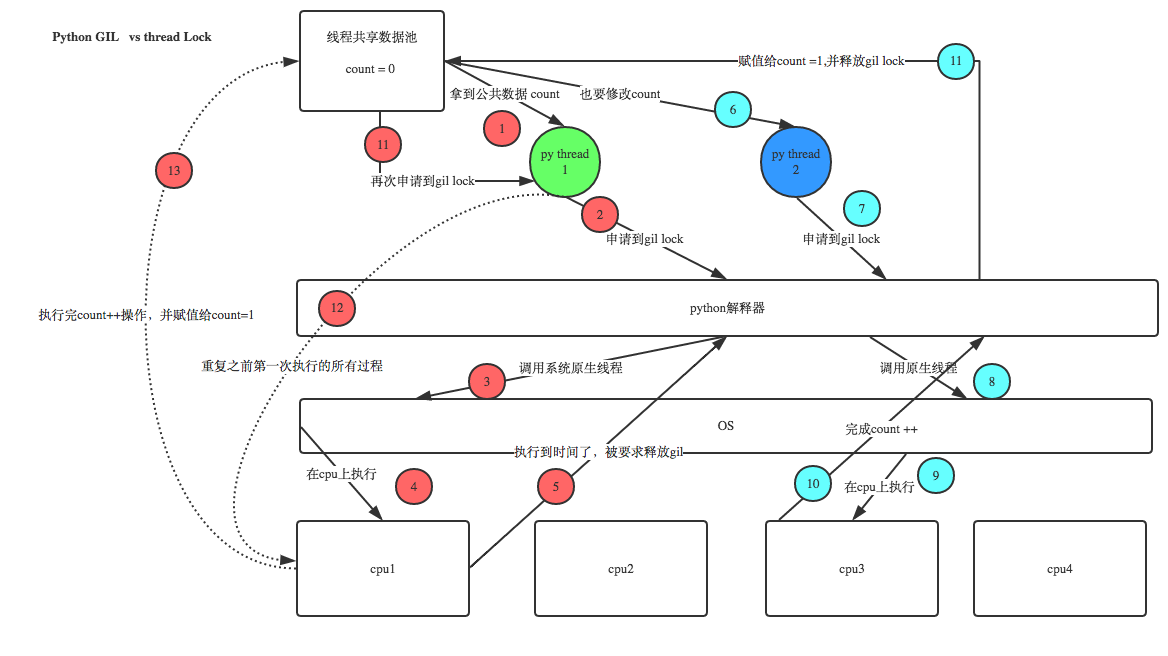


import time import threading def addNum(): global num #在每个线程中都获取这个全局变量 print('--get num:',num ) time.sleep(1) num -=1 #对此公共变量进行-1操作 num = 100 #设定一个共享变量 thread_list = [] for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: #等待所有线程执行完毕 t.join() print('final num:', num )
PS:不要在3.x上运行,3.x上的结果总是正确的,可能是内部加了锁
正常来讲,这个num结果应该是0, 但在Linux的python 2.7上多运行几次,会发现,最后打印出来的num结果不总是0,为什么每次运行的结果不一样呢? 哈,很简单,假设你有A,B两个线程,此时都 要对num 进行减1操作, 由于2个线程是并发同时运行的,所以2个线程很有可能同时拿走了num=100这个初始变量交给cpu去运算,当A线程去处完的结果是99,但此时B线程运算完的结果也是99,两个线程同时CPU运算的结果再赋值给num变量后,结果就都是99。那怎么办呢? 很简单,每个线程在要修改公共数据时,为了避免自己在还没改完的时候别人也来修改此数据,可以给这个数据加一把锁, 这样其它线程想修改此数据时就必须等待你修改完毕并把锁释放掉后才能再访问此数据。
import time import threading def addNum(): global num # 在每个线程中都获取这个全局变量 lock.acquire() # 修改数据前加锁 num -= 1 # 对此公共变量进行-1操作 lock.release() # 修改后释放 num = 100 # 设定一个共享变量 thread_list = [] lock = threading.Lock() # 生成全局锁 for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: # 等待所有线程执行完毕 t.join() print('final num:', num)
PS:就算以后用3.x的版本也要自己加锁,即使不加锁结果正确也要加,因为官方文档没有明确指出3.x的版本内部加了锁。
RLock递归锁
说白了就是锁中还有锁的时候,就不能简单地使用互斥锁,要使用递归锁。
import threading def run1(): print("grab the first part data") lock.acquire() global num num += 1 lock.release() return num def run2(): print("grab the second part data") lock.acquire() global num2 num2 += 1 lock.release() return num2 def run3(): lock.acquire() res = run1() print('--------between run1 and run2-----') res2 = run2() lock.release() print(res, res2) if __name__ == '__main__': num, num2 = 0, 0 lock = threading.RLock() for i in range(10): t = threading.Thread(target=run3) t.start() while threading.active_count() != 1: print(threading.active_count()) else: print('----all threads done---') print(num, num2)
Semaphore(信号量)
互斥锁同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 。
import threading, time def run(n): semaphore.acquire() time.sleep(1) print("run the thread: %s " % n) semaphore.release() num = 0 semaphore = threading.BoundedSemaphore(5) # 最多允许5个线程同时运行 for i in range(20): t = threading.Thread(target=run, args=(i,)) t.start() while threading.active_count() != 1: pass else: print('----all threads done---') print(num)
Event事件
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞;如果“Flag”值为True,那么执行event.wait 方法时便不再阻塞。
- clear:将“Flag”设置为False
- set:将“Flag”设置为True
- is_set:判断“Flag”是否被设置
- wait:“Flag”值为 False,wait 方法时就会阻塞
用 threading.Event 实现线程间通信,使用threading.Event可以使一个线程等待其他线程的通知,我们把这个Event传递到线程对象中,
Event默认内置了一个标志,初始值为False。一旦该线程通过wait()方法进入等待状态,直到另一个线程调用该Event的set()方法将内置标志设置为True时,该Event会通知所有等待状态的线程恢复运行。
通过Event来实现两个或多个线程间的交互,下面是一个红绿灯的例子,即起动一个线程做交通指挥灯,生成几个线程做车辆,车辆行驶按红灯停,绿灯行的规则。
import threading, time import random def light(): if not event.isSet(): #初始化evet的flag为真 event.set() #wait就不阻塞 #绿灯状态 count = 0 while True: if count < 10: print('�33[42;1m---green light on---�33[0m') elif count < 13: print('�33[43;1m---yellow light on---�33[0m') elif count < 20: if event.isSet(): event.clear() print('�33[41;1m---red light on---�33[0m') else: count = 0 event.set() #打开绿灯 time.sleep(1) count += 1 def car(n): while 1: time.sleep(random.randrange(3, 10)) #print(event.isSet()) if event.isSet(): print("car [%s] is running..." % n) else: print('car [%s] is waiting for the red light...' % n) event.wait() #红灯状态下调用wait方法阻塞,汽车等待状态 if __name__ == '__main__': car_list = ['BMW', 'AUDI', 'SANTANA'] event = threading.Event() Light = threading.Thread(target=light) Light.start() for i in car_list: t = threading.Thread(target=car, args=(i,)) t.start()
queue队列
- class
queue.Queue(maxsize=0) #先入先出
- class
queue.LifoQueue(maxsize=0) #last in fisrt out
- class
queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
队列常用方法
Queue.qsize()
Queue.empty() #return True if empty
Queue.full() # return True if full
Queue.put(item, block=True, timeout=None) # priority_number, data
Queue.put_nowait()
Queue.get()
Queue.get_nowait()
import queue q2 = queue.Queue() q1 = queue.LifoQueue() q = queue.PriorityQueue() q.put((8,'alex')) q.put((6,'wusir')) q.put((7,'json')) print(q.get()) print(q.get()) print(q.get()) print(q.get(timeout=3)) #自由修改数据自己测试