数据一致性问题:消费一致性和存储一致性
例如:一个leader 写入 10条数据,2个follower(都在ISR中),F1、F2都有可能被选为Leader,例如选F2 .后面Leader又活了。可能造成每个副本数据不一致
F1 8条
F2 9条
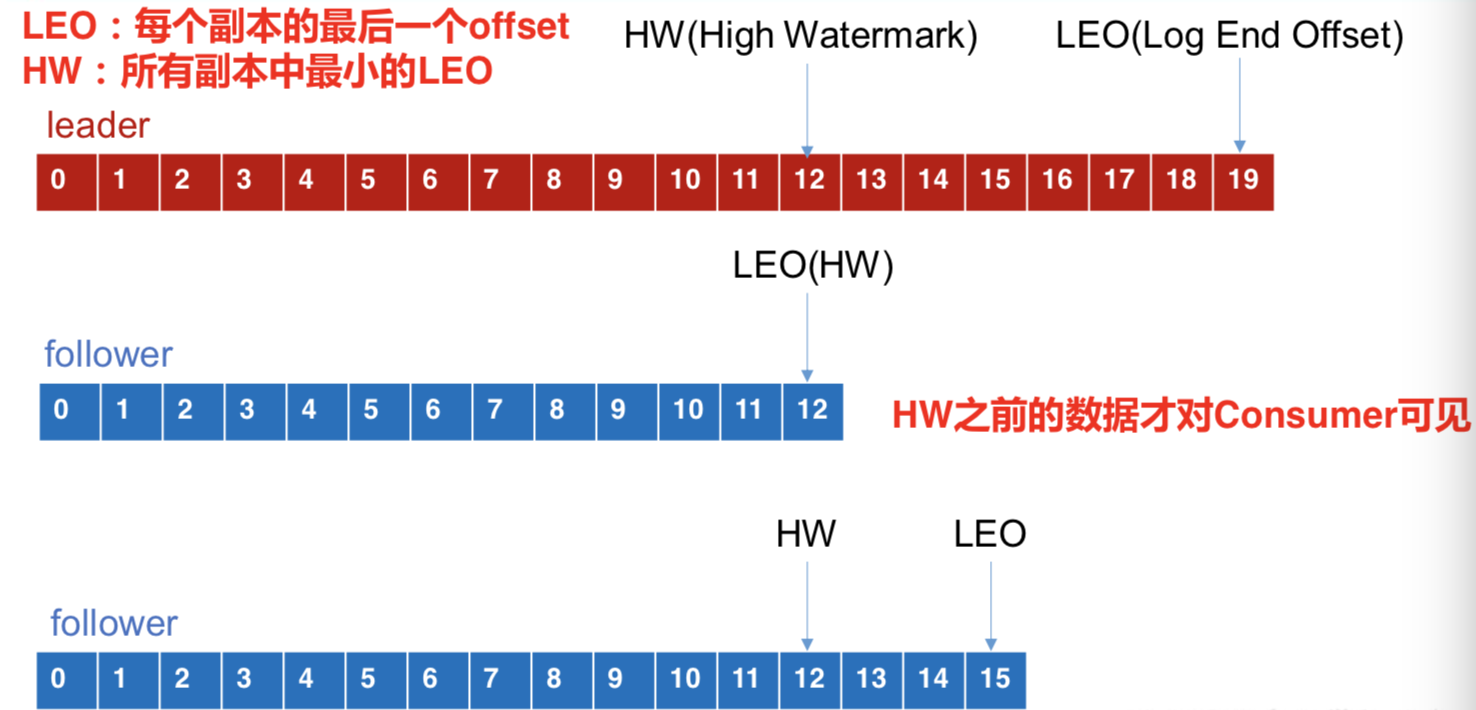
LEO:每个副本的最后一个offset。例如 F1的LEO为8, F2的LEO为9
HW(High Watermark):所有副本中最小的LEO。
LEO:指的是每个副本最大的 offset;
HW:指的是消费者能见到的最大的 offset,ISR 队列中最小的 LEO。
为啥要引入HW?
假设没有HW,消费者消费leader到19,下面消费者应该消费20。
此时leader挂掉。选下面某个follower为leader,此时消费者找新leader消费数据,发现新Leader没有20数据,报错。
1、如果leader故障
leader 发生故障之后,会从 ISR 中选出一个新的 leader。之后,为保证多个副本之间的
数据一致性(各个副本存储一致性),其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader 同步数据。
假设图中follower2被选为leader,那么其余follower都截取到HW,leader不截取。并让其余follower同步新leader。
2、follower 故障
follower 发生故障后会被临时踢出 ISR,待该 follower 恢复后,follower 会读取本地磁盘 记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 leader 进行同步。
等该 follower 的 LEO 大于等于该 Partition 的 HW,即 follower 追上 leader 之后,就可以重 新加入 ISR 了。