目标url 有道翻译
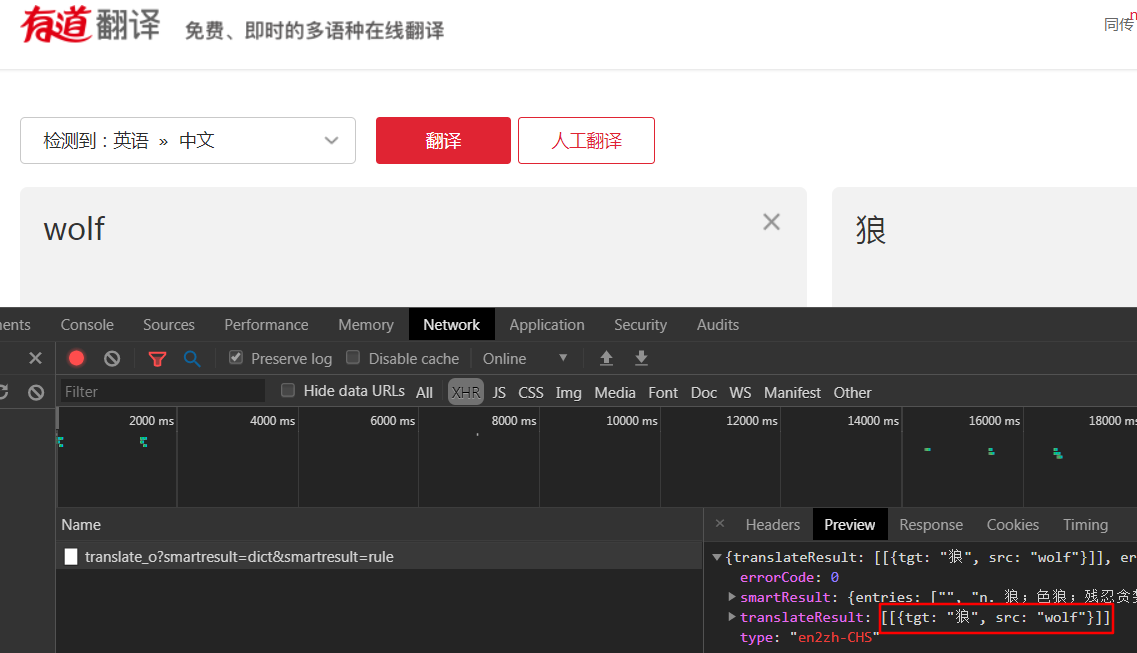
- 打开网站输入要翻译的内容,一一查找network发现数据返回json格式,红框就是我们的翻译结果
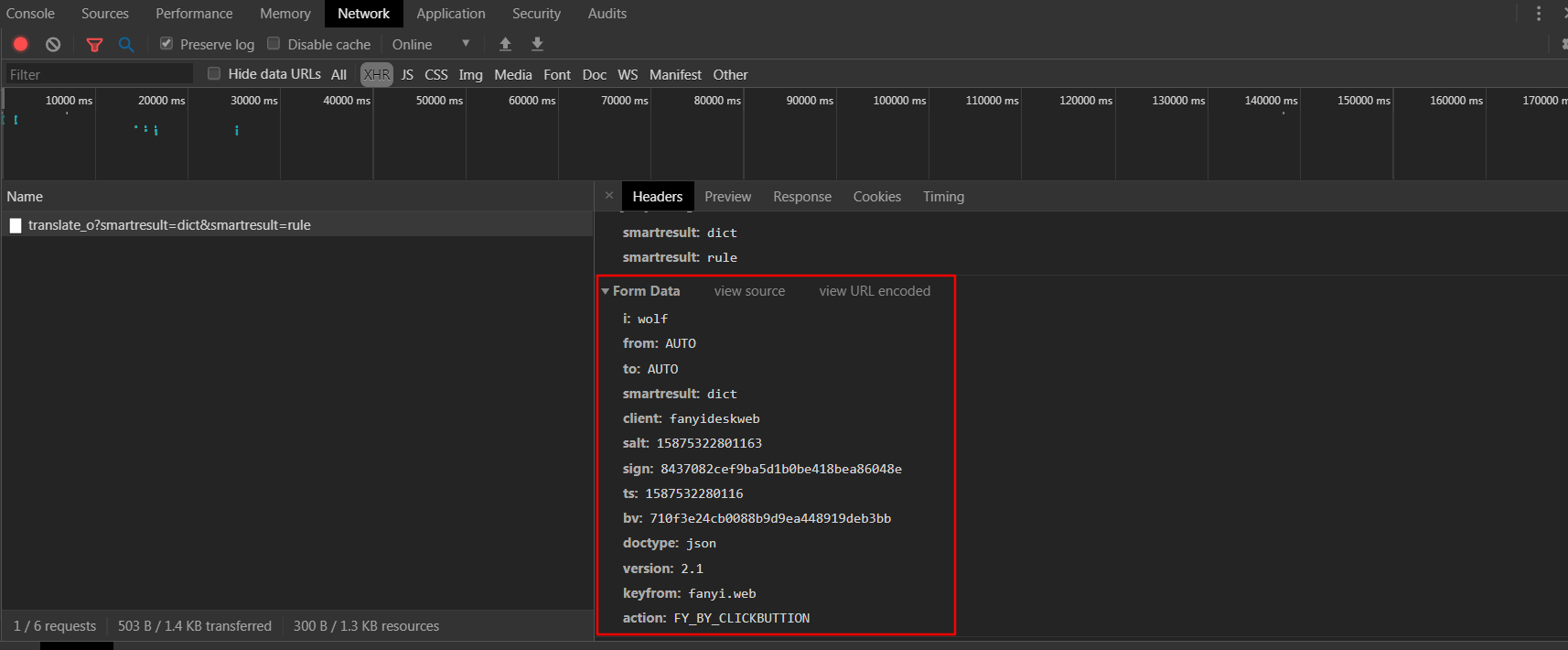
- 查看headers,发现返回结果的请求是post请求,且携带一大堆form_data,一一理下一表单数据
- i:要翻译的数据
- from、to:from to 表示从哪国语言翻译到哪国语言
- smartresult、doctype:返回结果的形式以字典形式
- client、keyfrom、action:区分客户端类型
- salt、sign、ts、bv:看起来不太友善,好像是反爬虫参数
- 观察ts参数为13整数字符串,大概率是当前时间戳取整
- salt比ts多出一位
- sign和bv都为32位字符串,可以推断为经过MD5加密的字符串

- 使用浏览器的search功能,发现sign藏在一个js文件中,搜索找到并点击
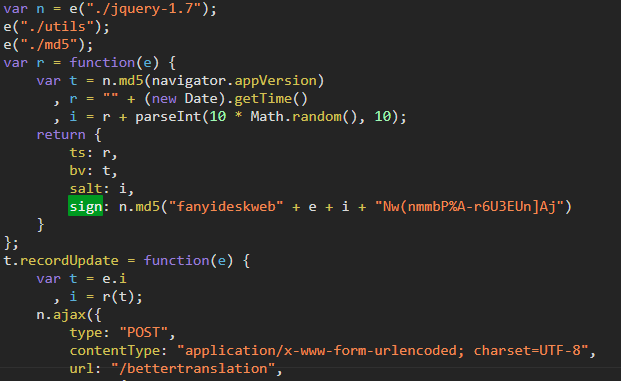
- 经过一番查找,发现这四位老铁是不是挺眼熟,没错,这个函数就是这四个参数的生成算法(js加密参数一般都是用客户端比如.py的参数参数生成算法和服务器端的参数生成算法比较,不是用参数直接比较,这点要注意)
既然已经找到,那我们就用python改写一个这段生成加密参数的js代码,我们把js代码复制到本地以方便改写Python代码
define("newweb/common/service", ["./utils", "./md5", "./jquery-1.7"], function(e, t) {
var n = e("./jquery-1.7");
e("./utils");
e("./md5");
var r = function(e) {
var t = n.md5(navigator.appVersion) # navigator.appVersion就是浏览器版本信息,User-Agent
, r = "" + (new Date).getTime() # 获取当前日期的整数字符串
, i = r + parseInt(10 * Math.random(), 10);
return {
ts: r,
bv: t,
salt: i,
sign: n.md5("fanyideskweb" + e + i + "Nw(nmmbP%A-r6U3EUn]Aj") # 这边的最后一个子串看起来像随机生成的(容易误导),可以在js代码里面打断点多试几遍发现是常量
}
};
def get_sign(self, key_word):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
# ts 为当前时间戳
ts = str(round(time()))
# salt 为ts拼接1-9之间的一个随机整数
salt = ts + str(randint(1 ,9))
# bv browser version 就是User-Agent进过md5加密的数据
bv = hashlib.md5(bytes(user_agent, encoding='utf-8')).hexdigest()
# sign 由四部分组成,起始和结尾的数据都是固定的,中间两个参数分别对应要翻译的对象和 salt
sign = hashlib.md5(bytes('fanyideskweb' + key_word + salt + 'Nw(nmmbP%A-r6U3EUn]Aj', encoding='utf-8')).hexdigest()
self.post_data['salt'] = salt
self.post_data['sign'] = sign
self.post_data['ts'] = ts
self.post_data['bv'] = bv
return self.post_data
- 接下来完事具备,我们就把我们的蜘蛛完善一下
#!/usr/bin/env python
# !@software: PyCharm
# !@coding:
# !@time: 2020/4/22 11:52
# !@author: xiaoma
import requests
from random import randint,sample
from time import time
import hashlib
class FanyiSpider(object):
def __init__(self, key_word):
self.key_word = key_word
self.base_url = 'http://fanyi.youdao.com/'
self.post_data = {
'i': self.key_word,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '',
'sign': '',
'ts': '',
'bv': '',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_CLICKBUTTION'
}
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Referer': 'http://fanyi.youdao.com/'
}
self.session = requests.session()
def get_sign(self, key_word):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
# ts 为当前时间戳
ts = str(round(time()))
# salt 为ts拼接1-9之间的一个随机整数
salt = ts + str(randint(1 ,9))
# bv browser version 就是User-Agent进过md5加密的数据
bv = hashlib.md5(bytes(user_agent, encoding='utf-8')).hexdigest()
# sign 由四部分组成,起始和结尾的数据都是固定的,中间两个参数分别对应要翻译的对象和 salt
sign = hashlib.md5(bytes('fanyideskweb' + key_word + salt + 'Nw(nmmbP%A-r6U3EUn]Aj', encoding='utf-8')).hexdigest()
self.post_data['salt'] = salt
self.post_data['sign'] = sign
self.post_data['ts'] = ts
self.post_data['bv'] = bv
return self.post_data
def run(self): # 主要实现逻辑
# 1. 发送get请求
get_res = self.session.get(self.base_url, headers=self.headers)
# 2. 获取加密参数
post_data = self.get_sign(self.key_word)
# print(post_data)
# 3. 发送post,获取响应
post_res = self.session.post(self.base_url+'translate_o', headers=self.headers, data=post_data) # 注意:翻译的base_url和get请求的base_url有不一样的地方,记得拼接
# 4. 解析数据
print(post_res.json().get('translateResult')[0][0]['tgt'])
if __name__ == '__main__':
key_word = input("请输入想要翻译的内容>>>").strip()
youdao = FanyiSpider(key_word)
youdao.run()