1. 背景
Elasticsearch 在公司的使用越来越广,很多同事之前并没有接触过 Elasticsearch,所以,最近在公司准备了一次关于 Elasticsearch 的分享,整理成此文。此文面向 Elasticsearch 新手,老司机们可以撤了。
2. 倒排索引
先简单介绍下搜索引擎的基础数据结构倒排索引。
我们在平时,会经常使用各种各样的索引,如我们根据链接,可以找到链接里的具体文本,这就是索引。反过来,如果,如果我们能根据具体文本,找到文本存在的具体链接,这就是倒排索引,可简单理解为从文本到链接的映射。我们平时在使用Google、百度时,就是根据具体文本去找链接,这就是以倒排索引为基础的。
可参看维基百科 。
3. Elasticsearch 简介与基本概念
Elasticsearch is a real-time distributed search and analytics engine. It allows you to explore your data at a speed and at a scale never before possible. It is used for full-text search, structured search, analytics, and all three in combination.
在 《Elasticsearch : The Definitive Guide》里,这样介绍Elasticsearch,总的来说,Elasticsearch 是一个分布式的搜索和分析引擎,可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在是使用最广的开源搜索引擎之一,Wikipedia、Stack Overflow、GitHub 等都基于 Elasticsearch 来构建他们的搜索引擎。
先介绍下 Elasticsearch 里的基本概念,下图是 Elasticsearch 插件 head 的一个截图。

- node:即一个 Elasticsearch 的运行实例,使用多播或单播方式发现 cluster 并加入。
- cluster:包含一个或多个拥有相同集群名称的 node,其中包含一个master node。
- index:类比关系型数据库里的DB,是一个逻辑命名空间。
- alias:可以给 index 添加零个或多个alias,通过 alias 使用index 和根据index name 访问index一样,但是,alias给我们提供了一种切换index的能力,比如重建了index,取名customer_online_v2,这时,有了alias,我要访问新 index,只需要把 alias 添加到新 index 即可,并把alias从旧的 index 删除。不用修改代码。
- type:类比关系数据库里的Table。其中,一个index可以定义多个type,但一般使用习惯仅配一个type。
- mapping:类比关系型数据库中的 schema 概念,mapping 定义了 index 中的 type。mapping 可以显示的定义,也可以在 document 被索引时自动生成,如果有新的 field,Elasticsearch 会自动推测出 field 的type并加到mapping中。
- document:类比关系数据库里的一行记录(record),document 是 Elasticsearch 里的一个 JSON 对象,包括零个或多个field。
- field:类比关系数据库里的field,每个field 都有自己的字段类型。
- shard:是一个Lucene 实例。Elasticsearch 基于 Lucene,shard 是一个 Lucene 实例,被 Elasticsearch 自动管理。之前提到,index 是一个逻辑命名空间,shard 是具体的物理概念,建索引、查询等都是具体的shard在工作。shard 包括primary shard 和 replica shard,写数据时,先写到primary shard,然后,同步到replica shard,查询时,primary 和 replica 充当相同的作用。replica shard 可以有多份,也可以没有,replica shard的存在有两个作用,一是容灾,如果primary shard 挂了,数据也不会丢失,集群仍然能正常工作;二是提高性能,因为replica 和 primary shard 都能处理查询。另外,如上图右侧红框所示,shard数和replica数都可以设置,但是,shard 数只能在建立index 时设置,后期不能更改,但是,replica 数可以随时更改。但是,由于 Elasticsearch 很友好的封装了这部分,在使用Elasticsearch 的过程中,我们一般仅需要关注 index 即可,不需关注shard。
综上所述,shard、node、cluster 在物理上构成了 Elasticsearch 集群,field、type、index 在逻辑上构成一个index的基本概念,在使用 Elasticsearch 过程中,我们一般关注到逻辑概念就好,就像我们在使用MySQL 时,我们一般就关注DB Name、Table和schema即可,而不会关注DBA维护了几个MySQL实例、master 和 slave 等怎么部署的一样。
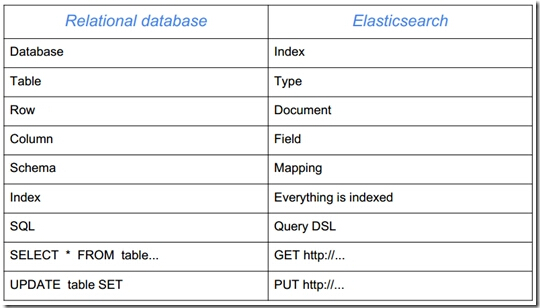
下表用Elasticsearch 和 关系数据库做了类比:
- index => databases
- type => table
- field => field
- document => record
- mapping => schema
最后,来从 Elasticsearch 中取出一条数据(document)看看:

由index、type和id三者唯一确定一个document,_source 字段中是具体的document 值,是一个JSON 对象,有5个field组成。
4. Elasticsearch 基本使用
下面介绍下 Elasticsearch 的基本使用,这里仅介绍 Elasticsearch 能做什么,而不详细介绍语法。
4.1 基础操作
- index:写 document 到 Elasticsearch 中,如果不存在,就创建,如果存在,就用新的取代旧的。
- create:写 document 到 Elasticsearch 中,与 index 不同的是,如果存在,就抛出异常
DocumentAlreadyExistException。 - get:根据ID取出document。
- update:如果是更新整个 document,可用index 操作。如果是部分更新,用update操作。在Elasticsearch中,更新document时,是把旧数据取出来,然后改写要更新的部分,删除旧document,创建新document,而不是在原document上做修改。
- delete:删除document。Elasticsearch 会标记删除document,然后,在Lucene 底层进行merge时,会删除标记删除的document。
4.2 Filter 与 Query
Elasticsearch 使用 domain-specific language(DSL)进行查询,DSL 使用 JSON 进行表示。
DSL 由一些子查询组成,这些子查询可应用于两类查询,分别是filter 和 query。
filter 正如其字面意思“过滤”所说的,是起过滤的作用,任何一个document 对 filter 来说,就是match 与否的问题,是个二值问题,0和1,没有scoring的过程。
使用query的时候,是表示match 程度问题,有scroing 过程。
另外,Filter 和 Query 还有性能上的差异,Elasticsearch 底层对Filter做了很多优化,会对过滤结果进行缓存;同时,Filter 没有相关性计算过程,所以,Filter 比 Query 快。
所以,官网推荐,作为一条比较通用的规则,仅在全文检索时使用Query,其它时候都用Filter。但是,根据我们的使用情况来看,在过滤条件不是很强的情况下,缓存可能会占用较多内存,如果这些数据不是频繁使用,用空间换时间不一定划算。
4.3 一些重要的查询
在Elasticsearch 中,有几类最重要的查询子句,掌握了就可以覆盖日常90%以上的需求。
4.3.1 match_all
{"match_all":{}}表示取出所有documents,在与filter结合使用时,会经常使用match_all。
4.3.2 match
一般在全文检索时使用,首先利用analyzer 对具体查询字符串进行分析,然后进行查询;如果是在数值型字段、日期类型字段、布尔字段或not_analyzed 的字符串上进行查询时,不对查询字符串进行分析,表示精确匹配,两个简单的例子如:
{ "match": { "tweet": "About Search" }}{ "match": { "age": 26 }}4.3.3 term
term 用于精确查找,可用于数值、date、boolean值或not_analyzed string,当使用term时,不会对查询字符串进行分析,进行的是精确查找。
{ "term": { "date": "2014-09-01" }}4.3.4 terms
terms 和 term 类似,但是,terms 里可以指定多个值,只要doc满足terms 里的任意值,就是满足查询条件的。与term 相同,terms 也是用于精确查找。
{ "terms": { "tag": [ "search", "full_text", "nosql" ] }}注意,terms 表示的是contains 关系,而不是 equals关系。
4.3.5 range
类比数据库查找的范围查找,举个简单的例子:
{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}操作符可以是:
- gt:大于
- gte:大于等于
- lt:小于
- lte:小于等于
4.3.6 exists 和 missing
exists 用于查找字段含有一个或多个值的document,而missing用于查找某字段不存在值的document,可类比关系数据库里的 is not null (exists) 和 is null (missing).
{
"exists": {
"field": "title"
}
}4.3.7 bool
前面讲的都是些最原子的查询子句,那么,怎么实现复合查询呢?Elasticsearch 使用bool 子句来将各种子查询关联起来,组成布尔表达式,bool 子句可以随意组合、嵌套。
bool子句主要包括:
- must:表示必须匹配。
- must_not:表示一定不能匹配。
- should:表示可以匹配,类似于布尔运算里的”或”。如果bool 子句里,没有must子句,那么,should子句里至少匹配一个,如果有must子句,那么,should子句至少匹配零个。可以使用
minimum_should_match来对最小匹配数进行设置。
{
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"must_not" : {
"range" : {
"age" : { "from" : 10, "to" : 20 }
}
},
"should" : [
{
"term" : { "tag" : "wow" }
},
{
"term" : { "tag" : "elasticsearch" }
}
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}4.4 聚合功能
前面说的都是 Elasticsearch 当做搜索引擎使用,Elasticsearch 还可以作为分析引擎使用。
和 MySQL 等关系数据库类似,Elasticsearch 有聚合操作,而且,可作用于大量数据,提供实时的分析结果,速度快;同时,聚合操作可以与搜索结合使用,例如将聚合作用于搜索结果等。总之,Elasticsearch的聚合功能十分强大,有很多公司利用 Elasticsearch 来做分析,其中,广泛使用的 ELK(Elasticsearch + Logstash + Kibana),Kibana的数据显示和分析功能就是基于 Elasticsearch 的聚合功能做的。
具体可参看 Elasticsearch: The Definitive Guide
4.5 Geolocation
Elasticsearch 还提供了基于地理位置的搜索,而且能将地理位置与全文检索、结构化搜索、分析等结合起来使用,比如查找距离某点一定范围内的符合搜索条件的地点、计算两点的距离、判断两个形状是否相交或包含等。
具体参考 Elasticsearch: The Definitive Guide
5. Elasticsearch 使用时注意的几个问题
深度分页问题:Elasticsearch 作为一个分布式搜索与分析引擎,深度分页问题会带来严重的问题,给CPU、内存、IO、网络带来巨大压力,所以,在Elasticsearch 不建议使用深度分页,如果要遍历数据,可以采用 SCROLL的方式,可参考我另一篇博客。
排序问题:根据某field排序时,Elasticsearch 会将这个 field 的所有值给加载到内存,然后,这部分数据会常驻内存,如果数据量大或排序字段多,就会给系统带来巨大压力,所以,在使用 field 进行排序时,要慎重。不过,在Elasticsearch 2.X版本,开始使用 doc value 来优化这部分。
terms 问题: terms 里可以传多个值,但是,量不能太多,搜索引擎的基本数据结构是倒排索引,terms 里传多个值,原理上来说是查很多的倒排索引,量大了也会给系统带来很大压力。
6 总结
本文是一篇 Elasticsearch 的入门文章,涵盖的是一些基本概念,篇幅有限,并不深入,如DSL的具体语法、聚合功能等都点到为止,希望大家知道的是Elasticsearch能干什么,具体要做的时候,再去详查就好了。
转载:http://lxWei.github.io/posts/Elasticsearch-%E7%AE%80%E4%BB%8B.html