一 变量类型
1.0 注释
# 单行注释
'''多行注释'''
"""多行注释"""
1.1 字符串
字典和字符串
字符串转字典:str1 = "{'key':1,'value':2}"eval()
01 内置函数eval() 实现str 和list tuple dict相互转化
# eval() 内置函数 str 和 list tuple dict相互转化
data = "{'key1':'a','key2':2}"
str2dict = eval(data)
print("str2dict: ",str2dict) # {'key1': 'a', 'key2': 2}
print("str2dict数据类型是: ",type(str2dict)) # <class 'dict'>02 json.dumps()和json.loads()对简单的数据类型进行编解码
json编码中:python原始类型到json类型的转化对照表
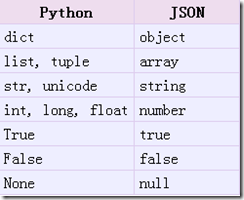
# json.dumps() dict编码为json
dictD = {'key1': 'a', 'key2': 2} --》{"key1": "a", "key2": 2}
dict2json = json.dumps(dictD)
print("dict2json: ",dict2json) # {"key1": "a", "key2": 2}
print("dict2json数据类型是: ",type(dict2json)) # <class 'str'>json解码中:json类型到python原始类型转化对照表
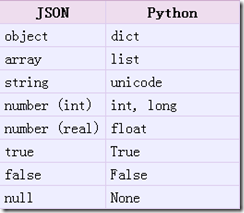
data2 = '{"key1":"c","key2":4}'# 里边只能是双引号,单引号会报错,如'{'a':1}'
json2dict = json.loads(data2)
print("json2dict: ",json2dict)
print("json2dict数据类型是: ",type(json2dict))
str='{'a':1}' 想转化成json格式,需要先转成dict
'{'a':1}'--》{'a':1}-->{"a":1}
{'a':1} = eval('{'a':1}')
{"a":1} = json.dumps({'a':1})1.2 列表 list
列表的索引 取头不取尾
lst = ['a','b',1,0]
lst.append('c') ['a','b',1,0.'c']
lst.pop(0) ['b',1,0,'c']
lst[0]-->a; lst[1:3]---> b ,1 ; lst[:3] ---> a,b,1; lst[1:] --> b, 1, 0; lst[:] ---> a,b,1,0
lst[-1]-->0; lst[-3:-1] --->b,1 ; lst[:-1] --> a,b,1 ; lst[-2:] ---> 1,0
lst[1:-1]-->b, lst[-4:2]---> a,b
列表遍历
# 普通迭代
for i in lst:
print(i)
# 带索引的迭代
for index,value in enumerate(lst):
print("index: ",index,"value: ",value)
# 拓展场景(1)多列表迭代
# 01 循环嵌套 缺点:代码复杂度高
xl,yl,zl = ['a'],['b'],['c']
for x in xl:
for y in yl:
for z in zl:
print(z)
print(y)
print(x)
# 02 intertools 标准库 缺点:不方便调试
from itertools import product
for x,y,z in product(xl,yl,zl):
print(x,y,z)
# 拓展场景(2)交集、并集、补集
a=[2,3,4,5]
b=[2,5,8]
# 交集
ls1 = list(set(a).intersection(set(b)))
print("交集:",ls1)
# 并集
ls2 = list(set(a).union(set(b)))
print("并集:",ls2)
# 差集
ls3 = list(set(b).difference(set(a))) # b中有而a中没有的
ls4 = list(set(a).difference(set(b))) # a中有而b中没有的
print("以b为底,a的补集:",ls3)
print("以a为底,b的补集:",ls4)
交集: [2, 5]
并集: [2, 3, 4, 5, 8]
以b为底,a的补集: [8]
以a为底,b的补集: [3, 4]
1.3 元组 tuple
一旦创建,不可修改,但是两个元组之间可以合并
t1 = (1, 2, 3)
t2 = (4, 5, 6)
print(t1+t2) # (1, 2, 3, 4, 5, 6)注:元组和列表区别
列表是动态数组,内容和长度可变
元组是静态数组,内容和长度都不可变
元组缓存于Python运行时环境,这意味着我们每次使用元组时无须访问内核去分配内存。
1.4 字典 dict
取值
personinfo = {'name': 'joe', 'age':'20', 'hobby':'football'}
print(personinfo['name']) # joe遍历迭代
personinfo = {'name': 'joe', 'age':'20', 'hobby':'football'}
print(personinfo['name'])
print(personinfo.items()) # dict_items([('name', 'joe'), ('age', '20'), ('hobby', 'football')])
for k,v in personinfo.items():
print(k,v)
# 结果
name joe
age 20
hobby football使用场景
dict1 = {'a': 10, 'b': 8}
dict2 = {'d': 6, 'c': 4}
#合并/复制
dictMerge = {**dict1,**dict2}
print(dictMerge)
#增添字段
dict1 = {**dict1,'A':20}
dict2.update({'D':3})
print(("添加字段后 dict1是:%s dict2是:%s") % (dict1,dict2))
# 重写字段的值
dict1 = {**dict1,'a':100}
print(dict1)
合并:{'a': 10, 'b': 8, 'd': 6, 'c': 4}
添加字段后 dict1是:{'a': 10, 'b': 8, 'A': 20} dict2是:{'d': 6, 'c': 4, 'D': 3}
更改a的值为100: {'a': 100, 'b': 8, 'A': 20}
实用场景2: dict和json相互转换
import json
dict5 = {'a':1,'key':'v'}
dict2json = json.dumps(dict5)
json2dict = json.loads(dict2json)
print("dict2json值是: ",dict2json) # dict2json值是: {"a": 1, "key": "v"}
print("json2dict值是: ",json2dict) # json2dict值是: {'a': 1, 'key': 'v'}1.5 拓展
isinstance: 用来判断对象的类型,也可以判断一个对象是否是一个类的实例
# 【常用场景1】:判断对象的类型
py_int = 1
py_str = 'a'
py_list = ['a','b']
py_dict = {'a':1,'b':2}
print(isinstance(py_int, int))
# 【常用场景2】:一个对象是否是一个类的实例
class C():
pass
cc = C()
print(isinstance(cc, C))
# 运行结果
True
Trueformat: 用于组长和格式化数据
# 字符串
str1 = "{} {}".format("hello","world") # 不指定位置
str2 = "{1} {0}".format("hello","world") # 指定位置
print(str1,"\n",str2)
# 列表
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0}, 地址 {1}".format(my_list[0],my_list[1]))
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
# 字典
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{0}, 地址 {1}".format(site['name'],site['url']))
print("网站名:{name}, 地址 {url}".format(**site))
#运行结果
hello world
world hello
网站名:菜鸟教程, 地址 www.runoob.com
网站名:菜鸟教程, 地址 www.runoob.com
网站名:菜鸟教程, 地址 www.runoob.com
网站名:菜鸟教程, 地址 www.runoob.com
二 语句 方法 类
2.1 条件语句
2.2 循环语句
while:
for :
for i in range():
range(start=0,stop,step=1) start 默认为0,step步长默认为1,
# step = 2
for i in range(0,5,2):
print("步长为2 ",i)
# step = -2,
for i in range(8,0,-2):
print("步长为-2 ",i) # 8,6,4,2
# 应用场景一:实现字符串倒序输出
name = "abc"
rename = ""
for i in range(len(name)-1,-1,-1):
print(name[i])
rename += name[i]
print(rename) # rename = "cba"2.3 方法
2.4 类
# 创建类
class Employee
empCount = 0
def __init__(self,name,salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayInfo(self):
print "name: ",self.name,"salary: ",self.salary, "empCount; ",self.empCount
# __init__(),被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法
# self 代表类的实例,代表当前对象的地址,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。
# self.__class__ 则指向类。
# 创建实例对象
"创建 Employee 类的第一个对象"
emp1 = Employee("Zara", 2000)
"创建 Employee 类的第二个对象"
emp2 = Employee("Manni", 5000)
emp1.displayInfo() # 访问属性
empCounts = Employee.empCount
# 可以添加,删除,修改类的属性
emp1.age = 20
print(emp1.age) # 20
del emp1.age
print(hasattr(emp1,'age')) # False
hasattr(emp1, 'age') # 如果存在 'age' 属性返回 True。
getattr(emp1, 'age') # 返回 'age' 属性的值
setattr(emp1, 'age', 8) # 添加属性 'age' 值为 8
delattr(emp1, 'age') # 删除属性 'age'单下划线、双下划线、头尾双下划线说明:
-
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似 __init__() 之类的。
-
_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
-
__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
三 文件的读写和异常处理
3.1 文件的读写
file.truncate(size) 截取文件,截取的字节通过size指定,从首行开始截取,
size不填写则,默认为当前文件位置。
f = open("main.py",'r+')
print(f.name)
# print(f.read(size)) size可有可无
# print(f.readline(size)) size可有可无, 读取整行包括 \n
print(f.readlines()) # ['\n', ' aaaaa'] 每一行放入列表中
f.write("\n aaaaa") # 返回的是写入字符串的长度
f.writelines() # f.writelines(seq), seq必须是字符串列表["a \n","b"]如果需要换行则要自己加入每行的换行符。
f.close()
'''
r 只读,文件指针在开头
r+ 读写,文件指针在开头
w 只写,文件指针在开头,如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
w+ 读写,文件指针在开头,如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
a 只写,追加内容。文件指针在结尾,如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+ 读写,文件指针在结尾,如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
'''
with open("main.py","r") as f:
print(f.readline())3.2 异常处理
try:
<statements> # main action
except <name1>: # 当try中发生name1的异常时处理
<statements>
except (name2, name3): # 当try中发生name2或name3中的某一个异常的时候处理
<statements>
except <name4> as <data>: # 当try中发生name4的异常时处理,并获取对应实例
<statements>
except: # 其他异常发生时处理
<statements>
else: # 没有异常发生时处理
<statements>
finally: # 不管有没有异常发生都会处理
<statements>
def main():
try:
number1, number2 = eval(input("分别输入两个数字(用逗号隔开):"))
result = number1 / number2
print("它们的商是:", result)
except ZeroDivisionError:
print("除以0,错误!")
except SyntaxError:
print("数字间未输入逗号!")
except:
print("输入出错了!")
else:
print("没有错误!")
finally:
print("已执行完!")
main()四 进程和线程
4.1 进程
4.2 线程
f"aaa{page}":https://blog.csdn.net/qq_35290785/article/details/90634344
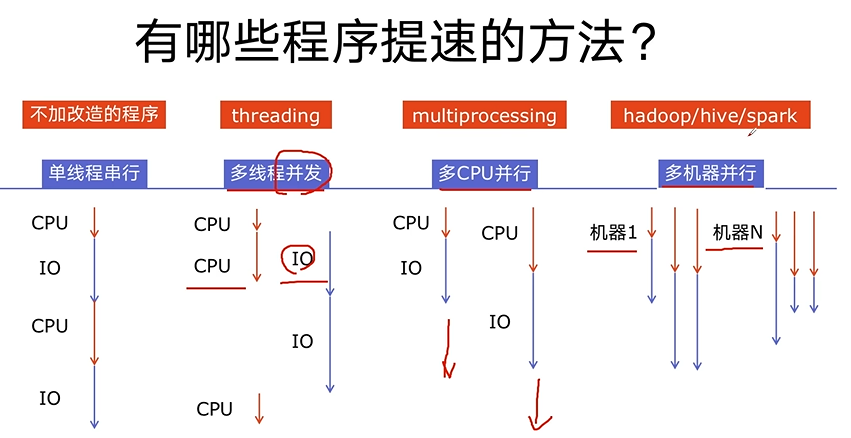



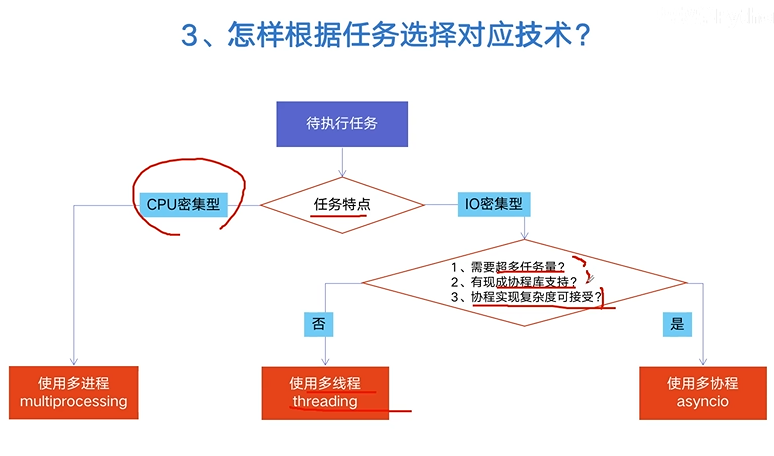

GIL
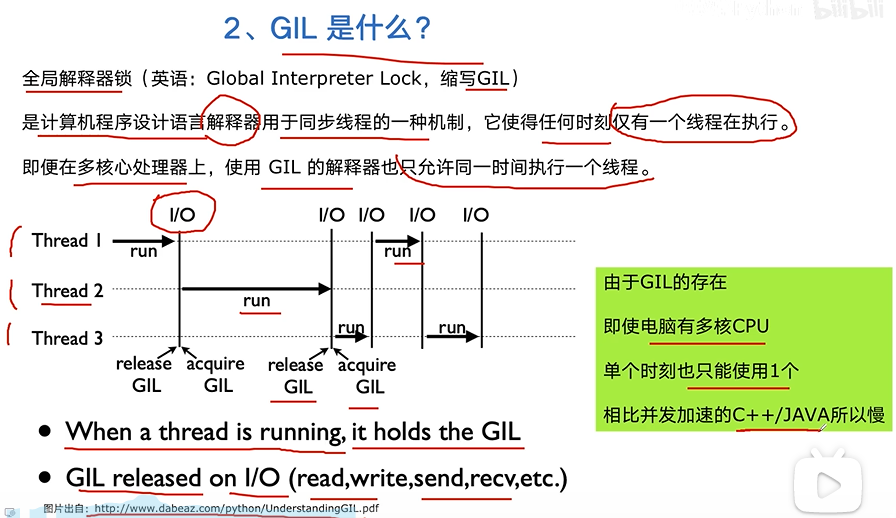
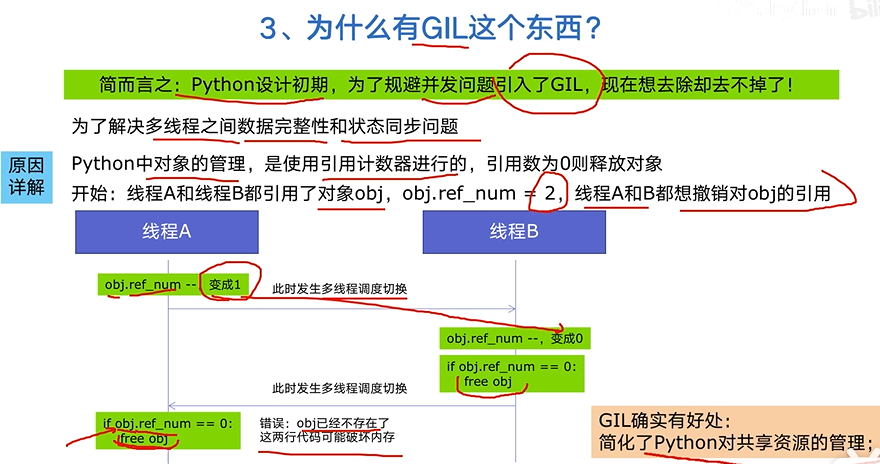
生产者消费者爬虫
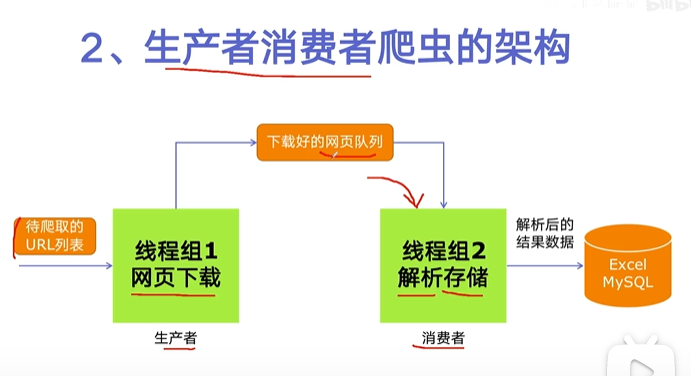
多线程数据通信 queue.Queue()
q.put() q.get()会发生阻塞
当队列满的时候put不进去,
当队列空的时候,get不到元素

线程安全:
gil 也不能保证线程安全,https://zhuanlan.zhihu.com/p/311877485
CPython 中还有另一个机制,叫做 check_interval,意思是 CPython 解释器会去轮询检查线程 GIL 的锁住情况。每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才能有执行的机会。


关于github设置
pycharm 集成git github
https://www.cnblogs.com/chenxiaomeng/p/14598391.html
https://blog.csdn.net/weixin_44505553/article/details/108800876?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~aggregatepage~first_rank_ecpm_v1~rank_v31_ecpm-3-108800876.pc_agg_new_rank&utm_term=%E6%97%A0%E6%B3%95%E5%B0%86git+%E8%AF%86%E5%88%AB%E4%B8%BAcmdlet&spm=1000.2123.3001.4430
error: Failed to connect to 127.0.0.1 port 1080 after 2078 ms: Connection refused
https://blog.csdn.net/weixin_41010198/article/details/87929622
参考资料:
https://mp.weixin.qq.com/s/vfxbNZcw6Uy4jFlI5VlmDA
https://www.runoob.com/python3/python-merging-two-dictionaries.html