在微信小程序中我们往往需要展示一些丰富的页面内容,包括图片、文本等,基本上要求能够解析常规的HTML最好,由于微信的视图标签和HTML标签不一样,但是也有相对应的关系,因此有人把HTML转换做成了一个富文本转化插件wxParse,方便我们使用,前人种树后人乘凉,我们使用它来解析HTML就很方便了,这对于我们在后端已经完成的一些HTML内容,展示在小程序里就非常不错。
这个插件的Github地址如下:wxParse-微信小程序富文本解析组件,官方称它支持支持HTML及markdown解析,我这里主要用在小程序端解析HTML内容。
1、硬编码HTML测试
首先我们根据官方网站说明,下载内容后,复制文件夹wxParse到项目目录中(这里放在utils目录中),如下所示。
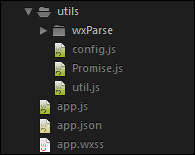
- wxParse/
-wxParse.js(必须存在)
-html2json.js(必须存在)
-htmlparser.js(必须存在)
-showdown.js(必须存在)
-wxDiscode.js(必须存在)
-wxParse.wxml(必须存在)
-wxParse.wxss(必须存在)
-emojis(可选)
然后在使用的JS文件中引入文件。
// 引入对HTML内容解析的处理类 var WxParse = require('../../utils/wxParse/wxParse.js');
接着在视图中引入样式文件,如下所示
//在使用的Wxss中引入WxParse.css,可以在app.wxss /**app.wxss**/ @import "./utils/wxParse/wxParse.wxss";
接着在视图文件中需要引入对应的模板文件,如下所示
// 引入模板 <import src="你的路径/wxParse/wxParse.wxml"/> //这里data中article为bindName <template is="wxParse" data="{{wxParseData:article.nodes}}"/>
一般我们会对模板的展示进行一定的调整,如下是我实际项目的界面代码
<!--pages/company/index.wxml--> <import src="../../utils/wxParse/wxParse.wxml"/> <view class="index"> <view class="news"> <view class="news-item line"> <view class="news-details-content wxParse"> <template is="wxParse" data="{{wxParseData:content.nodes}}"/> </view> </view> </view> </view>
前面我们在JS文件里面只是做了文件的引用,为了实现数据的展示,我们需要插件wxParse对它进行数据绑定处理,我们为了方便,先定义一个HTML文档内容在本地,方便展示处理。

在逻辑JS文件里面,我们先包含这个文件进来,如下代码所示。
// 引入内置HTML对象文件 const company = require("./company.js");
然后我们先来测试内置HTML的转换处理。
/** * 生命周期函数--监听页面加载 */ onLoad: function(options) { var that = this; //使用内置HTML展现 var data = { url: company.url, image: company.image, content: company.content }; this.setData({ item: data }); WxParse.wxParse('content', 'html', data.content, that, 25);
解析得到界面效果如下所示。

2、动态获取HTML并展示
上面我们是通过内置HTML文件的方式,然后把它包含进来,对内容进行转换显示,实际情况下,我们一般需要对内容进行动态化处理,通过请求服务器端的URL获取内容,并进行展示,如下代码所示。
//使用Comprise的封装函数展现 var url ='http://localhost:27206/api/Framework/Information/FindByCode'; var companyurl = "http://www.iqidi.com"; var json = {code: 'company'}; app.utils.get(url, json).then(res=> { var data = { url: companyurl, image: res.Picture, content: res.Content }; that.setData({ item : data }); WxParse.wxParse('content', 'html', data.content, that, 25); });
其中的app.utils.get 是对wxRequest的封装处理(使用了Promise插件),如下所示。
//封装Request请求方法 function requst(url,method,data = {}){ wx.showNavigationBarLoading() data.method = method return new Promise((resove,reject) => { wx.request({ url: url, data: data, header: {}, method: method.toUpperCase(), // OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE, CONNECT success: function(res){ wx.hideNavigationBarLoading() resove(res.data) }, fail: function(msg) { console.log('reqest error',msg) wx.hideNavigationBarLoading() reject('fail') } }) }) }
另外我们服务器返回的JSON如下所示
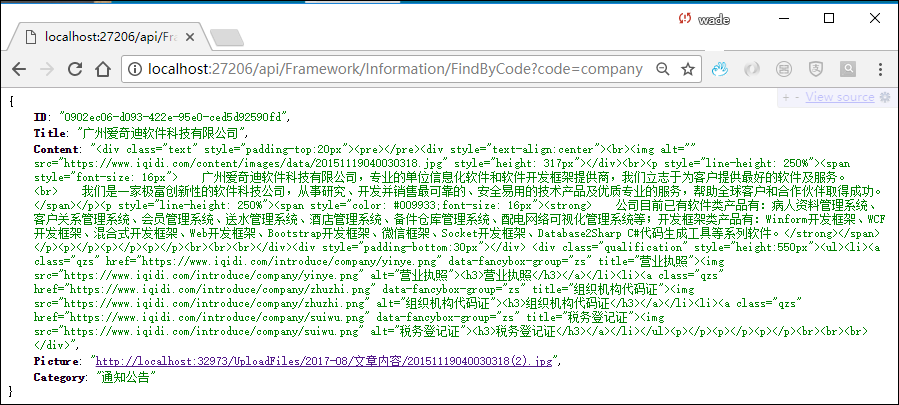
这个后台是采用C#的MVC后台生成的JSON,具体后台代码如下所示。
/// <summary> /// 通过代码获取对应的文章内容 /// </summary> /// <param name="id">产品ID</param> /// <returns></returns> [HttpGet] public ExpandoObject FindByCode(string code) { //如果需要修改字段显示,则参考下面代码处理 dynamic obj = new ExpandoObject(); var info = baseBLL.FindSingle(string.Format("Code='{0}' AND IsDoc=0 ", code)); if (info != null) { obj.ID = info.ID; obj.Title = info.Title; obj.Content = info.Content; obj.Picture = info.Picture; obj.Category = info.Category; } return obj; }
解析得到界面效果和上面的一致。
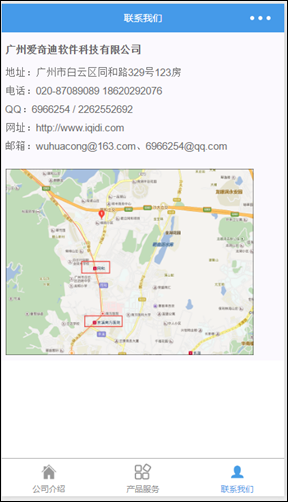
以上就是使用富文本转化插件wxParse对HTML内容进行的转换实现,这些动态内容,我们可以利用网站后台进行动态的维护即可。
文章列表管理界面如下所示:
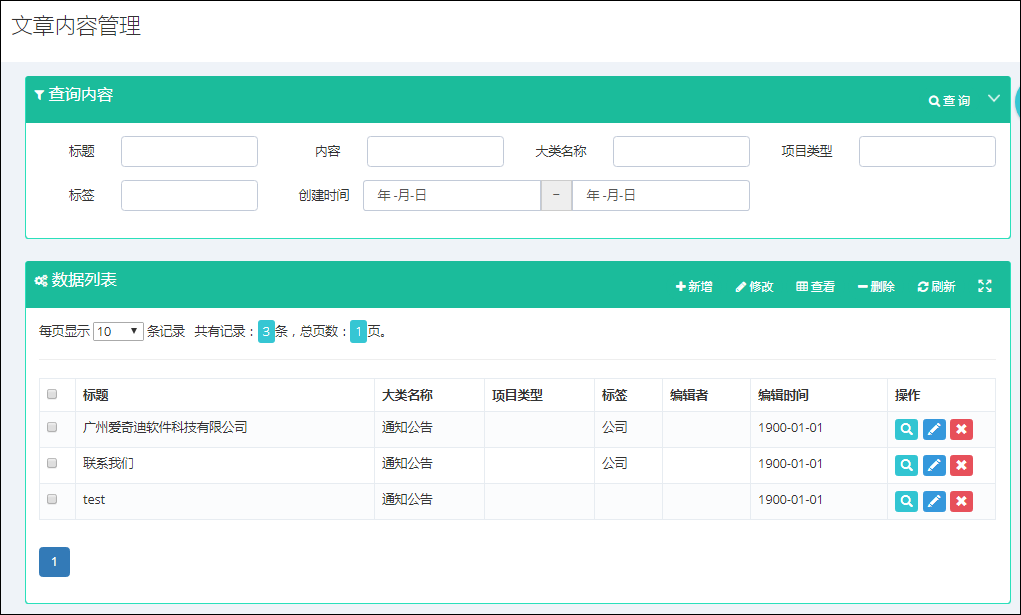
文章内容编辑界面如下所示
