题目
本题的意思很明确,用java爬取网站的疫情数据,并存到数据库中。我们可以用Jsoup的插件进行java的爬取。
思路分析
- 1.如何用Jsoup进行数据的爬取呢,我们首先要找到一个疫情显示网站,这里我们使用今日头条的:[今日头条疫情数据](https://i.snssdk.com/feoffline/hot_list/template/hot_list/forum_tab.html?activeWidget=1),进入网站后用firefox浏览器按F12,找到需要的接口即可,这里不再找了。我们发现接口为(https://i.snssdk.com/forum/home/v1/info/?activeWidget=1&forum_id=1656784762444839)
- 2.在找到接口后,我们要分析我们想要的数据在哪,可以用网页查看js代码来找到所需的list,我们这里找到是ncov_string_list
- 3.有了基本的list后,我们只需分别取数据并存在数据库即可
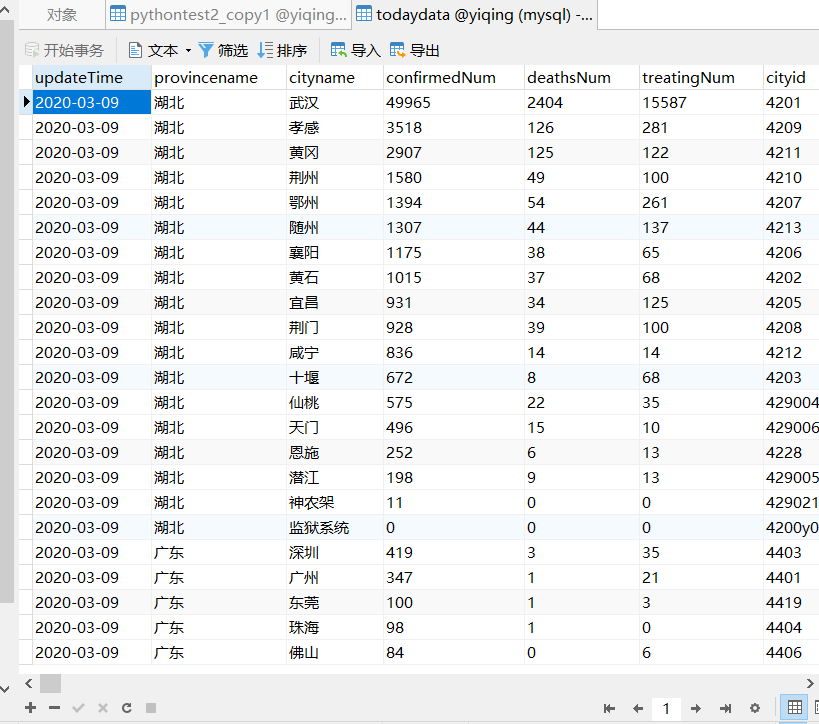
效果截图
下为爬取后存到mysql的截图
代码展示
//定义几个常量防止反爬虫
public static String USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:49.0) Gecko/20100101 Firefox/49.0";
public static String HOST = "i.snssdk.com";
public static String REFERER = "https://i.snssdk.com/feoffline/hot_list/template/hot_list/forum_tab.html?activeWidget=1";
public static void main(String[] args) throws IOException, SQLException {
//根URL
String url = "https://i.snssdk.com/forum/home/v1/info/?activeWidget=1&forum_id=1656784762444839";
String resultBody = Jsoup.connect(url).
userAgent(USER_AGENT).header("Host", HOST).header("Referer", REFERER).execute().body();
JSONObject jsonObject = JSON.parseObject(resultBody);
String ncovStringList = jsonObject.getJSONObject("forum").getJSONObject("extra").getString("ncov_string_list");
JSONObject ncovListObj = JSON.parseObject(ncovStringList);
JSONArray todaydata = ncovListObj.getJSONArray("provinces");
QueryRunner queryRunner = new QueryRunner(DataSourceUtils.getDataSource());
String sql = "insert into todaydata_copy1 values(?,?,?,?,?,?,?,?)";
String confirmedNum,deathsNum,cityname,cityid,treatingNum,provinceid;
String reprovinceid=null;
int confirmedNumSum=0,deathsNumSum=0,treatingNumSum=0;
for(int i=0;i<todaydata.size();i++) {
JSONObject todayData1 = todaydata.getJSONObject(i);
String updateDate = todayData1.getString("updateDate");
JSONArray city = todayData1.getJSONArray("cities");
for(int j=0;j<city.size();j++) {
JSONObject cities = city.getJSONObject(j);
confirmedNum= cities.getString("confirmedNum");
deathsNum = cities.getString("deathsNum");
cityname = cities.getString("name");
cityid = cities.getString("id");
treatingNum = cities.getString("treatingNum");
provinceid = cityid.substring(0,2);
reprovinceid=provinceid;
confirmedNumSum+=Integer.parseInt(confirmedNum);
deathsNumSum+=Integer.parseInt(deathsNum);
treatingNumSum+=Integer.parseInt(treatingNum);
queryRunner.update(sql, updateDate,provinceid,cityname,confirmedNum,deathsNum,treatingNum,cityid,null);
}
queryRunner.update(sql,updateDate,reprovinceid,null,confirmedNumSum,deathsNumSum,treatingNumSum,null,null);
confirmedNumSum=0;
deathsNumSum=0;
treatingNumSum=0;
}
}
实际完成时间表
预估时间:三个小时
| 日期 | 开始时间 | 结束时间 | 中断时间 | 净时间 | 活动 | 备注 |
|---|---|---|---|---|---|---|
| 3.10 | 16:00 | 16:50 | 20 | 30 | 编码前准备 | |
| 3.10 | 16:50 | 17:50 | 60 | 寻找list | 这里为了找需要的list浪费了很多时间 | |
| 3.10 | 17:50 | 18:30 | 10 | 30 | 编写代码 | 中间十分钟去了厕所和接水 |
| 3.10 | 18:30 | 19:35 | 5 | 60 | 测试 | 中间五分钟去了厕所 |
| 3.10 | 19:35 | 19:45 | 10 | 进行整理 |
缺陷记录表
| 日期 | 编号 | 类型 | 引入阶段 | 排除阶段 | 修复时间 | 修复缺陷 | 描述 |
|---|---|---|---|---|---|---|---|
| 3.10 | 1 | 1 | 编码 | 编码 | 50min | 蛮找 | 无法正确找到list |
| 3.10 | 2 | 2 | 编码 | 测试 | 10min | 存取数据库用的方法错误,错将update方法用成了execute方法 | |
| 3.10 | 3 | 3 | 编码 | 测试 | 20min | 改变sql语句 | 数据库的数据无法正确显示省份 |
总结
这次使用Jsoup爬取数据,深刻体会到了什么是爬取数据最困难的:找到正确的json并且提取出来。也以此为契机决定使用python爬取一下看看,见下篇博客:
(https://www.cnblogs.com/wushenjiang/p/12466220.html)