数据库的调用方式是先获取数据库的连接,然后依靠这条连接从数据库中查询数据,最后关闭连接释放数据库资源。这种调用方式下,每次执行SQL都需要重新建立连接,频繁地建立数据库连接耗费时间长导致了访问慢的问题。
那么为什么频繁创建连接会造成响应时间慢呢?来看一个实际的测试。
我用"tcpdump -i bond0 -nn -tttt port 4490"命令抓取了线上MySQL建立连接的网络包来做分析,从抓包结果来看,整个MySQL的连接过程可以分为两部分:
第一部分是前三个数据包。第一个数据包是客户端向服务端发送的一个“SYN”包,第二个包是服务端回给客户端的“ACK”包以及一个“SYN”包,第三个包是客户端回给服务端的“ACK”包,熟悉TCP协议的同学可以看出这是一个TCP的三次握手过程。
第二部分是MySQL服务端校验客户端密码的过程。其中第一个包是服务端发给客户端要求认证的报文,第二和第三个包是客户端将加密后的密码发送给服务端的包,最后两个包是服务端回给客户端认证OK的报文。从图中,你可以看到整个连接过程大概消耗了4ms(969012-964904)。

用连接池预先建立数据库连接
其实,在开发过程中我们会用到很多的连接池,像是数据库连接池、HTTP连接池、Redis连接池等等。而连接池的管理是连接池设计的核心,我就以数据库连接池为例,来说明一下连接池管理的关键点。
数据库连接池有两个最重要的配置:最小连接数和最大连接数,它们控制着从连接池中获取连接的流程:
- 如果当前连接数小于最小连接数,则创建新的连接处理数据库请求;
- 如果连接池中有空闲连接则复用空闲连接;
- 如果空闲池中没有连接并且当前连接数小于最大连接数,则创建新的连接处理请求;
- 如果当前连接数已经大于等于最大连接数,则按照配置中设定的时间(C3P0的连接池配置是checkoutTimeout)等待旧的连接可用;
- 如果等待超过了这个设定时间则向用户抛出错误。
在这里,你需要注意池子中连接的维护问题,出现问题原因可能有以下几种:
1.数据库的域名对应的IP发生了变更,池子的连接还是使用旧的IP,当旧的IP下的数据库服务关闭后,再使用这个连接查询就会发生错误;
2.MySQL有个参数是“wait_timeout”,控制着当数据库连接闲置多长时间后,数据库会主动的关闭这条连接。这个机制对于数据库使用方是无感知的,所以当我们使用这个被关闭的连接时就会发生错误。
用线程池预先创建线程
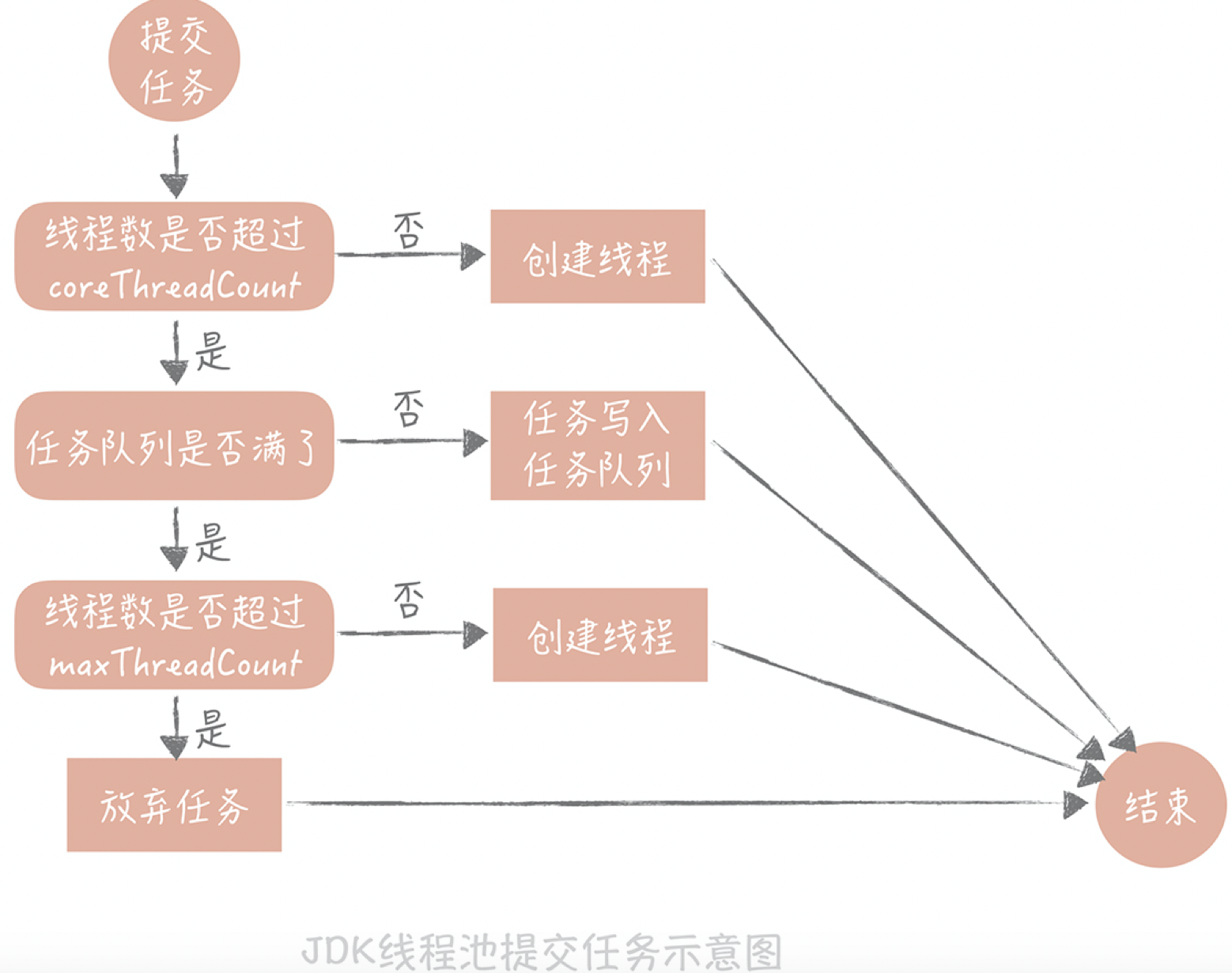
JDK 1.5中引入的ThreadPoolExecutor就是一种线程池的实现,它有两个重要的参数:coreThreadCount和maxThreadCount,这两个参数控制着线程池的执行过程。
- 如果线程池中的线程数少于coreThreadCount时,处理新的任务时会创建新的线程;
- 如果线程数大于coreThreadCount则把任务丢到一个队列里面,由当前空闲的线程执行;
- 当队列中的任务堆积满了的时候,则继续创建线程,直到达到maxThreadCount;
- 当线程数达到maxTheadCount时还有新的任务提交,那么我们就不得不将它们丢弃了。
这个任务处理流程看似简单,实际上有很多坑,你在使用的时候一定要注意。
首先, JDK实现的这个线程池优先把任务放入队列暂存起来,而不是创建更多的线程,它比较适用于执行CPU密集型的任务,也就是需要执行大量CPU运算的任务。这是为什么呢?因为执行CPU密集型的任务时CPU比较繁忙,因此只需要创建和CPU核数相当的线程就好了,多了反而会造成线程上下文切换,降低任务执行效率。所以当当前线程数超过核心线程数时,线程池不会增加线程,而是放在队列里等待核心线程空闲下来。
但是,我们平时开发的Web系统通常都有大量的IO操作,比方说查询数据库、查询缓存等等。任务在执行IO操作的时候CPU就空闲了下来,这时如果增加执行任务的线程数而不是把任务暂存在队列中,就可以在单位时间内执行更多的任务,大大提高了任务执行的吞吐量。所以你看Tomcat使用的线程池就不是JDK原生的线程池,而是做了一些改造,当线程数超过coreThreadCount之后会优先创建线程,直到线程数到达maxThreadCount,这样就比较适合于Web系统大量IO操作的场景了,你在实际运用过程中也可以参考借鉴。
其次,线程池中使用的队列的堆积量也是我们需要监控的重要指标,对于实时性要求比较高的任务来说,这个指标尤为关键。
我在实际项目中就曾经遇到过任务被丢给线程池之后,长时间都没有被执行的诡异问题。最初,我认为这是代码的Bug导致的,后来经过排查发现,是因为线程池的coreThreadCount和maxThreadCount设置的比较小,导致任务在线程池里面大量的堆积,在调大了这两个参数之后问题就解决了。跳出这个坑之后,我就把重要线程池的队列任务堆积量,作为一个重要的监控指标放到了系统监控大屏上。
最后,如果你使用线程池请一定记住不要使用无界队列(即没有设置固定大小的队列)。也许你会觉得使用了无界队列后,任务就永远不会被丢弃,只要任务对实时性要求不高,反正早晚有消费完的一天。但是,大量的任务堆积会占用大量的内存空间,一旦内存空间被占满就会频繁地触发Full GC,造成服务不可用,我之前排查过的一次GC引起的宕机,起因就是系统中的一个线程池使用了无界队列。
理解了线程池的关键要点,你在系统里加上了这个特性,至此,系统稳定,你圆满完成了公司给你的研发任务。
这时,你回顾一下这两种技术,会发现它们都有一个共同点:它们所管理的对象,无论是连接还是线程,它们的创建过程都比较耗时,也比较消耗系统资源。所以,我们把它们放在一个池子里统一管理起来,以达到提升性能和资源复用的目的。
这是一种常见的软件设计思想,叫做池化技术,它的核心思想是空间换时间,期望使用预先创建好的对象来减少频繁创建对象的性能开销,同时还可以对对象进行统一的管理,降低了对象的使用的成本,总之是好处多多。
不过,池化技术也存在一些缺陷,比方说存储池子中的对象肯定需要消耗多余的内存,如果对象没有被频繁使用,就会造成内存上的浪费。再比方说,池子中的对象需要在系统启动的时候就预先创建完成,这在一定程度上增加了系统启动时间。
可这些缺陷相比池化技术的优势来说就比较微不足道了,只要我们确认要使用的对象在创建时确实比较耗时或者消耗资源,并且这些对象也确实会被频繁地创建和销毁,我们就可以使用池化技术来优化。