python-模块的分类与导入
1,什么是模块:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。
在Python中,一个.py文件就称之为一个模块(Module)。
2,使用模块的好处:
- 提高可维护性
- 可重用
- 避免函数名和变量名冲突
3,模块的分类
- 内置标准模块(又称标准库)执行help('modules')查看所有python自带模块列表
- 第三方开源模块,可通过pip install 模块名 联网安装 django
- 自定义模块

4,模块调用
import module from module import xx from module.xx.xx import xx as rename from module.xx.xx import * # 不推荐
注意:模块一旦被调用,即相当于执行了另外一个py文件里的代码
1,import random 导入模块的所有方法
这会将对象(这里的对象指的是包、模块、类或者函数,下同)中的所有内容导入。如果该对象是个模块,那么调用对象内的类、函数或变量时,需要以module.xxx的方式。
2,import multiprocessing as mul 模块别名
3,from django.core import handlers 导入模块的单个方法
从某个对象内导入某个指定的部分到当前命名空间中,不会将整个对象导入。这种方式可以节省写长串导入路径的代码,但要小心名字冲突。

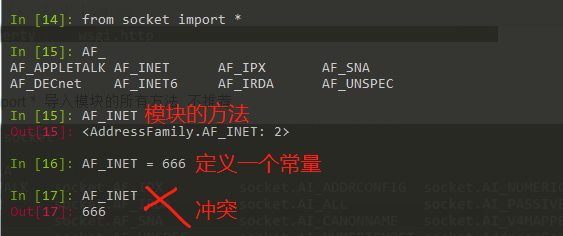
4,from socket import * 导入模块的所有方法 不推荐
将对象内的所有内容全部导入。非常容易发生命名冲突,请慎用!

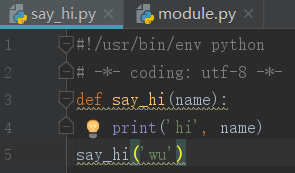
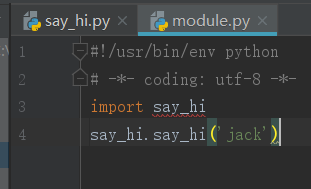
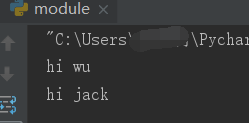
5,自定义模块
这个最简单, 创建一个.py文件,就可以称之为模块,就可以在另外一个程序里导入
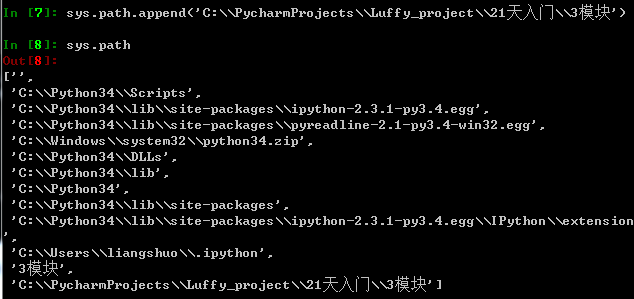
6,模块查找顺序

python解释器会按照列表顺序去依次到每个目录下去匹配你要导入的模块名,只要在一个目录下匹配到了该模块名,就立刻导入,不再继续往后找。
注意列表第一个元素为空,即代表当前目录,所以你自己定义的模块在当前目录会被优先导入。
默认情况下,模块的搜索顺序是这样的:
- 当前执行脚本所在目录
- Python的安装目录
- Python安装目录里的site-packages目录
其实就是“自定义”——>“内置”——>“第三方”模块的查找顺序。任何一步查找到了,就会忽略后面的路径,所以模块的放置位置是有区别的。
7,开源模块学习的安装方式
http://pypi.python.org/pypi 是python的开源模块库,是python的开源模块库,截止2018年8月 ,已经收录了147,422个来自全世界python开发者贡献的模块,几乎涵盖了你想用python做的任何事情。
1.直接在上面这个页面上点download,下载后,解压并进入目录,执行以下命令完成安装
编译源码 python setup.py build 安装源码 python setup.py install
2.直接通过pip安装
pip3 install paramiko # parmiko 是模块名
pip命令会自动下载模块包并完成安装。
软件一般会被自动安装你python安装目录的这个子目录里
/your_python_install_path/3.6/lib/python3.6/site-packages
pip命令默认会连接在国外的python官方服务器下载,速度比较慢,你还可以使用国内的豆瓣源,数据会定期同步国外官网,速度快好多
sudo pip install -i http://pypi.douban.com/simple/ alex_sayhi --trusted-host pypi.douban.com #alex_sayhi是模块名
使用
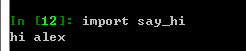
下载后,直接导入使用就可以,跟自带的模块调用方法无差,演示一个连接linux执行命令的模块
#coding:utf-8
import paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect('192.168.1.108', 22, 'alex', '123')
stdin, stdout, stderr = ssh.exec_command('df')
print(stdout.read())
ssh.close();
执行命令 - 通过用户名和密码连接服务器
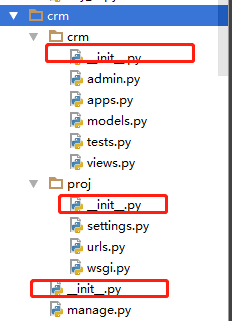
8,包(Package)
当你的模块文件越来越多,就需要对模块文件进行划分,比如把负责跟数据库交互的都放一个文件夹,把与页面交互相关的放一个文件夹,
为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package),包是模块的集合,比模块又高一级的封装。通俗来说,在里面一个文件夹可以管理多个模块文件,这个文件夹就被称为包
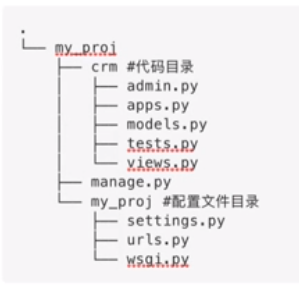
没有比包更高级别的封装,但是包可以嵌套包,就像文件目录一样:如下图
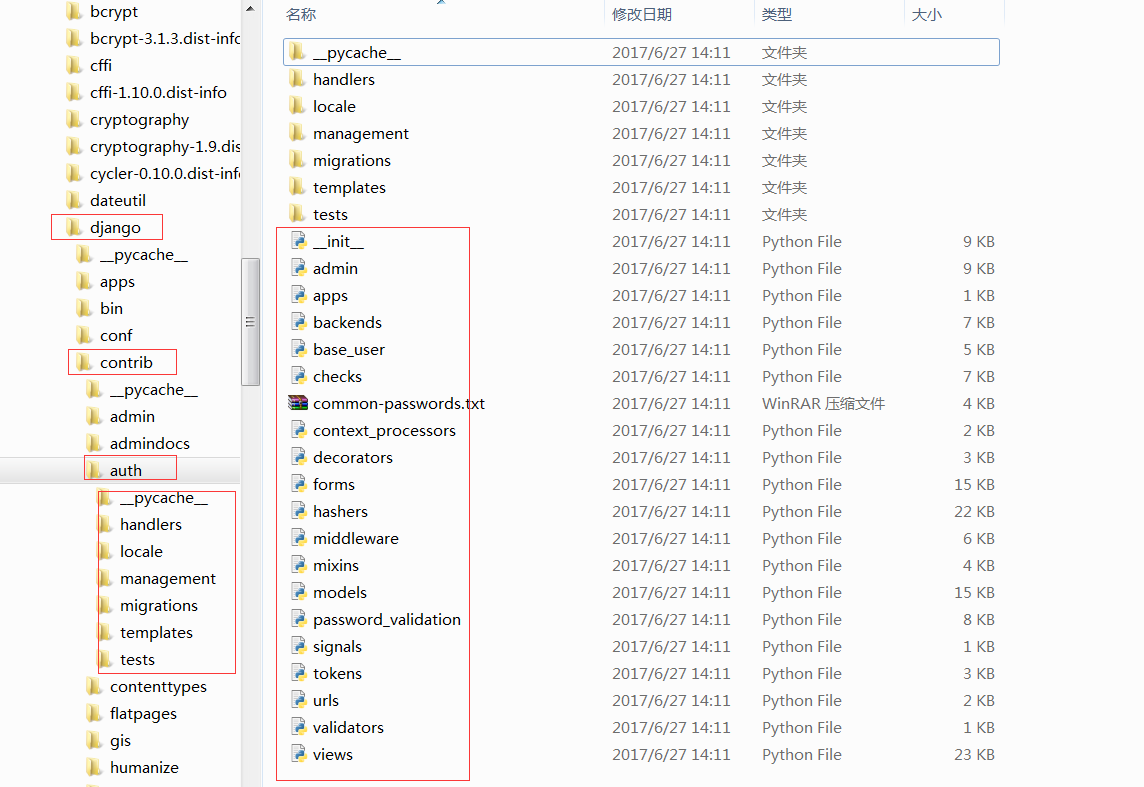
最顶层的Django包封装了contrib子包,contrib包又封装了auth等子包,auth又有自己的子包和一系列模块。通过包的层层嵌套,我们能够划分出一个又一个的命名空间。
包名通常为全部小写,避免使用下划线。
__int__.py用于标识当前文件夹是一个包。 python2,包就是文件夹,但该文件夹下必须存在 __init__.py 文件, 该文件的内容可以为空。__int__.py用于标识当前文件夹是一个包。 在python3里,即使目录下没__int__.py文件也能创建成功,猜应该是解释器优化所致,但创建包还是要记得加上这个文件 吧。
9,跨模块导入
os.path.abspath(__file__) # 返回绝对路径 print(__file__) # 打印改文件的相对路径 os.path.dirname(__file__) # 打印该文件父目录 相对路径
如何实现在crm/views.py里导入proj/settings.py模块?
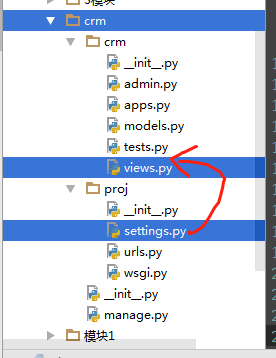
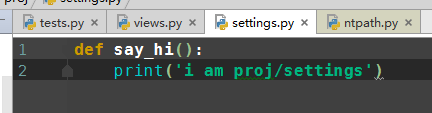
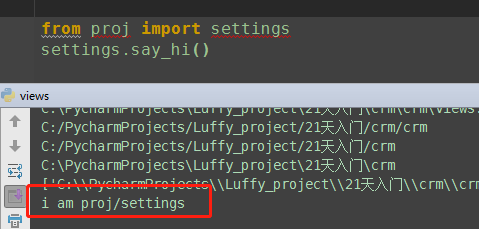
import sys, os print(dir()) print(__file__) # 打印改文件的相对路径 BASE_DIR3 = os.path.abspath(__file__) # 返回绝对路径 print(BASE_DIR3) BASE_DIR1 = os.path.dirname(__file__) # 打印该文件父目录 相对路径 BASE_DIR2 = os.path.dirname(os.path.dirname(__file__)) # 打印该文件父目录,父目录 相对路径 print(BASE_DIR1) print(BASE_DIR2) # 两个模块的父目录加入到path路径中, # 然后就可以跨模块导入了 BASE_DIR = os.path.dirname((os.path.dirname((os.path.abspath(__file__))))) print(BASE_DIR) sys.path.append(BASE_DIR) # 'C:\PycharmProjects\Luffy_project\21天入门\crm'] print(sys.path) from proj import settings settings.say_hi()
10,相对导入,绝对导入
文件夹被python解释器视作package需要满足两个条件:
1.文件夹中必须有__init__.py文件,该文件可以为空,但必须存在该文件。
2.不能作为顶层模块来执行该文件夹中的py文件(即不能作为主函数的入口)。注:虽然python支持相对导入,但对模块间的路径关系要求比较严格,处理不当就容易出错,so并不建议在项目里经常使用。
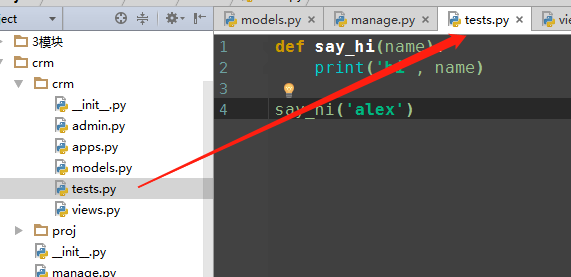
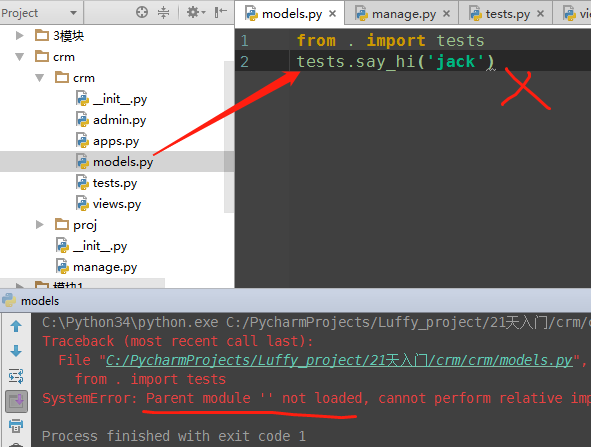
所以这个问题的解决办法就是,既然你在views.py里执行了相对导入,那就不要把views.py当作入口程序,可以通过上一级的manage.py调用views.py
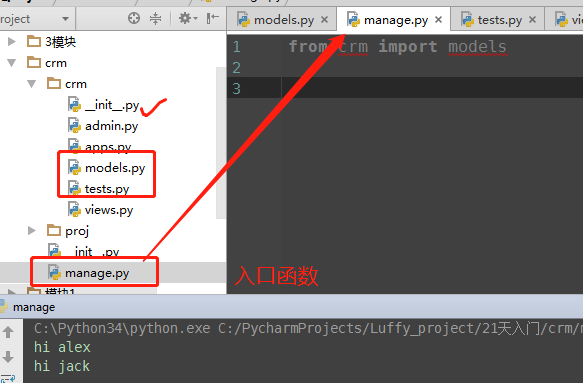
11,_all_变量
如果包定义文件__init__.py中存在一个叫做__all__的列表变量,那么在使用from package import *的时候就把这个列表中的所有名字作为要导入的模块名。
例如在example/p1/__init__.py中包含如下代码:
__all__ = ["x"]
- 这表示当你使用
from example.p1 import *这种用法时,你只会导入包里面的x子模块。 - import sendmsg #通过这个方式不受影响
# say_hi文件
__all__ = ["test1","num"] # 只能让调用test1,num1
def test1():
print("----test1")
def test2():
print("----test2")
num = 1
# import调用模块 import say_hi say_hi.test1() say_hi.test2()
----test1 ----test2
# from 调用模块
from say_hi import *
test1()
test2()
# error
----test1
Traceback (most recent call last):
File "C:/PycharmProjects/Luffy_project/21天入门/3模块/1test.py", line 3, in <module>
test2()
NameError: name 'test2' is not defined