一 、join应如何优化
先列出答案:
1、为join的连接条件增加索引(减少内层表的循环次数)
2、尽量用小表join大表(其本质就是减少外层循环的数据次数)
3、增大join buffer size的大小(一次缓存的数据越多,那么外层表循环的次数就越少)
4、减少不必要的字段查询(字段越少,join buffer 所缓存的数据就越多,外层表的循环次数就越少)
5、如果是大表join大表,这种情况对大表建立分区表再进行join,效果会比较明显。
注意:
1.join优化的最重要的步骤是给join连接字段建立索引,这样才能大幅度降低查询速度;
2.小表join大表能提高查询速度有2个前提:1.当连接字段为索引字段时才可提高查询速度,如果连接字段为非索引字段则没有什么效果;2.join连接需是left join或right join才可以,因为inner join的join顺序是mysql会根据优化器自行决定查询顺序,比如a表join b表,mysql在执行查询的时候可能先查b表再查a表(即把b表作为驱动表)。
3.网上有很一些文章说”小表join大表能提高查询速度是错误的,理由是mysql执行器不会根据我们join的顺序去查询,比如a表join b表,mysql在执行查询的时候可能先查b表再查a表(把b表作为驱动表)”,这个说法其实在inner join的前提下才是有效的。
二、实验验证
创建表,并插入数据
说明:user表为大表(100万条数据),user2为小表(1000条数据),两个表结构一致,都只含有一个索引,即主键(id)索引
-- 创建表user+插入数据(100万条) create table user(id bigint not null primary key auto_increment, name varchar(20) not null default '' comment '姓名', age tinyint not null default 0 comment 'age', gender char(1) not null default 'M' comment '性别', phone varchar(16) not null default '' comment '手机号', create_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', update_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间' ) engine = InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '用户信息表'; CREATE PROCEDURE insert_user_data(num INTEGER) BEGIN DECLARE v_i int unsigned DEFAULT 0; set autocommit= 0; WHILE v_i < num DO insert into user(`name`, age, gender, phone) values (CONCAT('lyn',v_i), mod(v_i,120), 'M', CONCAT('152',ROUND(RAND(1)*100000000))); SET v_i = v_i+1; END WHILE; commit; END call insert_user_data(1000000); -- 创建表user2+插入数据(1000条) create table user2 select * from user where 1=2;-- 复制表,仅复制表结构(不会创建自增主键,索引,需手工创建) ALTER TABLE `user2` ADD PRIMARY KEY ( `id` ) ;-- 创建主键索引 CREATE PROCEDURE insert_user2_data(num INTEGER) BEGIN DECLARE v_i int unsigned DEFAULT 0; set autocommit= 0; WHILE v_i < num DO insert into user2(`name`, age, gender, phone) values (CONCAT('lyn',v_i), mod(v_i,120), 'M', CONCAT('152',ROUND(RAND(1)*100000000))); SET v_i = v_i+1; END WHILE; commit; END call insert_user2_data(1000);
测试
说明:下面测试按join的连接字段是否为索引列分2种情况测试,先测试大表join小表,再测试小表join大表,分别执行3次,注释中记录了3次的查询时间
-- join的连接字段为索引列 SELECT * from user u LEFT JOIN user2 u2 on u.id = u2.id;-- 3.681s 3.770s 3.650s SELECT * from user2 u2 LEFT JOIN user u on u.id = u2.id;-- 0.002s 0.002s 0.003s -- join的连接字段为非索引列 SELECT * from user u LEFT JOIN user2 u2 on u.name = u2.name;-- 124.450s 139.875s 142.904s SELECT * from user2 u2 LEFT JOIN user u on u.name = u2.name;-- 140.093s 142.917s 139.737s
通过上述测试结果发现:1.join的连接字段为索引列比非索引列快了十条街;2.在join的连接字段为索引列时,小表join大表比大表join小表快了十条街,在join的连接字段为非索引列时,小表join大表与大表join小表的查询速度似乎差不多。这足以验证第一节的join优化结论。
分析
下面看下执行计划
-- 连接字段为索引列 EXPLAIN SELECT * from user u LEFT JOIN user2 u2 on u.id = u2.id;-- 3.681s 3.770s 3.650s EXPLAIN SELECT * from user2 u2 LEFT JOIN user u on u.id = u2.id;-- 0.002s 0.002s 0.003s -- 连接字段为非索引列 EXPLAIN SELECT * from user u LEFT JOIN user2 u2 on u.name = u2.name;-- 124.450s 139.875s 142.904s EXPLAIN SELECT * from user2 u2 LEFT JOIN user u on u.name = u2.name;-- 140.093s 142.917s 139.737s
执行计划结果(按上面的sql依次执行)

从执行结果中红框标注看,可以得知为什么小表join大表比较快,这是因为小表u2作为驱动表只大概扫描了1000行,而大表u作为驱动表大概扫描了995757行。从红框标注与蓝框标注对比可以得知为什么join中的连接条件使用索引字段比非索引字段要快,首先前者比后者扫描的行数要少,其次我们注意到后者在Extra中明确表示用到了join的BNL算法(Block Nested Loop)°?从第3节的Block Nested-Loop算法介绍上看,这种算法是把外层驱动表的一部分数据放到了join buffer中以减少驱动表的循环次数,但是从上图中的第4个结果看,内层表也用到了这种算法——这是否为mysql在新版本做出的优化不得而知。到了这里,我们只能从实验证实我们的优化结论是正确的,但是为什么小表join大表比大表join小表快,为什么join的连接字段使用索引字段比使用非索引字段快,为什么当join的连接字段为非索引字段时,大表Join小表与小表join大表的速度差不多?还需要我们学习第3节才能找到答案。
三、三种join算法
本文第1节说明了join优化结论,并在第2节进行验证,如果要想搞懂优化结论的原理,则需搞明白mysql在join时的相关算法:
NLJ算法 Nested Loop Join(或Simple Nested-Loop Join):这种算法是最low的,你可以简单理解为这种算法就是一个双层for循环算法,在join匹配时循环次数是最多的,在5.6之前如果join字段为非索引字段,会采用这种join算法。
BNLJ算法 Block Nested-Loop Join:这是5.6之后,mysql替换NLJ的升级算法,所以升级之处就在于它把join的驱动表放到了内存buffer中,拿内存buffer中的数据批量与内层表数据匹配,从而减少了驱动表的循环(匹配)次数。
INLJ算法 index Nested Loop Join:这是当join字段为索引字段时,mysql采用的算法,这种算法让驱动表不直接与内层表进行逐行匹配,而是与内层表的连接索引字段进行匹配,这样就减少了内层表的循环(匹配)次数。
不论是Index Nested-Loop Join 还是 Block Nested-Loop Join 都是在Simple Nested-Loop Join的算法的基础上 减少嵌套的循环次数, 不同的是 Index Nested-Loop Join 是通过索引的机制减少内层表的循环次数,Block Nested-Loop Join 是通过一次缓存多条数据批量匹配的方式来减少外层表的循环次数。
下面是这3种算法的详细介绍:
Simple Nested-Loop Join(简单的嵌套循环连接)
简单来说嵌套循环连接算法就是一个双层for 循环 ,通过循环外层表的行数据,逐个与内层表的所有行数据进行比较来获取结果,当执行select * from user tb1 left join level tb2 on tb1.id=tb2.user_id
时,我们会按类似下面代码的思路进行数据匹配:

整个匹配过程会如下图:
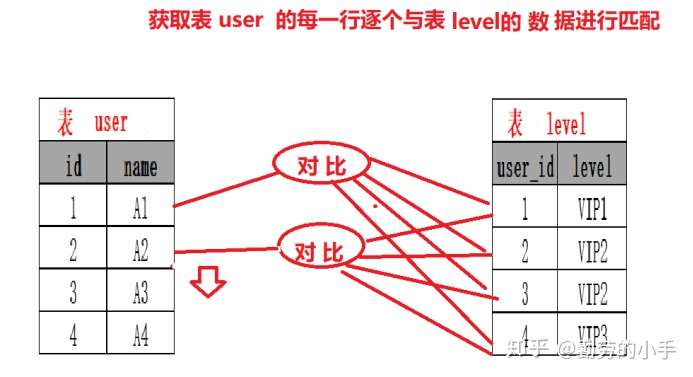
特点:
Nested-Loop Join 简单粗暴容易理解,就是通过双层循环比较数据来获得结果,但是这种算法显然太过于粗鲁,如果每个表有1万条数据,那么对数据比较的次数=1万 * 1万 =1亿次,很显然这种查询效率会非常慢。
当然mysql 肯定不会这么粗暴的去进行表的连接,所以就出现了后面的两种对Nested-Loop Join 优化算法,在执行join 查询时mysql 会根据情况选择 后面的两种优join优化算法的一种进行join查询。
Index Nested-Loop Join(索引嵌套循环连接)
Index Nested-Loop Join其优化的思路 主要是为了减少内层表数据的匹配次数, 简单来说Index Nested-Loop Join 就是通过外层表匹配条件 直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较, 这样极大的减少了对内层表的匹配次数,从原来的匹配次数=外层表行数 * 内层表行数,变成了 外层表的行数 * 内层表索引的高度,极大的提升了 join的性能。
案例:
如SQL:select * from user tb1 left join level tb2 on tb1.id=tb2.user_id
当level 表的 user_id 为索引的时候执行过程会如下图:
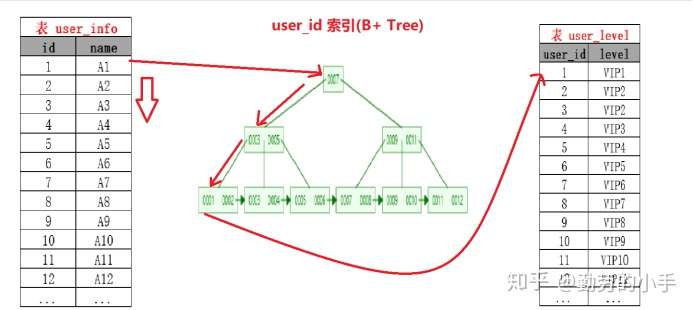
注意:使用Index Nested-Loop Join 算法的前提是匹配的字段必须建立了索引。
Block Nested-Loop Join(缓存块嵌套循环连接)
Block Nested-Loop Join 其优化思路是减少外层表的循环次数,Block Nested-Loop Join 通过一次性缓存多条数据,把参与查询的列缓存到join buffer 里,然后拿join buffer里的数据批量°?这里我不太理解为什么把驱动表的数据拿到缓存buffer中就能批量与内层表进行匹配,比如说join buffer一次性缓存了3条数据,则这3条数据只需与内层表匹配一次即可?与内层表的数据进行匹配,从而减少了外层循环的次数,当我们不使用Index Nested-Loop Join的时候,默认使用的是Block Nested-Loop Join。
案例:
如SQL:select * from user tb1 left join level tb2 on tb1.id=tb2.user_id
当level 表的 user_id 不为索引的时候执行过程会如下图:

小结
好了,根据对mysql的join算法的理解,我们可以回答第2节最后提出的问题了:
1、为什么join的连接字段使用索引字段比使用非索引字段快?
因为采用了Index Nested-Loop Join算法,极大的减少了内层表的匹配次数。
2、为什么小表join大表比大表join小表快?
这里先讨论Join字段为索引字段的情况,因为小表join大表更能显著地减少外层驱动表的循环次数,比如在第2节的举例,外层驱动表为100万条数据,内层表为1000条数据。如果外层驱动表为大表,即使采用Block Nested-Loop Join算法,因为join buffer的大小总是有限的,最终外层驱动表还是需要接近10万次循环;而用小表join大表的话,外层驱动表仅用了1000次左右的循环,再加上join字段为索引字段,用到了Index Nested-Loop Join算法,又极大的减少了内层大表的循环次数,所以join字段为索引字段+小表join大表结合起来的查询速度非常快。
3、为什么当join的连接字段为非索引字段时,大表Join小表与小表join大表的速度差不多?
因为虽然说把小表作为驱动表能极大减少外层循环的次数,但是内层表为大表,由于连接字段为非索引字段,不能用Index Nested-Loop Join算法减少内层循环的次数,所以当join的连接字段为非索引字段时,两种形式的区别不大。
注意:
1、使用Block Nested-Loop Join 算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on 默认为开启,如果关闭则使用Simple Nested-Loop Join 算法;
通过指令:Show variables like 'optimizer_switc%'; 查看配置

2、设置join buffer 的大小
通过join_buffer_size参数可设置join buffer的大小
指令:Show variables like 'join_buffer_size%';
