ELK:一套组件
1:安装elasticsearch,需要先安装jdk
(1)这里我安装的是jdk11.0.1
链接: https://pan.baidu.com/s/1E1MTgTyNFskHbahzBgNfjg 提取码: iutb
解压jdk,解压命令为#tar -zxvf openjdk-11.0.1_linux-x64_bin.tar.gz
为了使后续使用将解压的文件夹改名为jdk:#mv jdk-12.0.2/ jdk
(2):配置环境变量,输入命令
#vim /etc/profile
在文件尾部加入以下内容:
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=/$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
修改完成后,保存文件,退出。
通过source命令重新加载/etc/profile文件,使得修改后的内容生效,命令如下。
# source /etc/profile
输入java –version查看jdk版本,输出成功,这代表安装成功。

值得注意的是:export JAVA_HOME=/usr/local/jdk 这个路径是看你吧你的jdk安装在那个路径下,改为你安装的路径。
2:elasticsearch的安装
(1)去官网下载7.3版本的elasticsearch,其他组件也建议使用相同版本。选择linux版本然后上传至服务器,选择你要上传的目录,然后解压
tar -zxvf elasticsearch-7.3.0-linux-86_64.tar.gz
(2)修改配置文件
-
network.host: 0.0.0.0 这样写是全局访问,你也可以写成让某个主机访问,全局访问需要打开防火墙的端口,或者关闭防火墙
-
http.port: 9200
(3)启动elasticsearch需要非root用户
useradd test #创建用户test
groupadd test#创建组test
useradd test-g test#将用户添加到组
然后需要把该组建的权限赋予新建的非root用户
chown test:test /elasticsearch/* 这是我得文件夹
(4)启动elasticsearch
进入到elasticsearch,cd /elasticsearch/bin
然后 ./elasticsearch & 挂后台执行
注意容易出错:
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[3]:the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决:【1】:编辑 /etc/security/limits.conf,追加以下内容;
* soft nofile 65536
* hard nofile 65536
此文件修改后需要重新登录用户,才会生效
【2】:编辑 /etc/sysctl.conf,追加以下内容:
vm.max_map_count=655360
保存后,执行:
sysctl -p
重新启动,成功。
【3】:
在配置文件里面
取消注释保留一个节点
cluster.initial_master_nodes: ["node-1"]
这个的话,这里的node-1是上面一个默认的记得打开就可以了
3:安装filebeat
(1)filebeat是安装在客户端用来搜集日志的,然后把收集的日志送到logstash
(2)把压缩包上传至指定目录,解压 tar -zxvf filebeat-7.3.0.tar.gz
(3)修改配置文件 vim /filebeat/filebeat.yml
在文件末尾加上这些
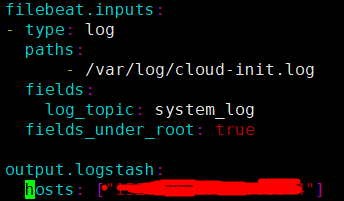
涂画的地方是logstash的ip和端口
path:是你要搜集日志的路径
需要注意的是:在配置文件里面需要把
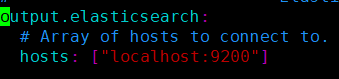
这两行注释掉,关掉一个出口
如果报-bash: ./filebeat: /lib/ld-linux.so.2: bad ELF interpreter: No such file or directory错误
解决:
sudo yum install glibc-common glibc
sudo yum install glibc.i686
4:安装logstash
(1)上传压缩包到指定目录,解压
tar -zxvf logstash-7.3.0.tar.gz
(2)新建一个配置文件,用来使用此文件启动logstash vim test.conf
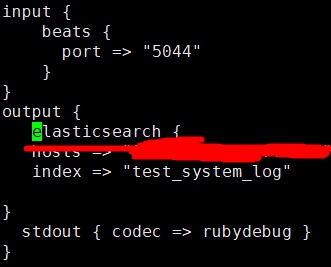
涂掉的地方是elasticsearch的地址和端口 指定输出到哪里
这是简单的配置,input是来接收filebeat传送过来的日志文件,,如果有更多需求,可以使用filter过滤功能
(3)启动
在logstash的bin目录下
./logstash -f ../test.conf & 这里我的test.conf是和bin为同级目录
5:安装kibana
(1)上传压缩包到指定目录,解压 tar -zvxf ********
(2)修改配置文件
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
如果需要汉化kibana
i18n.locale: "zh-CN"
(3)启动 在bin目录下 ./kibana & 需要注意的是 kibana也是要在非root用户下启动
(4)界面使用,
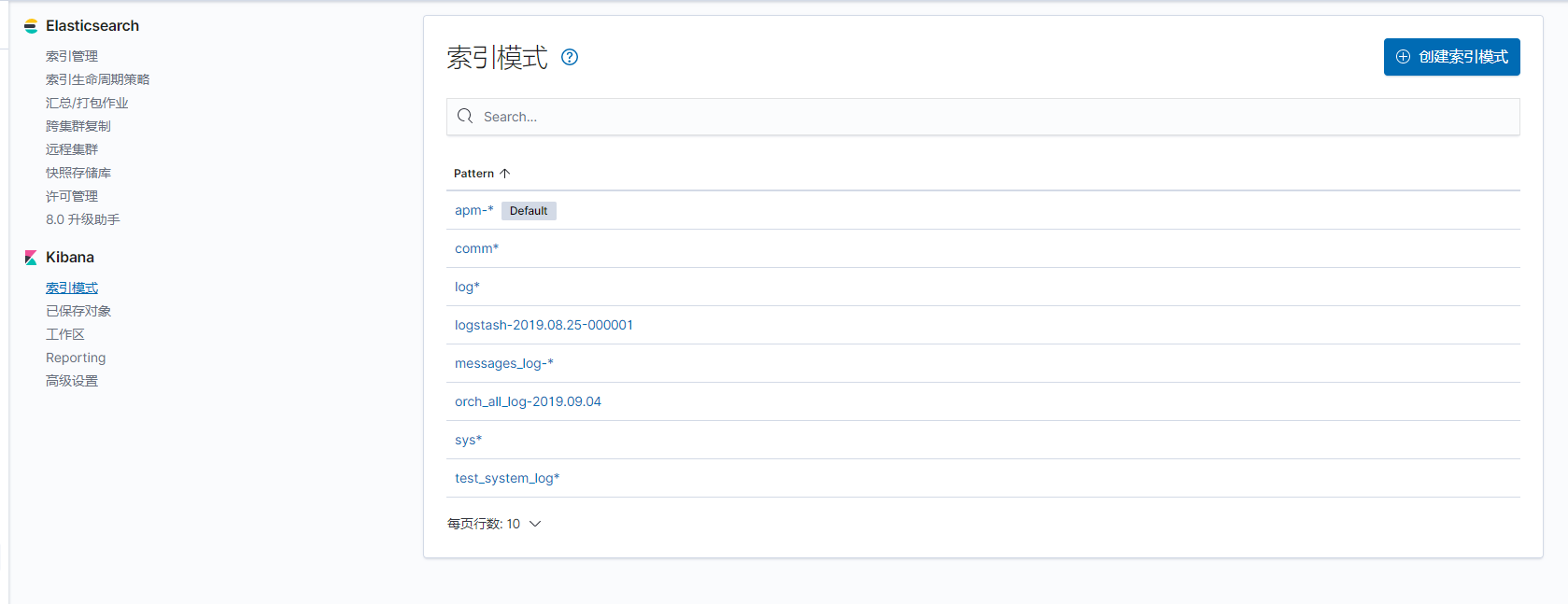
所有组件都启动后会看到在elasticsearch下的索引管理里面有你自己建立的索引,也就是在logstash配置文件里,
然后在kibana里面创建索引模式,点进去,你会看到你的索引,然后定义索引模式,例如logstash-* 点击下一步
最后需要在日志界面的配置源中,把该索引加进去
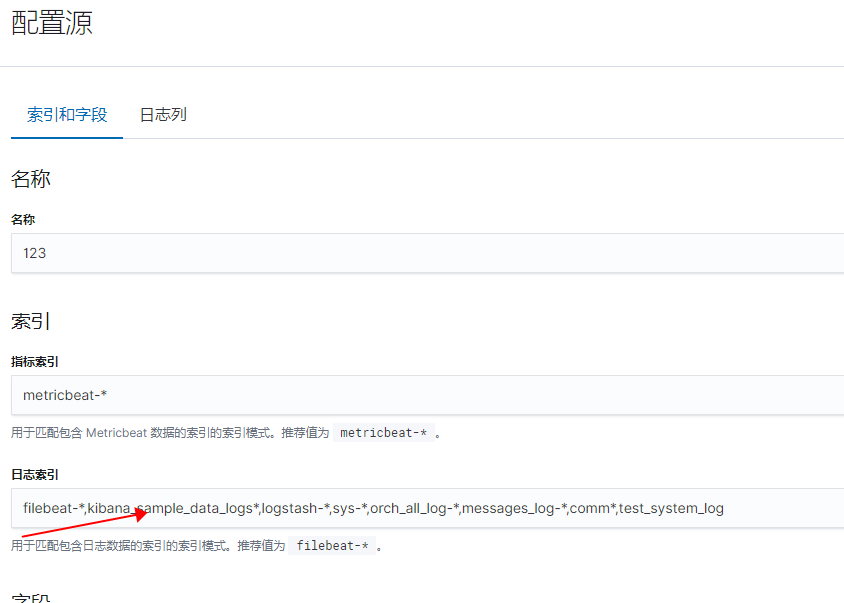
这些都是索引。
产看日志过滤使用,可以在搜索框中使用多条件联合查询
(6)告警到zabbix
(1)安装
logstash-output-zabbix是一个社区维护的插件,它默认不安装,但是它安装起来也很容易,直接在logstash中运行即可:
bin/logstash-plugin install logstash-output-zabbix
(2)配置logstash文件
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "%{IP:remote_addr} (?:%{DATA:remote_user}|-) [%{HTTPDATE:timestamp}] %{IPORHOST:http_host} %{DATA:request_method} %{DATA:request_uri} %{NUMBER:status} (?:%{NUMBER:body_bytes_sent}|-) (?:%{DATA:request_time}|-) "(?:%{DATA:http_referer}|-)" "%{DATA:http_user_agent}" (?:%{DATA:http_x_forwarded_for}|-) "(?:%{DATA:http_cookie}|-)""}
}
mutate {
add_field => [ "[@metadata][zabbix_key]" , "logstash-api-access" ] 在消息中添加zabbix中item的key值
add_field => [ "[@metadata][zabbix_host]" , "EIP_weixin" ] 在消息中添加zabbix中的host值,主机名
}
}
output {
elasticsearch {
hosts => ["10.1.129.101:9200"]
index => "logstash-wxself.gtafe.com_10.1.134.60"
}
if [message] =~ /(ERR|error|ERROR|Failed)/ {
zabbix {
zabbix_host => "[@metadata][zabbix_host]"
zabbix_key => "[@metadata][zabbix_key]"
zabbix_server_host => "10.1.134.220"
zabbix_server_port => "10051"
zabbix_value => "message"
}
}
stdout { codec => rubydebug }
}
(3)然后在zabbix web界面建立模板。监控项,触发器
需要注意的是,监控项要设置成zabbix采集器,设置成字符类型(设置文本类型不行,不知道什么原因),触发器设置为
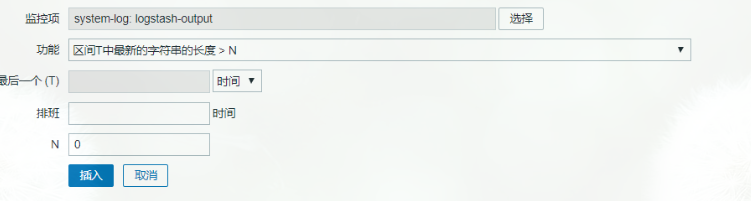
设置完后可以测试一下,需要你在采集日志的主机上安装zabbix agent,命令如下:
/usr/local/zabbix/bin/zabbix_sender -z 10.1.134.220 -vv -s "EIP_weixin" -k logstash-api-access -o "Aug"
-z代表是 zabbix server 地址 -vv 是 详细显示 -s 是主机名 -k 是键值 -o 是 传输值