学过编程的伙伴们都知道,数据不仅可以从代码中读取,还可以从文件中读取。
今天小编就简要的介绍一下从文件中读取数据,并应用到自动化测试中方法。
先来展示下接下来将要用到的文件在项目中的结构
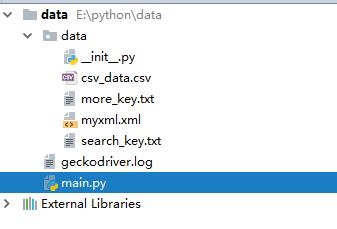
- 从txt文件
首先准备一个txt文件,这个文件中存放一些关键字,中英文数字什么的随便,小编要从文件中读取这些数据并且用百度搜索这些数据
【data.txt】
selenium 追光者 5211314 www.iqiyi,com 琅琊榜之风气长林
使用百度搜索引擎自动搜索以上内容
#以utf-8的编码、只读的形式打开文件 data=open(".datasearch_key.txt","r",encoding="utf-8") #读取每一行的数据内容 values=data.readlines() #读取完成后关闭文件 data.close() #遍历读取到的内容,将每次遍历的结果使用百度搜索 for value in values: driver = webdriver.Firefox() driver.get("https://www.baidu.com") driver.find_element_by_id("kw").send_keys(value) driver.find_element_by_id("su").click() time.sleep(3) driver.quit() print(value)
上述为最基础的内容,我们也可以在一行中保存多个关键字,使用特定的符号分割开来
【more_key.txt】
张三,zhangsan,123 李四,lisi,qwe 王五,wangwu,1e44te 赵六.zhaoliu,22332 白七七,baiqiqi,%^&*(%^&*
接下来小编只介绍如何读取这个文件的内容,至于如何在自动化测试中使用这种方法,请各位小伙伴参考上一份代码自行理解
data=open(".datamore_key.txt","r",encoding="utf-8") values=data.readlines() data.close() for value in values: #文件中每一个关键字之间使用“,”隔开,因此在代码中也使用“,”来区分不同的关键字 cn_name=value.split(",")[0] print(cn_name) en_name=value.split(",")[1] print(en_name) other=value.split(",")[2] print(other)
运行结果如下:

- 从csv文件
准备csv文件,可以使用Excel的“新建”“另存为”功能将文件保存为csv文件,但不要使用直接更改excel后缀名的方式,这种方法创建出来的不是真正的csv文件
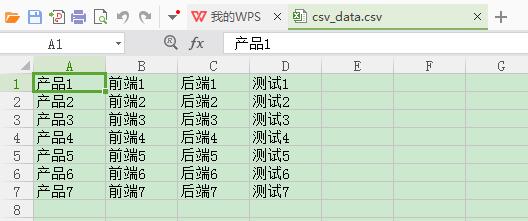
同样的,小编只介绍读取csv文件的方法
#导入csv包 import csv #with open()打开文件,既执行了打开文件,同时在方法结束后自动关闭文件,免去了我们忘记关闭文件的错误 with open(".datacsv_data.csv","r") as f: #读取csv文件 values=csv.reader(f) print("打印产品信息、测试信息") for value in values: print(value[0], value[3])
执行结果如下

- 从xml文件
准备xml文件【myxml.xml】
<?xml version="1.0" encoding="utf-8"?> <country name="China" value="2333"> <city name="北京"> <town>朝阳 </town> <town>东城 </town> <town>密云</town> </city> <city name="河北"> <town>石家庄 </town> <town>保定</town> <town>雄安</town> </city> <city name="陕西"> <town>西安</town> <town>咸阳</town> </city> <city name="山西" weather="wind"> <town name="太原"> 太原 <love>煤</love> </town> <town>大同</town> </city> <city name="unknown">UnKnown</city> </country>
1、打开xml文件
#导入xml的包 import xml.dom.minidom #打开xml文件 xml_file=xml.dom.minidom.parse('.datamyxml.xml')
xml.dom.minidom用来处理xml文件,parse可以打开xml文件
2、获取根元素标签信息
每个<xx></xx>构成一个节点,每个节点都有自己的nodeName(节点名称),nodeValue(节点值,只对文本文档有效),nodeType(节点类型)
用documentElemet将xml_file对象的文档信息传递到root中,通过root来调取结点信息
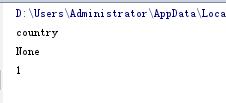
#获得文档元素对象 root=xml_file.documentElement print(root.nodeName) print(root.nodeValue) print(root.nodeType)
执行结果如下:
3、获得任意标签名
此处我们需要使用一个方法:getElementByTagName("tageName_xxx")
这个方法会扫描整个xml文件,将所有标签名为tageName_xxx的节点放到一个数组中,通过索引号进行调取。
citys[4]表示一组city的标签中的第5个,序号从0开始,注意数组的越界问题
#获取任意标签名 root=xml_file.documentElement citys=root.getElementsByTagName("city") print(citys[4].tagName) tags=root.getElementsByTagName("town") print(tags[2].tagName) tags=root.getElementsByTagName("love") print(tags[0].tagName)
4、获得标签的属性值
获取city标签的属性值name.weather
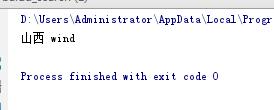
#获取标签的属性值 root=xml_file.documentElement #获得一组city的标签 citys=root.getElementsByTagName("city") #获取第4个城市的name、weather属性值 city_name=citys[3].getAttribute("name") city_weather=citys[3].getAttribute("weather") print(city_name,city_weather)
运行结果如下:
5、获得标签对之间的数据
#获取第10个towm的数据 towns=root.getElementsByTagName("town") towm_name=towns[9].firstChild.data print(towm_name)
firstChild选项返回的是该节点的第一个子结点,data表示该子节点的数据
运行结果如下:

经整理之后的源代码奉上,敬请指正


#导入xml的包 import xml.dom.minidom #打开xml文件 xml_file=xml.dom.minidom.parse('.datamyxml.xml') #获得文档元素对象 print("以下为文档根元素的信息") root=xml_file.documentElement print(root.nodeName) print(root.nodeType) print("获取任意标签名") tags=root.getElementsByTagName("city") print(tags[4].tagName) tags=root.getElementsByTagName("town") print(tags[2].tagName) tags=root.getElementsByTagName("love") print(tags[0].tagName) print("获取标签的属性值") #获得一组city的标签 citys=root.getElementsByTagName("city") #获取第4个城市的name、weather属性值 city_name=citys[3].getAttribute("name") city_weather=citys[3].getAttribute("weather") print(city_name,city_weather) print("获取第标签之间的数据") towns=root.getElementsByTagName("town") towm_name=towns[9].firstChild.data print(towm_name)