import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('D:\myfiles\study\python\analyse\数据团\城市数据团_数据分析师_体验课_课程资料\数据资料\地市级党委书记数据库(2000-10).csv', encoding='gbk')
# 新建变量data_age,赋值包括年份、出生年份字段内容
# 清除缺失值
data_age = data[['出生年份','党委书记姓名','年份']]
data_age_re = data_age[data_age['出生年份'].notnull()]
# 计算出整体年龄数据
df1 = 2017 - data_age_re['出生年份']
# 计算出入职年龄数据
df_yearmin = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).min()
df2 = df_yearmin['年份'].groupby(df_yearmin['年份']).count()
df_yearmax = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).max()
df3 = df_yearmax['年份'].groupby(df_yearmax['年份']).count()
# 专业情况:专业结构 / 专业整体情况 / 专业大类分布
# 新建变量data_major,赋值包括年份、专业等字段内容,其中1代表是,0代表否
# 清除缺失值
data_major = data[['党委书记姓名','年份','专业:人文','专业:社科','专业:理工','专业:农科','专业:医科']]
data_major_re = data_major[data_major['专业:人文'].notnull()]
# 统计每个人的专业
data_major_re['专业'] = data_major_re[['专业:人文', '专业:社科', '专业:理工', '专业:农科', '专业:医科']].idxmax(axis=1)
# 去重
data_major_st = data_major_re[['专业','党委书记姓名']].drop_duplicates()
# 计算出学历结构数据
df4 = data_major_st['专业'].groupby(data_major_st['专业']).count()
# 计算每年专业整体情况数据
df5 = pd.crosstab(data_major_re['年份'], data_major_re['专业'])
# 计算每年专业大类分布数据
df5['社科比例'] = df5['专业:社科'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
df5['人文比例'] = df5['专业:人文'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
df5['理工农医比例'] = (df5['专业:理工'] + df5['专业:医科'] + df5['专业:农科'])/ (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
# 年龄情况:图表绘制
# 创建一个图表,大小为12*8
fig_q2 = plt.figure(figsize = (14,12))
# 创建一个3*2的表格矩阵
ax1 = fig_q2.add_subplot(2,3,1)
ax2 = fig_q2.add_subplot(2,3,2)
ax3 = fig_q2.add_subplot(2,3,3)
ax4 = fig_q2.add_subplot(2,3,4)
ax5 = fig_q2.add_subplot(2,3,5)
ax6 = fig_q2.add_subplot(2,3,6)
# 绘制第一个表格
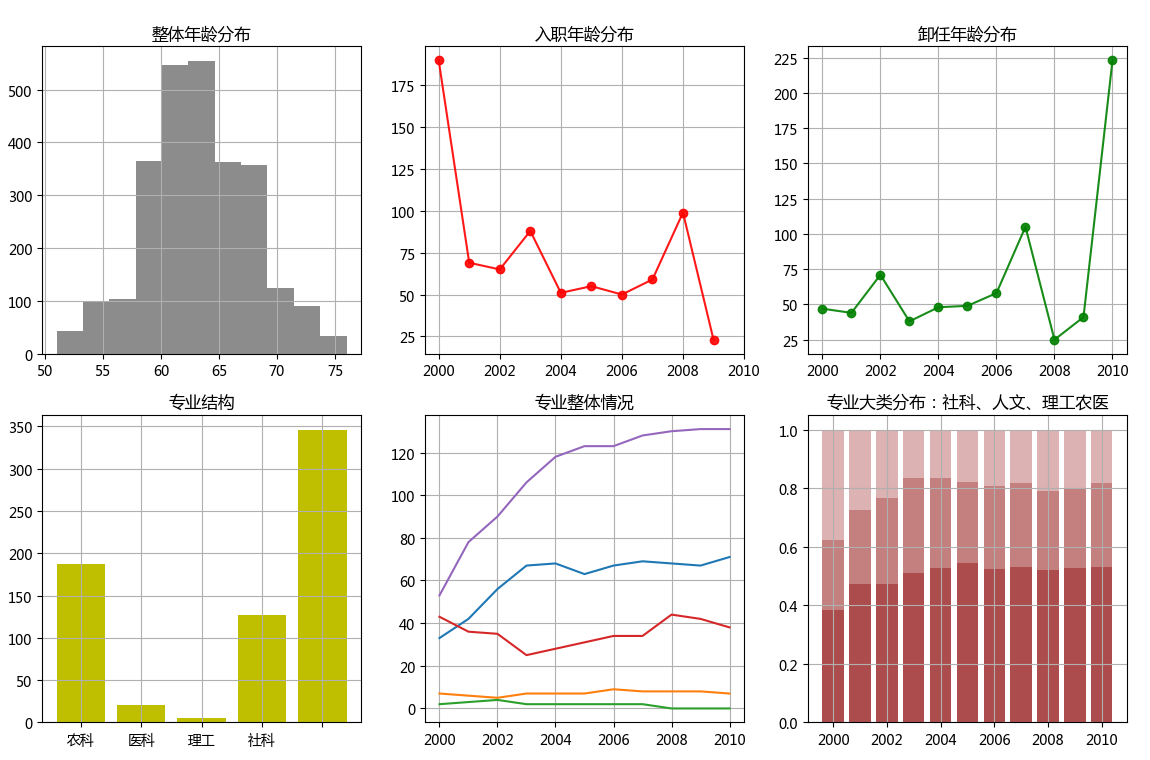
ax1.hist(df1,bins = 11,color = 'gray', alpha=0.9)
ax1.set_title('整体年龄分布')
ax1.grid(True)
# 绘制第二个表格
ax2.plot(df2,color = 'r',marker = 'o',alpha=0.9)
ax2.set_title('入职年龄分布')
ax2.set_xticks(range(2000,2011,2))
ax2.grid(True)
# 绘制第三个表格
ax3.plot(df3,color = 'g',marker = 'o',alpha=0.9)
ax3.set_title('卸任年龄分布')
ax3.set_xticks(range(2000,2011,2))
ax3.grid(True)
# 绘制第四个表格
ax4.bar(range(len(df4)),df4,color = 'y')
ax4.set_xticklabels(['人文','农科','医科','理工','社科'])
ax4.grid(True)
ax4.set_title('专业结构')
# 绘制第五个表格
ax5.plot(df5.index,df5[['专业:人文','专业:农科','专业:医科','专业:理工','专业:社科']])
ax5.grid(True)
ax5.set_title('专业整体情况')
# 绘制第六个表格
ax6.bar(df5.index,df5['社科比例'],color = 'darkred',alpha=0.7)
ax6.bar(df5.index,df5['人文比例'],color = 'darkred',bottom = df5['社科比例'],alpha=0.5)
ax6.bar(df5.index,df5['理工农医比例'],color = 'darkred',bottom = df5['人文比例'] + df5['社科比例'],alpha=0.3)
ax6.grid(True)
ax6.set_title('专业大类分布:社科、人文、理工农医')
plt.show()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('D:\myfiles\study\python\analyse\数据团\城市数据团_数据分析师_体验课_课程资料\数据资料\地市级党委书记数据库(2000-10).csv', encoding='gbk')
# 新建变量data_age,赋值包括年份、出生年份字段内容
# 清除缺失值
data_age = data[['出生年份','党委书记姓名','年份']]
data_age_re = data_age[data_age['出生年份'].notnull()]
# 计算出整体年龄数据
df1 = 2017 - data_age_re['出生年份']
# 计算出入职年龄数据
df_yearmin = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).min()
df2 = df_yearmin['年份'].groupby(df_yearmin['年份']).count()
df_yearmax = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).max()
df3 = df_yearmax['年份'].groupby(df_yearmax['年份']).count()
# 专业情况:专业结构 / 专业整体情况 / 专业大类分布
# 新建变量data_major,赋值包括年份、专业等字段内容,其中1代表是,0代表否
# 清除缺失值
data_major = data[['党委书记姓名','年份','专业:人文','专业:社科','专业:理工','专业:农科','专业:医科']]
data_major_re = data_major[data_major['专业:人文'].notnull()]
# 统计每个人的专业
data_major_re['专业'] = data_major_re[['专业:人文', '专业:社科', '专业:理工', '专业:农科', '专业:医科']].idxmax(axis=1)
# 去重
data_major_st = data_major_re[['专业','党委书记姓名']].drop_duplicates()
# 计算出学历结构数据
df4 = data_major_st['专业'].groupby(data_major_st['专业']).count()
# 计算每年专业整体情况数据
df5 = pd.crosstab(data_major_re['年份'], data_major_re['专业'])
# 计算每年专业大类分布数据
df5['社科比例'] = df5['专业:社科'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
df5['人文比例'] = df5['专业:人文'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
df5['理工农医比例'] = (df5['专业:理工'] + df5['专业:医科'] + df5['专业:农科'])/ (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
# 年龄情况:图表绘制
# 创建一个图表,大小为12*8
fig_q2 = plt.figure(figsize = (14,12))
# 创建一个3*2的表格矩阵
ax1 = fig_q2.add_subplot(2,3,1)
ax2 = fig_q2.add_subplot(2,3,2)
ax3 = fig_q2.add_subplot(2,3,3)
ax4 = fig_q2.add_subplot(2,3,4)
ax5 = fig_q2.add_subplot(2,3,5)
ax6 = fig_q2.add_subplot(2,3,6)
# 绘制第一个表格
ax1.hist(df1,bins = 11,color = 'gray', alpha=0.9)
ax1.set_title('整体年龄分布')
ax1.grid(True)
# 绘制第二个表格
ax2.plot(df2,color = 'r',marker = 'o',alpha=0.9)
ax2.set_title('入职年龄分布')
ax2.set_xticks(range(2000,2011,2))
ax2.grid(True)
# 绘制第三个表格
ax3.plot(df3,color = 'g',marker = 'o',alpha=0.9)
ax3.set_title('卸任年龄分布')
ax3.set_xticks(range(2000,2011,2))
ax3.grid(True)
# 绘制第四个表格
ax4.bar(range(len(df4)),df4,color = 'y')
ax4.set_xticklabels(['人文','农科','医科','理工','社科'])
ax4.grid(True)
ax4.set_title('专业结构')
# 绘制第五个表格
ax5.plot(df5.index,df5[['专业:人文','专业:农科','专业:医科','专业:理工','专业:社科']])
ax5.grid(True)
ax5.set_title('专业整体情况')
# 绘制第六个表格
ax6.bar(df5.index,df5['社科比例'],color = 'darkred',alpha=0.7)
ax6.bar(df5.index,df5['人文比例'],color = 'darkred',bottom = df5['社科比例'],alpha=0.5)
ax6.bar(df5.index,df5['理工农医比例'],color = 'darkred',bottom = df5['人文比例'] + df5['社科比例'],alpha=0.3)
ax6.grid(True)
ax6.set_title('专业大类分布:社科、人文、理工农医')
plt.show()