自动编码器的评级预测
AutoRec: Rating Prediction with Autoencoders
虽然矩阵分解模型在评级预测任务上取得了不错的效果,但本质上是一个线性模型。因此,这样的模型不能捕捉复杂的非线性和复杂的关系,这些关系可以预测用户的偏好。在本文中,介绍了一个非线性神经网络协同过滤模型AutoRec[Sedhain et al.,2015]。将协同过滤(CF)与自动编码器架构相结合,并在显式反馈的基础上将非线性转换整合到CF中。神经网络具有逼近任意连续函数的能力,适合于解决矩阵分解的局限性,丰富了矩阵分解的表达能力。
一方面,AutoRec具有与autocoder相同的结构,由输入层、隐藏层和重构(输出)层组成。自动编码器是一种神经网络,学习将输入复制到输出,以便将输入编码到隐藏(通常是低维)表示中。在AutoRec中,不显式地将用户/项目嵌入低维空间,而是使用交互矩阵的列/行作为输入,然后在输出层重构交互矩阵。
另一方面,AutoRec不同于传统的自动编码器:AutoRec专注于学习/重建输出层,而不是学习隐藏的表示。使用一个部分观察到的交互矩阵作为输入,旨在重建一个完整的评级矩阵。同时,在输出层通过重构将缺失的输入项填充到输出层,以达到推荐的目的。
AutoRec有两种变体:基于用户的和基于项目的。为了简洁起见,这里只介绍了基于项目的AutoRec。基于用户的AutoRec可以相应地导出。
1. Model

from d2l import mxnet as d2l
from mxnet import autograd, gluon, np, npx
from mxnet.gluon import nn
import mxnet as mx
import sys
npx.set_np()
2. Implementing the Model
典型的自动编码器由编码器和解码器组成。编码器将输入投影到隐藏表示,解码器将隐藏层映射到重建层。遵循这一实践,并创建具有密集层的编码器和解码器。编码器的激活默认设置为sigmoid,解码器不激活。在编码转换后加入了Dropout,以减少过拟合。未观察到的输入的梯度被屏蔽,以确保只有观察到的评级有助于模型学习过程。
class AutoRec(nn.Block):
def __init__(self, num_hidden, num_users, dropout=0.05):
super(AutoRec, self).__init__()
self.encoder = nn.Dense(num_hidden, activation='sigmoid',
use_bias=True)
self.decoder = nn.Dense(num_users, use_bias=True)
self.dropout = nn.Dropout(dropout)
def forward(self, input):
hidden = self.dropout(self.encoder(input))
pred = self.decoder(hidden)
if autograd.is_training(): # mask the gradient during training.
return pred * np.sign(input)
else:
return pred
3. Reimplementing the Evaluator
由于输入和输出都发生了变化,需要重新实现评估函数,而仍然使用RMSE作为精度度量。
def evaluator(network, inter_matrix, test_data, ctx):
scores = []
for values in inter_matrix:
feat = gluon.utils.split_and_load(values, ctx, even_split=False)
scores.extend([network(i).asnumpy() for i in feat])
recons = np.array([item for sublist in scores for item in sublist])
# Calculate the test RMSE.
rmse = np.sqrt(np.sum(np.square(test_data - np.sign(test_data) * recons))
/ np.sum(np.sign(test_data)))
return float(rmse)
4. Training and Evaluating the Model
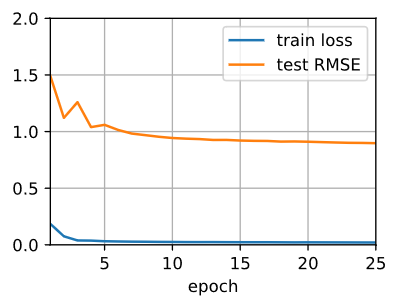
现在,让在MovieLens数据集上训练和评估AutoRec。可以清楚地看到,测试RMSE低于矩阵分解模型,证实了神经网络在评级预测任务中的有效性。
ctx = d2l.try_all_gpus()
# Load the MovieLens 100K dataset
df, num_users, num_items = d2l.read_data_ml100k()
train_data, test_data = d2l.split_data_ml100k(df, num_users, num_items)
_, _, _, train_inter_mat = d2l.load_data_ml100k(train_data, num_users,
num_items)
_, _, _, test_inter_mat = d2l.load_data_ml100k(test_data, num_users,
num_items)
num_workers = 0 if sys.platform.startswith("win") else 4
train_iter = gluon.data.DataLoader(train_inter_mat, shuffle=True,
last_batch="rollover", batch_size=256,
num_workers=num_workers)
test_iter = gluon.data.DataLoader(np.array(train_inter_mat), shuffle=False,
last_batch="keep", batch_size=1024,
num_workers=num_workers)
# Model initialization, training, and evaluation
net = AutoRec(500, num_users)
net.initialize(ctx=ctx, force_reinit=True, init=mx.init.Normal(0.01))
lr, num_epochs, wd, optimizer = 0.002, 25, 1e-5, 'adam'
loss = gluon.loss.L2Loss()
trainer = gluon.Trainer(net.collect_params(), optimizer,
{"learning_rate": lr, 'wd': wd})
d2l.train_recsys_rating(net, train_iter, test_iter, loss, trainer, num_epochs,
ctx, evaluator, inter_mat=test_inter_mat)
train loss 0.000, test RMSE 0.898
37035493.5 examples/sec on [gpu(0), gpu(1)]
5. Summary
- We can frame the matrix factorization algorithm with autoencoders, while integrating non-linear layers and dropout regularization.
- Experiments on the MovieLens 100K dataset show that AutoRec achieves superior performance than matrix factorization.