写在前面
为了使用python学习爬取疫情数据,提前学习了python中的语法和各种存储结构(dirt),若没有这些基础很难看懂python代码,更别提写了
题目
题目和上一篇博客一样,爬取疫情数据,这次我们爬取腾讯的数据,使用python来进行爬取。
思路分析
- 1.分析网页的网络数据,取得请求头,并用python的requests包进行解析和读取。
- 2.分析解析出的包,进行提取和操作
- 3.将数据提出并存到数据库
- 涉及知识点:python对mysql的操作,python的爬取
效果截图
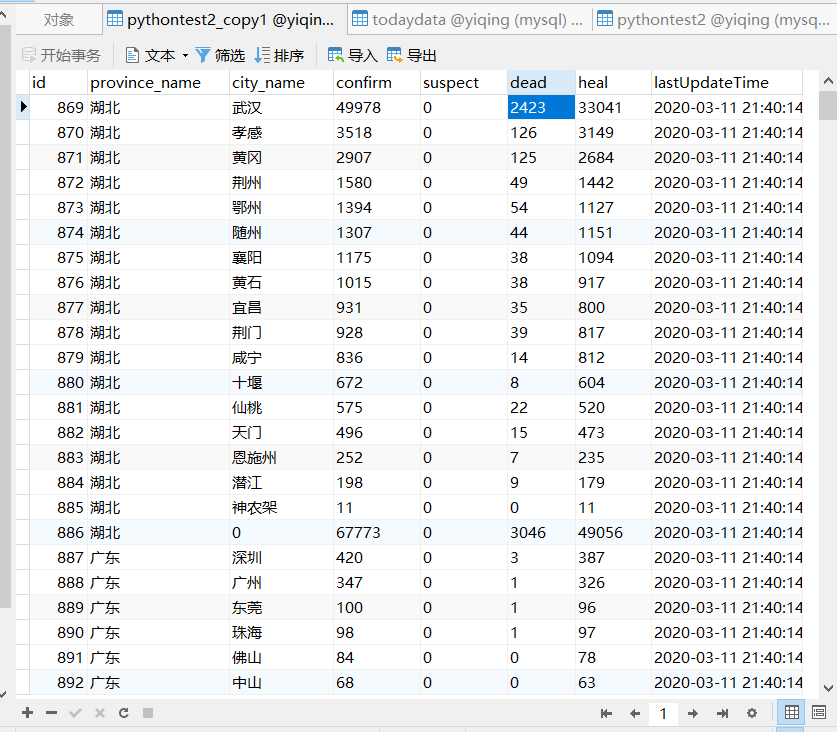
代码展示
import pymysql
import requests
import json
# 放入要爬的url
url = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5"
# 设置header做一个防爬机制
header = {"user-agent": "Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Mobile Safari/537.36"}
# 获取response的json
response = requests.get(url, headers=header)
# 取得数据词典
data = json.loads(response.content.decode())
data_str = data['data']
data_json = json.loads(data_str)
# 取出各个省和市的dict
areaTree = data_json['areaTree'][0]['children']
# 连接数据库
db = pymysql.connect(host = 'localhost', port=3306, user='root', password='abc456', db='yiqing', charset='utf8')
#使用cursor方法生成一个游标
cursor = db.cursor()
# 更新时间
lastUpdateTime = data_json['lastUpdateTime']
for province_list in areaTree:
province_name = province_list['name']
confirm_total = province_list['total']['confirm']
suspect_total = province_list['total']['suspect']
dead_total = province_list['total']['dead']
heal_total = province_list['total']['heal']
for itemChild in province_list['children']:
city_name = itemChild['name']
confirm = itemChild['total']['confirm']
suspect = itemChild['total']['suspect']
dead = itemChild['total']['dead']
heal = itemChild['total']['heal']
# 插入数据
sql = "insert into pythontest2_copy1(id, province_name, city_name, confirm, suspect, dead, heal,lastUpdateTime) values ({},'{}','{}','{}','{}','{}','{}','{}')".format(0, province_name, city_name, confirm, suspect, dead, heal,lastUpdateTime)
cursor.execute(sql)
sql_total = "insert into pythontest2_copy1(id, province_name, city_name, confirm, suspect, dead, heal,lastUpdateTime) values ({},'{}',{},'{}','{}','{}','{}','{}')".format(
0, province_name, 0, confirm_total, suspect_total, dead_total, heal_total, lastUpdateTime)
cursor.execute(sql_total)
db.commit()
实际完成时间表
预估时间:两个小时
| 日期 | 开始时间 | 结束时间 | 中断时间 | 净时间 | 活动 | 备注 |
|---|---|---|---|---|---|---|
| 3.11 | 16:00 | 16:50 | 20 | 30 | 编码前准备 | |
| 3.11 | 21:00 | 21:30 | 30 | 编写代码 | ||
| 3.11 | 21:30 | 21:45 | 15 | 测试 | ||
| 3.11 | 21:45 | 21:50 | 5 | 整理 |
缺陷记录表
| 日期 | 编号 | 类型 | 引入阶段 | 排除阶段 | 修复时间 | 修复缺陷 | 描述 |
|---|---|---|---|---|---|---|---|
| 3.11 | 1 | 1 | 编码 | 编码 | 1min | 规范缩进 | 缩进不够规范,出现错误 |
| 3.11 | 2 | 2 | 编码 | 测试 | 2min | 修改sql语句位置 | 数据库存储的数据与预期的不一致 |
| 3.11 | 3 | 3 | 编码 | 测试 | 1min | 删掉多余的"," | sql语句书写不规范,无法插入数据库 |
| 3.11 | 4 | 4 | 编码 | 测试 | 3min | 将string再转成python对象类型 | 没有正确提取数据 |
总结
可以很明显的看到用python编写爬虫的简单和简便,不得不感叹各个语言的特性。这里的大部分时间都用在看别人的代码上了,但最后收获也很大。
Ps:python的缩进规范确实难顶啊