一、前言
最近工作很繁忙,同事的离职给我带来了很多的事情,投身于博客的时间比较少,另外在宿舍住可能部分的时间要随大流,鹤立鸡群有一些不好,当然这也是给自己找借口和理由,趁着周末整理下最近的感悟;另外公司用的ElasticSearch,最近我也在探索,微服务方面暂时搁浅,待到搬出宿舍的时候在开始一波666的操作;另外随着数据量增加自己还需要去接触波大数据东西,不得说真是有些挑战和机遇,看自己如何把握了;再送给自己一句话:少找一些无用借口和理由,撸起袖子就是干!
开始今天主题读写分离;
二、为啥要用读写分离
首先明白什么是读写分离,读写分离基本原理就是将数据库的读写操作分配到不同的节点上,如下图:
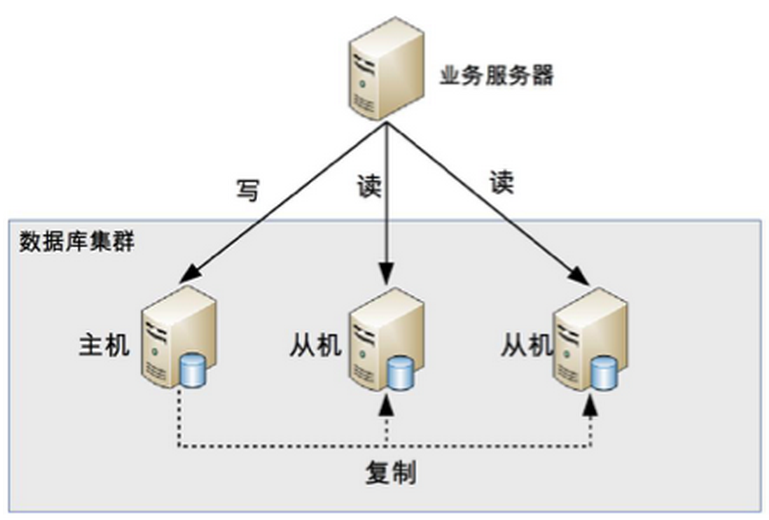
读写分离就是主从集群,一主多从或者一主一丛都是可以的,就是数据库主机复制写入操作,从机负责读的操作,主机写入以后再同步给从机;这里我简单说下当时我接触的一个项目的场景,当时我们是做了一个类似于钉钉发送内部消息用的一个东西,大概用户在30W左右,但是实际肯定不可能一起上线的,但是每次发总归会有一波大批量读取的操作和批量写入的操作,这个时候我们发现一台单机已经不够用了,那时候我们数据库和业务已经做过分离,我们就考虑用到了主从复制这一手段,在这个的基础上我们已经按照地区分表的操作,有机会我们也可以谈谈当时是怎么实现的;那段时间进步还是蛮大的,这个项目我也是花了很多心思,但是由于公司内部和很多很多原因,我看不到希望,这个项目发展以及大家迎合上层内部的原因我还是离开了,到了现在的公司,最近我把当时我的另外的想法简单进行实现,还有当时我们怎么实现的思路谈谈;
三、代码层去聊聊实现的思路
明确一点,那就是我们读的时候用从库,写的时候用主库,这一点必须要声明的,这个是我们的需求,根据这个需求我们去演化我们的代码,无非就是用两个或者多个连接字符串的,这个是C#的名词,Java的小伙伴可能不是很清楚,也就是配置2个数据DataSource,这篇文章代码层的实现主要是针对C#的,Java的话我感觉可能这种文章遍地都是,C#相对还是比较少吧,我也稍微做点贡献嘛,一下偏题了,这里在说下字符串的内容,一个是主连接字符串,另外是一个或者多个从的字符配置,我们要实现读写分离就是去实现读取的时候用从库的连接字符串,写入的时候用主库的连接字符串,说到这里我想大家应该很明确自己的思路,接下来看看我的2种思路和你的想法一样不一样,或许能给你带来一些思想上的突破;
1.写两份ORM的操作
这个怎么讲的,根据我们上面的操作来明确下两份ORM的操作指的是什么,一份是读的ORM操作,另外一份是写的ORM操作,这个时候我想你应该明白怎么去做,那就是Get操作的方法在DB层去调用读的ORM,POST的操作去调用写操作的ORM,这个我们当时就是用这种方式去实现的,我用EF还是相对比较少的,我喜欢用杰哥的Sqlsugar或者Dapper,这里我推荐下我杰哥的博客:http://www.codeisbug.com/Doc/8;这里在推荐下EF的实现,感觉这个作者也是比较用心的,https://blog.csdn.net/slowlifes/article/details/72874582,上面我们只是说进行一主一从,一组多从我们如何去实现,这个地方我们采用的类似于EF作者随机操作方式,具体大家可以去实现下,应该不是很难,我主要想要介绍我另外的想法;
2.采用AOP的方式去实现
上面的方式我感觉还是过于手动化操作,我感觉还是不是很满意,我在想有什么自动化的方式没有,这里我想到用AOP去实现,为什么能实现?AOP在MVC或者WebApi种的体现主要在于过滤器,这里面可以拿到请求的上下问,根据这个我们能拿到这个方法是GET还是POST请求,这个根据这个我们就能去区分这个请求是要定位到主库还是从库,但是这样还会存在一个问题,那就定位到以后我们必须在每个方法传入这个字符串的参数,这个代码耦合度太过于高了,不是我想要的效果,这个时候我想到ThreadLoacl这个类,这个类能干什,官方的话是提供数据的线程本地存储,这个可能你不是很明白,我用比较通俗的话给大家解释下,但是能不是很严谨,就是说每个线程id只能对应自己的变量的操作,不会影响其他变量,这个时候就解决多个用户访问的时候,正确的将这个字符串变量传递给DB层,保证了变量不会在多线程的情况下发生错误,另外也对各层之间做了解耦,这个时候我们解决了一组一丛的问题,那对于一主多从的问题我们怎么平均去分配到从库上,我采用的取余的操作,这个时候还是要解决一个问题,多线程时候的变量共享问题和原子性的问题,这个时候我采用了Interlocked对全局的变量进行新增,然后取余,就这样就能平均分配到每个从库上面了,简单的把代码贴一下,后续可以在加一些东西上github上;这个上面存在一个问题POST请求不一定是写入请求,这个地方大家可以根据自己情况自己来判断,因为在过滤器中还可以获取到Action和Controller名字,具体怎么组合看大家;


public class MasterSlaveThreadLocal { //private static volatile int slaveCount = 0; private static int slaveCount = 0; private static ThreadLocal<string> threadLocal = new ThreadLocal<string>(); private static string masterConnection = ConfigurationManager.ConnectionStrings["MasterConnection"].ToString(); private static string slaveConnection0 = ConfigurationManager.ConnectionStrings["SlaveConnection0"].ToString(); private static string slaveConnection1 = ConfigurationManager.ConnectionStrings["SlaveConnection1"].ToString(); private static string slaveConnection2 = ConfigurationManager.ConnectionStrings["SlaveConnection2"].ToString(); public static void setDataSourceKey(string httpType) { if (httpType == "GET") { Interlocked.Add(ref slaveCount, 1); if (slaveCount % 3 == 0) { threadLocal.Value = slaveConnection0; } else if (slaveCount % 3 == 1) { threadLocal.Value = slaveConnection1; } else { threadLocal.Value = slaveConnection2; } } if(httpType=="POST") threadLocal.Value = masterConnection; } public static string getDataSourceKey() { return threadLocal.Value; } } /// <summary> /// 主从过滤器 /// 设置为全局过滤器 /// </summary> public class MasterSlaveFilterAttribute: ActionFilterAttribute { public override void OnActionExecuting(ActionExecutingContext filterContext) { base.OnActionExecuting(filterContext); MasterSlaveThreadLocal.setDataSourceKey(filterContext.HttpContext.Request.HttpMethod); } } public class FilterConfig { public static void RegisterGlobalFilters(GlobalFilterCollection filters) { filters.Add(new HandleErrorAttribute()); filters.Add(new MasterSlaveFilterAttribute()); } }
四、读写分离带来的问题以及我自己的一些思考
读写分离以后,我们数据库在同步数据的时候,会存在延迟这个问题,这个延迟是数据量的增加延迟也会越来越久,但是有些业务是要求实时,那我们怎么去处理这个问题,还是举个比较例子,就按照登录来说,假设在某网站注册一个账号,该网站祖册这个业务采用的是读写分离的设计,这个时候我们在注册完成以后,需要立即登录,比如说这个延迟在2-3之间,这个时候我们做登录的时候会访问不到该注册信息,这个时候会提示该用户不存在,那么我们怎么处理这种问题,接下来我谈谈我的处理方式,当然我还是感觉这种问题还是根据业务来,如果业务没有要求必须实时,那我是提倡忽略这种问题,要是业务必须处理我认为可以从两方面处理:
1.数据库层面
数据库层面可以采用暴力读取也就是在读取一次主机的办法,什么是再读一次主机,比如说我们登录操作,如果从库读取不到,我们再次读取下主机看该条数据是否存在,这样主机压力很大,可能导致主机奔溃;
另外还有一个比较推荐的一个方式,这个方式我没有尝试过,也是我在别的地方学习到的,但是本质还是读不到读主机,我们可以这样操作,我们记录一个K-V缓存,key是由数据库:表:主键,设置过期时间大于等于数据库同步延迟的时间,当我们访问判断下有无这个key,如果存在这个则读取主库,否者读取从库;
2.从界面层面
还是以登录为案例,我们在很多网站注册完成以后,会出现这样情况,比等待几秒跳转或者阅读下什么规则,这个时候我们考虑下为什么他要这么做,当让一部分可能真的是规定,但是我们脑袋大开一下,其实这也是一种数据同步,在等待的那段时间,主从已经完成了同步,这也是我脑洞大开想的,这个大家可以当做看笑话,但是我认为还是可以尝试下;
五、结束
有什么不懂的我们可以一起探讨!!GO!
欢迎大家加我群:438836709;
欢迎大家关注我公众号:
