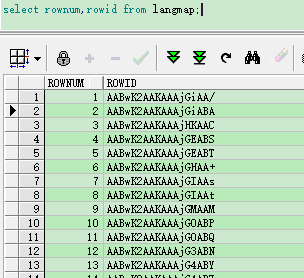
1.序列、唯一标识
查询时,可以添加递增序列 rownum
表的数据每一行都有一个唯一的标识 rowid
2.函数
单行:查询多条数据
如:to_date()
多行:查询总结数据,一般用于group by
如:sum()
3.去重 distinct
select distinct from tablename
4.分区 partition
select tenantcode,row_number() over(partition by tenantcode order by tenantcode, brandcode, storecode ) groupid from tablename
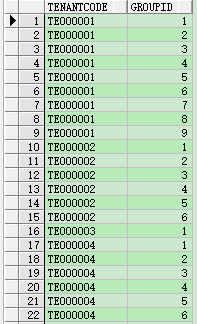
若要分区筛选出id=1的,可以
select * from( select tenantcode,row_number() over(partition by tenantcode order by tenantcode, brandcode, storecode) groupid from tablename
) where groupid=1
row_number为直接排序,还可以替换成以下函数
rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
5.行列转换
模拟表
With t as ( Select 1 id,'桃子' name,100 q1,200 q2,300 q3,400 q4 from dual Union Select 2 id,'苹果' name,111 q1,222 q2,333 q3, 444 q4 from dual Union Select 3 id,'西瓜' name,123 q1,234 q2,345 q3,456 q4 from dual )

列转行
Select * from t unpivot(nums for jidu in (q1,q2,q3,q4)) order by id;

行转列
With t as ( Select 1 id,'桃子' name,100 q1,200 q2,300 q3,400 q4 from dual Union Select 2 id,'苹果' name,111 q1,222 q2,333 q3, 444 q4 from dual Union Select 3 id,'西瓜' name,123 q1,234 q2,345 q3,456 q4 from dual ), bb as( Select * from t unpivot(nums for jidu in (q1,q2,q3,q4)) order by id ) Select * from bb pivot(max(nums) for jidu in ('Q1' Q1,'Q2' Q2,'Q3' Q3,'Q4' Q4)) --这里的max是如果有多行,选择最大,比如桃子有两个Q1

6.null值置顶或垫底
select * from langmap order by lang4 nulls first/last
6.存在则更新,不存在则新增
merge into v5_tenant_repair_appl_follow f using (select '2018111219530688462' ra_id,'test' ra_staffcode from dual) n on(f.ra_id=n.ra_id) when matched then update set f.ra_staffcode=n.ra_staffcode when not matched then insert values(n.ra_id,n.ra_staffcode)
7.占比
select a.ra_id,a.ra_charge, ratio_to_report(a.ra_charge) over() pct from v5_tenant_repair_appl a
pct表示该行的ra_charge所占比例
over():可以用参数 partition by [字段] 进行分组,从而查询分组后ra_charge所占比例
8.选择第一个非空数据
select coalesce(null,null,1,null) from dual;
9.字节替换
select translate('ab123', 'abcdefg123', '3456789abc') from dual;
第一个参数:输入的字符串
第二个参数、第三个参数:替换规则,字节按顺序一一对应替换
上式代码结果:34abc