集群
一、多台单节点
1、准备两台服务器,安装一模一样的rabbitmq
A服务器节点

B服务器节点

2、修改配置文件
rabbitmq配置文件
主要加入集群节点
C:UsersAdministratorAppDataRoamingRabbitMQ
[ {rabbit, [ {vm_memory_high_watermark_paging_ratio, 0.4}, {vm_memory_high_watermark, 0.4}, {cluster_nodes, ['rabbit@WIN-BN52SEDCTKA', 'rabbit@WIN-0H2D8V9NVNT']} ] } ].
3、hosts配置文件
A,B服务器均做这个配置
C:WindowsSystem32driversetc

A服务器: 192.168.140.167 rabbit@WIN-BN52SEDCTKA
B服务器: 192.168.140.142 rabbit@WIN-0H2D8V9NVNT
4、rabbitmq配置环境变量文件
A服务器:添加文件 rabbitmq-env.conf
NODENAME=rabbit@WIN-BN52SEDCTKA NODE_IP_ADDRESS=192.168.140.167 NODE_PORT=5672 RABBITMQ_MNESIA_BASE=C:UsersAdministratorAppDataRoamingRabbitMQdb RABBITMQ_LOG_BASE=C:UsersAdministratorAppDataRoamingRabbitMQlog
B服务器:添加文件 rabbitmq-env.conf
NODENAME=rabbit@WIN-0H2D8V9NVNT NODE_IP_ADDRESS=192.168.140.142 NODE_PORT=5672 RABBITMQ_MNESIA_BASE=C:UsersAdministratorAppDataRoamingRabbitMQdb RABBITMQ_LOG_BASE=C:UsersAdministratorAppDataRoamingRabbitMQlog
5、erlang.cookie文件统一
将A服务器中C:UsersAdministrator中的.erlang.cookie 的文件替换掉B服务器中 C:UsersAdministrator
和C:WindowsSystem32configsystemprofile 目录中的 .erlang.cookie。
保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的Erlang Cookie
重启服务配置集群
B服务器
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
A服务器
rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster rabbit@WIN-0H2D8V9NVNT rabbitmqctl start_app
rabbitmqctl join_cluster命令必须关闭应用,以及B服务器中对应端口必须通。
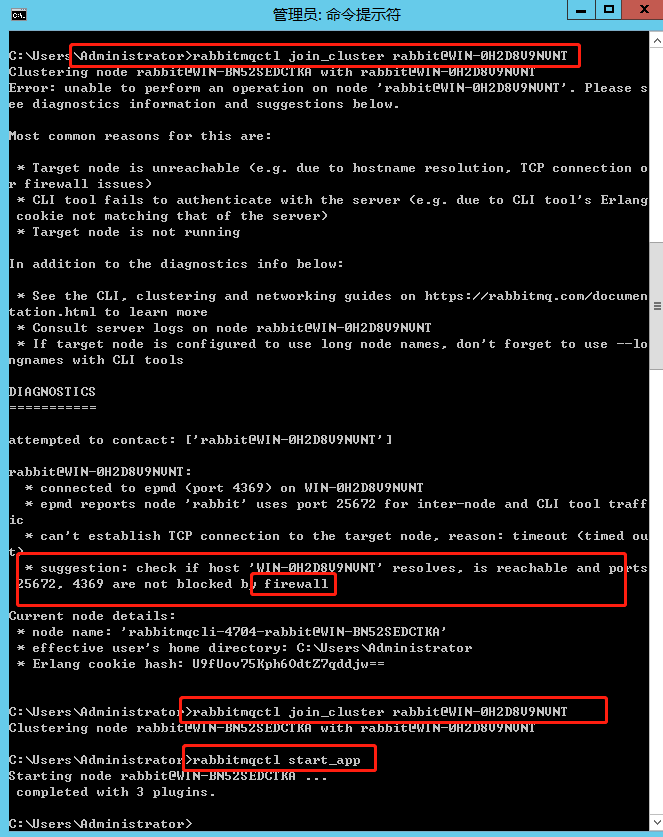
登录管理界面,看到配置成功

需要注意的是,搭建集群建议最少设置一个磁盘节点,防止机器意外关机等、丢失数据。(上面两个都是磁盘节点)
rabbitmq集群有两种节点 磁盘节点和内存节点。字面上了解,磁盘节点的数据存储在磁盘,内存节点的数据存储的内存中。因此存储速度方面内存节点有优势,数据安全方面磁盘节点有优势。
内存节点集群时的命令
rabbitmqctl join_cluster --ram rabbit@WIN-0H2D8V9NVNT
二、单台多节点
https://blog.csdn.net/zhang_jian__/article/details/69589047
消息镜像/同步
目的就是集群之间队列中信息同步 ,给A服务器发一条消息,自动同步到B服务器。
镜像是通过策略实现,把指定好的策略应用到队列。 策略的好处就是可以批量的匹配。
https://www.rabbitmq.com/ha.html
1、Ha-mode Ha-params 设置镜像队列
Ha-mode=all
同步到所有节点。当一个新的节点加入后,也会在这 个节点上复制一份。
Ha-params
镜像队列将会在集群上复制count份。如果集群数量少于count时候,队列会复制到所有节点上。如果大于Count集群,有一个节点crash后,新进入节点也不会做新的镜像。(一般ha-mode设置为all,这个就不设置就可以)
2、Ha-sync-mode 新从节点加入时 数据同步策略
ha-sync-mode=automatic (自动)
manually “手动”是默认的
自动同步会使队列在一段时间内无响应,这可能不太好取决于队列的用例.并且,只要有新的从属连接,就会发生自动同步.如果存在大量从属加入,则队列将在相当长的一段时间内无响应,除非队列相当空或网络非常快.
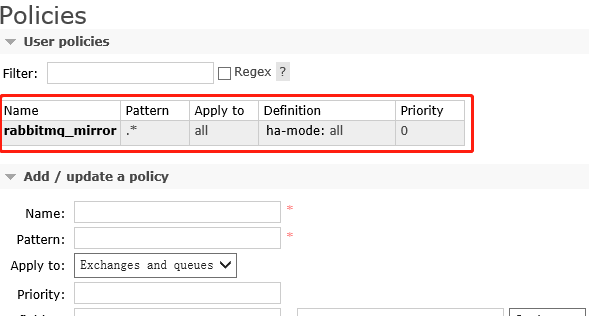
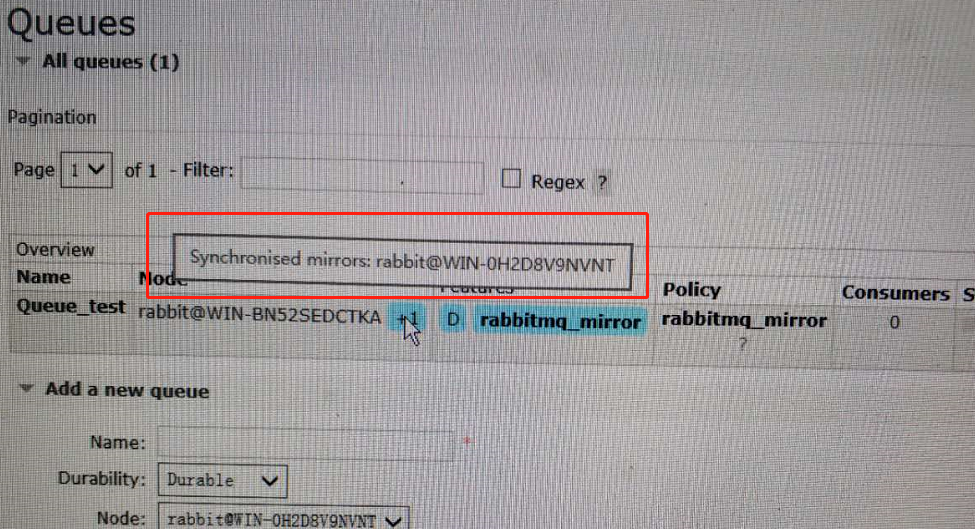
HA负载
HAProxy:在集群机制基础上可以指定集群内任意数量队列组成镜像队列,队列消息会在多节点间复制
https://blog.csdn.net/zhuyu19911016520/article/details/80206202
RabbitMQ脑裂
1、RabbitMQ 集群的网络分区容错性并不是非常高,在网络经常发生分区时会有些问题。
2、RabbitMQ 提供了三种配置:
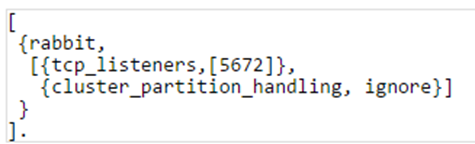
ignore:默认配置,发生网络分区时不作处理,当认为网络是可靠时选用该配置
autoheal:各分区协商后重启客户端连接最少的分区节点,恢复集群(CAP 中保证 AP,有状态丢失)
pause_minority:分区发生后判断自己所在分区内节点是否超过集群总节点数一半,如果没有超过则暂停这些节点(保证 CP,总节点数为奇数个)
CAP理论

一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容错性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。