一,logging·模块
也称为日志模块,就是记录。
分为五个等级:类似于火情警报,等级越高事态越严重。
debug日志,级别为10
info日志,级别为20
warning日志,级别为30
error日志,级别为40
critical日志,级别为50
四个对象:
logger 对象:负责产生日志
filer 对象:过滤日志
handler对象:控制日志输出位置
format对象:控制日志规定的格式
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),
默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
二,hashlib模块(加密模块)
其中最常用的算法是 md5 算法。
调用md5将明文放进去,然后它帮你造出来一个密文对象:
import hashlib md = hashlib.md5() #生成一个造密文对象 md.update(b'hello') #往对象里传明文数据 md.hexdigest() #获取明文对应的密文
密文的长度越长,内部对应的算法越复杂。占用空间大,消耗的时间也多。
该模块的应用场景
1.校验文件内容是否相同
2.密码的密文存储
二--1
hashlib 模块加盐处理
在一个加密数据之前,先添加一些数据之外自定义东西。
即使撞库,也不知道哪个是真正的数据。当然,如果你执着撞库的话,也是可以获取真正的数据的。
还有个动态加盐,就是说自定义的东西是不断变化的。
三,openpyxl 模块(只支持03版本后的excel)
用代码操作excel表格。
xlwd 写excel
xlrt 读excel
from openpyxl import Workbook: wb = Workbook() wb1 = wb.create_sheet('index') wb.save('test.xlsx')
四,包的使用
就是一个文件夹下有多个模块,那么这个文件夹就是包。其本质仍然是个模块
优点:节省代码冗余,可以更加有条理的管理模块
而用包下的模块,步骤与模块有些许不同:
1.创建一个包下__init__py文件的名称空间
2.执行包下的__init__py文件种的代码,将产生的名字放入其中。
3.在执行文件中拿到一个指向包下的__init__py名称空间里的名字
在导入语句中,点号的左边永远是个包
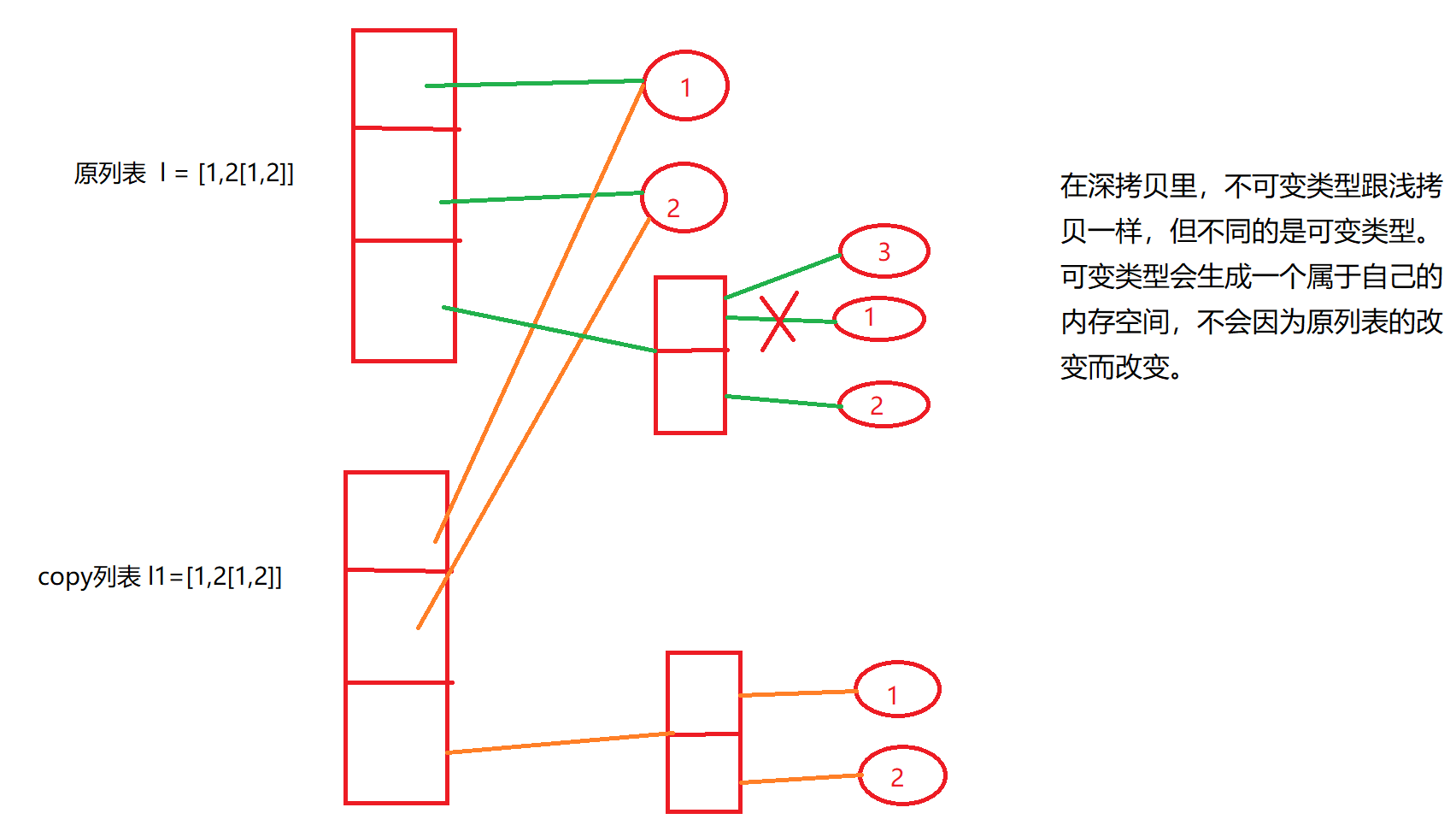
五,深浅拷贝
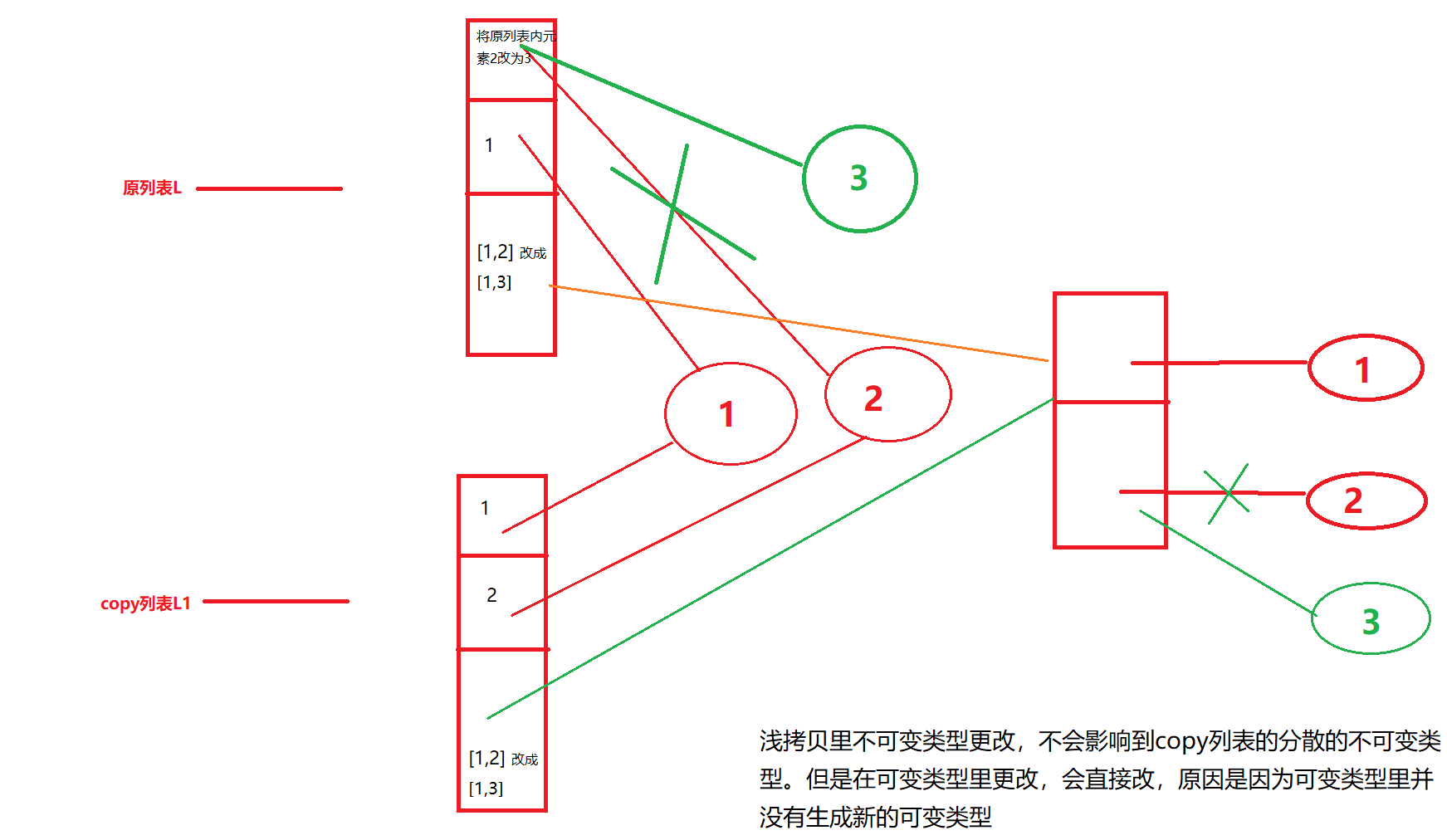
copy.copy浅拷贝:
import copy l = [1,2,[1,2]] l1 = copy.copy(l) l[1] = 3 #修改不可变类型数据 print (l)# [1,3,[1,2]] #原列表变动 print(l1) #[1,2,[1,2]] #copy列表不动 l = [1,2,[1,2]] l1 = copy.copy(l) l[2][1]= 3 #修改可变类型 print (l)# [1,2,[1,3]] 原列表变动 print(l1) #[1,2,[1,3]] copy列表也变动
图解:
深拷贝:copy.deepcopy
import copy l = [1,2,[1,2]] l1 = copy.deepcopy(l) #深拷贝 l[1] = 3 l[2][1] = 3 print(l) #[1,3,[1,3]] #原列表改变 print(l1) #[1,2,[1,2]] # copy列表不改变
图解: