一、基础数据结构
1、string
字符串string是Redis最简单的数据结构,内部是一个字符数组。常用于缓存用户信息(JSON序列化),但
①Redis的string是一个动态字符串,内部结构实现类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,
内部为当前字符串分配的实际空间capacity,一般是大于实际长度length的,当字符串长度小于1MB时,扩容就是加倍现有空间;当字符串长度超过1MB,扩容时一次只会多扩容1MB
②注意字符串最大长度为512MB
指令:
//redis-cli //help @string APPEND key value BITCOUNT key [start end] BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset inc rement] [OVERFLOW WRAP|SAT|FAIL] BITOP operation destkey key [key ...] BITPOS key bit [start] [end] DECR key DECRBY key decrement GET key GETBIT key offset GETRANGE key start end GETSET key value INCR key INCRBY key increment INCRBYFLOAT key increment MGET key [key ...] MSET key value [key value ...] MSETNX key value [key value ...] PSETEX key milliseconds value SET key value [expiration EX seconds|PX milliseconds] [NX|XX] SETBIT key offset value SETEX key seconds value SETNX key value SETRANGE key offset value STRLEN key
2、list
Redis的列表采用双向链表实现,所以
①插入删除操作非常快O(1),查询速度很慢O(n),
②底层存储的不是一个简单的LinkedList而是一个quicklist,当list中元素较少时,ziplist存储,元素存储与数组一样是彼此相邻的;当元素比较多时,改为quicklist实现,Redis将链表和ziplist
组合起来组成quicklist
③Redis的列表常用做队列使用
指令:由于Redis是单线程、应该注意三个查询(O(n))相关的指令的使用:lindex、lrange、ltrim
//redis-cli //help @list BLPOP key [key ...] timeout BRPOP key [key ...] timeout BRPOPLPUSH source destination timeout LINDEX key index //查询相关指令慎用,O(n) LINSERT key BEFORE|AFTER pivot value LLEN key LPOP key LPUSH key value [value ...] LPUSHX key value LRANGE key start stop //查询相关指令慎用,O(n) LREM key count value LSET key index value LTRIM key start stop //查询相关指令慎用,O(n) RPOP key RPOPLPUSH source destination RPUSH key value [value ...] RPUSHX key value
3、hash
Redis的hash存储实现,类似于jdk1.7的HashMap存储实现:“数组+链表”。但
①Redis的hash存储的值只能是字符串类型
②Redis的hash的扩容过程与HashMap不同,HashMap采用一次性全部rehash,然后丢弃原数组;Redis的hash采用渐进式rehash,会同时使用原数组和新数组,知道全部rehash完成,才丢弃原数组。
③bdsave会阻塞hash的rehash,但当hash数据超过数组5倍,已经过于拥塞,会强制rehash。
指令:
//redis-cli //help @hash HDEL key field [field ...] HEXISTS key field HGET key field HGETALL key HINCRBY key field increment HINCRBYFLOAT key field increment HKEYS key HLEN key HMGET key field [field ...] HMSET key field value [field value ...] HSCAN key cursor [MATCH pattern] [COUNT count] HSET key field value HSETNX key field value HSTRLEN key field HVALS key
4、set
Redis的无序集合相当于Java中HashSet,底层是一个HashMap,Entry的值为NULL;
①set有去重功能,可以保证一些去重业务。
指令:
//redis-cl //help @set SADD key member [member ...] SCARD key SDIFF key [key ...] SDIFFSTORE destination key [key ...] SINTER key [key ...] SINTERSTORE destination key [key ...] SISMEMBER key member SMEMBERS key SMOVE source destination member SPOP key [count] SRANDMEMBER key [count] SREM key member [member ...] SSCAN key cursor [MATCH pattern] [COUNT count] SUNION key [key ...] SUNIONSTORE destination key [key ...]
5、sorted_set
sorted_set有序集合是Redis最有特色的数据结构,也称zset。存储结构跟Set一致,但多了一个排序逻辑,给每个Entry赋予一个score属性,用于排序。
①排序需要随机的插入和删除,所以不宜用数组实现,数组插入元素时,需要调整其他元素的位置,zset是链表实现的
②zset内部的排序功能时通过“跳跃链表SkipList”(后面简单介绍)数据结构来实现的。
③zset可实现延时队列
指令:
//redis-cli //help sorted_set BZPOPMAX key [key ...] timeout BZPOPMIN key [key ...] timeout ZADD key [NX|XX] [CH] [INCR] score member [score member ...] ZCARD key ZCOUNT key min max ZINCRBY key increment member ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] ZLEXCOUNT key min max ZPOPMAX key [count] ZPOPMIN key [count] ZRANGE key start stop [WITHSCORES] ZRANGEBYLEX key min max [LIMIT offset count] ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] ZRANK key member ZREM key member [member ...] ZREMRANGEBYLEX key min max ZREMRANGEBYRANK key start stop ZREMRANGEBYSCORE key min max ZREVRANGE key start stop [WITHSCORES] ZREVRANGEBYLEX key max min [LIMIT offset count] ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] ZREVRANK key member ZSCAN key cursor [MATCH pattern] [COUNT count] ZSCORE key member ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
6、容器型数据结构通用规则
list、hash、set、zset这四种数据结构是容器型数据结构
①、create if not exists:如果容器不存在,创建一个,再进行操作。
②、drop if no elements:如果容器里的元素没有了,那么立即删除容器,释放内存。
补充:7、常用指令集(包括后面添加的bloom,redis-cell)
//redis-cli //help @generic DEL key [key ...] DUMP key EXISTS key [key ...] EXPIRE key seconds EXPIREAT key timestamp KEYS pattern MIGRATE host port key| destination-db timeout [COPY] [REPLACE] [KEYS key] MOVE key db OBJECT subcommand [arguments [arguments ...]] PERSIST key PEXPIRE key milliseconds PEXPIREAT key milliseconds-timestamp PTTL key RANDOMKEY - RENAME key newkey RENAMENX key newkey RESTORE key ttl serialized-value [REPLACE] SCAN cursor [MATCH pattern] [COUNT count] SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC|DESC] [ALPHA] [STORE destination] TOUCH key [key ...] TTL key TYPE key UNLINK key [key ...] WAIT numreplicas timeout ASKING BF.MADD key ...options... CF.ADD key ...options... LATENCY arg ...options... GEORADIUSBYMEMBER_RO key arg arg arg ...options... PFSELFTEST CF.RESERVE key ...options... BF.LOADCHUNK key ...options... BF.ADD key ...options... BF.EXISTS key ...options... BF.RESERVE key ...options... CF.INSERT key ...options... BF.SCANDUMP key ...options... REPLCONF ...options... CF.COUNT key ...options... LOLWUT ...options... MODULE arg ...options... GEORADIUS_RO key arg arg arg arg ...options... CF.INSERTNX key ...options... BF.INSERT key ...options... XSETID key arg PFDEBUG arg arg ...options... CF.EXISTS key ...options... CL.THROTTLE key ...options... CF.ADDNX key ...options... BF.DEBUG key ...options... BF.MEXISTS key ...options... HOST: ...options... CF.MEXISTS key ...options... SUBSTR key arg arg CF.DEBUG key ...options... CF.DEL key ...options... CF.SCANDUMP key ...options... PSYNC arg arg RESTORE-ASKING key arg arg ...options... CF.LOADCHUNK key ...options... POST ...options...
二、跳跃链表SkipLIst
链表:时间复杂度O(n),下图查找成功平均比较次数:(1+2+3+...+7)/7=4;

跳跃表SkipList:时间复杂度O(logn),采用的空间换时间的策略,从顶层往下查找,下图查询过程:
查找2,L2层:与2比较。
查找3,L2层:与2比较,与8比较,进入L1层:与4比较,进入L0层,与3比较
查找4,L2层:与2比较,与8比较,进入L1层:与4比较
查找5,L2层:与2比较,与8比较,进入L1层:与4比较,与6比较,进入L0层,与5比较
查找6,L2层:与2比较,与8比较,进入L1层:与4比较,与6比较
查找7,L2层:与2比较,与8比较,进入L1层:与4比较,与6比较,与8比较,进入L0层,与7比较
查找8,L2层:与2比较,与8比较
查找成功平均比较次数:(1+4+3+5+4+6+2)/7=25/7≈3.6,
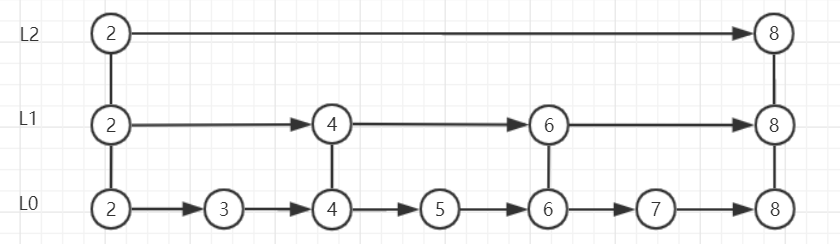
Redis的zset中跳跃链表采用跳跃链表实现,共有32层,采取随机策略决定新元素位于哪几层:位于L0层:100%;L1层:50%;L2层:25%;L3层:12.5% .....;L31层:2^-31
补充:
跳跃表相比于红黑树,在更新时变更的节点较少,更易于实现并发操作。
三、过期策略
Redis中有很多数据设置了过期时间,时间一到会删除数据。
Redis删除过期数据的两种策略。
定时扫描策略:会将每个设置了过期时间的key放入一个独立字典中,然后定期扫描删除。默认每秒进行10次过期扫描,每次扫描并不是全量扫描,而是采用一种简单的贪心策略:
①从过期字典中随机选出20个key
②删除20个key中已过期的key
③如果过期的key的比例超过1/4.重复①。为保证不会出现循环过渡,设置了扫描时间的上限,默认25ms
另外:缓存雪崩的一个场景,同一时间大量的key过期,会导致多次的25ms,25ms内删除属于写操作,redis是单线程的,会阻塞客户端请求造成客户端卡顿。过期时间随机化很好的解决这个问题。
惰性策略:客户端访问key时候,对key的过期时间进行检测,如果过期了就立即删除。
从节点过期策略是被动的,等待主节点的del指令。
四、近似LRU
操作系统中分配给进程内存超出时,就会置换内存中的页,方法有OPT、FIFO、LRU、CLOCK、改进CLOCK算法。
当Redis内存超出物理内存限制时,采用一种近似LRU算法。
LRU算法:替换出最近最久未使用的页
Redis近似LRU算法:惰性处理,随机采样n(maxmemory_samples默认为5)个key,然后淘汰掉最旧的key,如果淘汰后内存还是超出最大内存,继续循环采样淘汰,直到内存低于最大内存为止。
配置maxmemory-policy=all:在所有key中随机采样n个key
配置maxmenory-policy=volatile,从带过期时间的key字典中随机采样n个key
五、懒惰删除
Redis是单线程的,虽然带来了代码的简洁性和丰富多样的数据结构,但同时在删除大量对象时,会导致服务卡顿,所以redis很多地方都采用惰性删除策略,如上面的过期key删除,和一些大对象的删除
4.0版本引入unlink指令,对key懒处理,unlink的key会被后台程序异步删除,同时主线程看不见这个key。unlink会将key的value设置null,原value对象异步删除,不影响主线程
六、代替keys的scan指令
keys的缺点:时间复杂度为O(n),会返回匹配的key,当匹配key过多时,造成redis服务卡顿。
scan相比于keys:
① 时间复杂度为O(n),但它是通过槽位(如cluster的16384槽位)分步进行的,不会阻塞线程。
② 提供limit参数,可以控制每次返回的结果的最大条数
③ 同keys一样,具有模糊匹配功能
④ 服务器不需要保存游标状态,游标会返回个客户端
⑤ 返回的结果可能会有重复,需要客户端去重,rehash导致数据槽位变动
⑥由于是分步进行的,遍历过程中数据改变不能确定,不是快照
⑦单词返回结果为空,并不意味这遍历结束,需要看返回的槽位值是否为零
代码测试:
1 public class ClusterTest { 2 3 /** 4 * 创建单例 5 */ 6 7 private ClusterTest() throws IllegalAccessException { 8 throw new IllegalAccessException(); 9 } 10 11 private static JedisCluster jedisCluster = null; 12 private static final String HOST = "192.168.0.114"; 13 static{ 14 JedisPoolConfig config = new JedisPoolConfig(); 15 config.setMaxTotal(100); 16 config.setMaxIdle(100); 17 config.setMaxWaitMillis(10000); 18 config.setTestOnBorrow(true); 19 Set<HostAndPort> nodes = new HashSet<>(); 20 nodes.add(new HostAndPort(HOST,6379)); 21 nodes.add(new HostAndPort(HOST,6389)); 22 nodes.add(new HostAndPort(HOST,6399)); 23 nodes.add(new HostAndPort(HOST,6279)); 24 nodes.add(new HostAndPort(HOST,6289)); 25 nodes.add(new HostAndPort(HOST,6179)); 26 nodes.add(new HostAndPort(HOST,6189)); 27 jedisCluster = new JedisCluster(nodes,config); 28 29 } 30 31 /** 32 * 测试连接 33 */ 34 public static void main(String[] args){ 35 try { 36 jedisCluster.set("linkTest","hello World"); 37 jedisCluster.set("scanTest","hello World"); 38 jedisCluster.set("test","hello World"); 39 jedisCluster.set("test2","hello World"); 40 jedisCluster.set("test3","hello World"); 41 System.out.println(jedisCluster.get("linkTest")); 42 Set<String> keys = new HashSet<>(); 43 Map<String,JedisPool> jedisPoolMap = jedisCluster.getClusterNodes(); 44 for (JedisPool jedisPool : jedisPoolMap.values()) { 45 try (Jedis jedis = jedisPool.getResource()){ 46 Set<String> nodeKeys = jedis.keys("*");//返回节点所有 47 keys.addAll(nodeKeys); 48 } 49 } 50 System.out.println(keys); 51 keys.clear(); 52 for (JedisPool jedisPool : jedisPoolMap.values()){ 53 try (Jedis jedis = jedisPool.getResource()){ 54 String cursor = "0";//以0开始 55 for (;;){//以槽位为单位分步查询,所以需要循环查 56 ScanResult<String> result = jedis.scan(cursor,new ScanParams().match("*").count(1)); 57 cursor = result.getCursor(); 58 keys.addAll(result.getResult()); 59 if ("0".equals(cursor)){//以0结束 60 break; 61 } 62 } 63 } 64 } 65 System.out.println(keys); 66 }finally { 67 close(); 68 } 69 } 70 71 public static void close(){ 72 if(jedisCluster != null){ 73 jedisCluster.close(); 74 } 75 } 76 }
七、位图
字符串是一个字符数组(char[]),存储内容其实是一个字节数组(byte[]),一个字节有8bit位。
位图不是特殊的数据结构,只是操作字符串中bit位(0或1),操作指令也在string组中。
//redis-cli //help @string BITCOUNT key [start end] //统计key的value中bit==1的总数 BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset inc rement] [OVERFLOW WRAP|SAT|FAIL] BITOP operation destkey key [key ...] BITPOS key bit [start] [end] //获取key的value的start--end位的第一个0或者1(bit)的位置 GETBIT key offset //获取key的value的第offset位 SETBIT key offset value //设置key的value的第offset位为value(只能是0或1)
特别说明一下bitfield魔数指令:可以操作多个位,
//set w hello bitfield w get u3 2 //从2位开始获取3个bit,返回无符号数101=5 bitfield w get i3 2 //从2位开始获取3个bit,返回有符号数101=-3,注意负数补码表示
位图常用于一些boolean类型的数据的存取,如签到1、未签到0,一年365天仅需365bit的存储空间就可以表示,若使用string存储则需要365byte。
代码测试:
1 public class BitTest { 2 3 public static void main(String[] args){ 4 Random random = new Random(); 5 int rm; 6 int count = 0; 7 try (Jedis jedis = RedisUtils.getJedis();){ 8 for (int i = 0; i < 365; i++) { 9 rm = random.nextInt(500); 10 if (rm%2 == 0){ 11 jedis.setbit("bitTest",i,true);//redis打标 12 count++;//计数器 13 } 14 } 15 System.out.println("count : " + count);//计数器统计 16 System.out.println("bitCount : " + jedis.bitcount("bitTest"));//redis统计 17 }
18 RedisUtils.close(); 19 } 20 }
八、HyperLogLog
原理有点复杂,使用场景:提供不精确的去重统计方案,虽然不精确,但是标准误差是0.81%.
用set也可以实现精确去重统计,但是当数据量非常大时会占用大量内存。
HyperLogLog的使用需要占用12KB的内存空间,不适合统计单个用户相关的数据
测试代码:
1 public class HyperLogLogTest { 2 3 public static void main(String[] args){ 4 try (Jedis jedis = RedisUtils.getJedis();){ 5 jedis.del("codehole"); 6 jedis.del("codeholee1"); 7 jedis.del("codeholee2"); 8 jedis.del("codeholeee1"); 9 jedis.del("codeholeee2"); 10 for (int i = 0; i < 10000; i++) { 11 jedis.pfadd("codehole","user" + i); 12 jedis.pfadd("codeholee1","user" + i);//与codehole中value相同,merge时去重 13 jedis.pfadd("codeholee2","userr" + i); 14 } 15 System.out.println("10000 : " + jedis.pfcount("codehole")); 16 System.out.println("10000 : " + jedis.pfcount("codeholee1")); 17 System.out.println("10000 : " + jedis.pfcount("codeholee2")); 18 jedis.pfmerge("codeholeee1","codeholee1","codehole"); 19 jedis.pfmerge("codeholeee2","codeholee2","codehole"); 20 System.out.println("20000 : " + jedis.pfcount("codeholeee1")); 21 System.out.println("20000 : " + jedis.pfcount("codeholeee2")); 22 23 }
24 RedisUtils.close(); 25 } 26 }
九、布隆过滤器
1、原理
当向布隆过滤器中添加key时,先用不同的无偏hash算法生成多个hash值,然后用除余法定位到一个位数组(位图)上(逻辑与HashMap中key的hash定位数组中的位置一样),
然后把位数组中对应的位置都置位1.
判断key是否存在时,用不同的无偏hash算法生成多个hash值,找到位数组对应的位置,若都为1,则存在,否则不存在。
由于哈希表实现的弊病,hash冲突可能会导致不同的key定位到相同的位置,所以布隆过滤器判断存在的数据可能不存在,但判断不存在的数据是一定不存在。
由于判断不存在的数据一定不存在,布隆过滤器可以解决redis缓存穿透的问题。
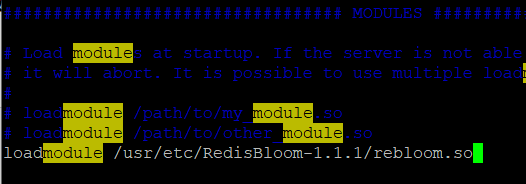
Redis4.0后提供布隆过滤器的插件,需要去github下载插件加载,
wget https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz tar -zxvf v1.1.1.tar.gz cd RedisBloom-1.1.1 make //redis.conf中指定redisbloom模块路径后,重启redis服务,测试bf.add bf.exists loadmodule /usr/etc/RedisBloom-1.1.1/rebloom.so

jedis暂不支持redisbloom,需要依赖jar包JReBloom。
<dependency> <groupId>com.redislabs</groupId> <artifactId>jrebloom</artifactId> <version>2.0.0-m2</version> </dependency>
测试代码:
1 RedisUtils.java 2 private static Client client = null; 3 static{ 4 // JEDIS = new Jedis(HOST,6379,1000); 5 JedisPoolConfig config = new JedisPoolConfig(); 6 config.setMaxTotal(100); 7 config.setMaxIdle(100); 8 config.setMaxWaitMillis(10000); 9 config.setTestOnBorrow(true); 10 jedisPool = new JedisPool(config,HOST,6379); 11 client = new Client(jedisPool); 12 13 } 14 15 public static Client getJReBloomClient(){ 16 return client; 17 } 18 19 public class RedisBloomTest { 20 21 public static void main(String[] args){ 22 try (Client client = RedisUtils.getJReBloomClient()){ 23 client.delete("codehole"); 24 for (int i = 0; i < 10000; i++) { 25 client.add("codehole","user" + i); 26 } 27 for (int i = 0; i < 10000; i++) { 28 boolean ret = client.exists("codehole","user" + i); 29 if (!ret){//判断为不存在的,实际存在的数据 30 System.out.println("user" + i);//为空 31 } 32 } 33 System.out.println("-----------------------------"); 34 for (int i = 5000;i < 15000;i++){ 35 boolean ret = client.exists("codehole","user" + i); 36 if (ret && i > 10000){//判断为存在,实际不存在的 37 System.out.println("user" + i);//很多 38 } 39 } 40 }
41 RedisUtils.close(); 42 } 43 }
十、简单限流
简单限流采用滑动窗口算法实现限流。
滑动窗口算法,固定滑动窗口的大小,限制流量。
采用zset代码实现:
1 public class SimpleRateLimiter { 2 3 public boolean isActionAllowed(String userId, String actionKey, int period, int maxCount){ 4 Response<Long> count = null; 5 try (Jedis jedis = RedisUtils.getJedis();){ 6 String key = String.format("hist:%s:%s", userId, actionKey); 7 long nowTs = System.currentTimeMillis(); 8 Pipeline pipeline = jedis.pipelined(); 9 pipeline.multi(); 10 pipeline.zadd(key, nowTs, "" + nowTs); 11 pipeline.zremrangeByScore(key, 0, nowTs - period * 1000); 12 count = pipeline.zcard(key); 13 pipeline.expire(key,period + 1); 14 pipeline.exec(); 15 pipeline.close(); 16 if (count.get() <= maxCount){ 17 //元素加入滑动窗口,元素总数<=滑动窗口大小 18 return true; 19 }else{ 20 //元素加入滑动窗口,元素总数>滑动窗口大小,拒绝加入 21 jedis.zrem(key,nowTs +""); 22 return false; 23 } 24 } 25 } 26 27 public static void main(String[] args) throws InterruptedException { 28 SimpleRateLimiter limiter = new SimpleRateLimiter(); 29 for (int i = 0; i < 20; i++) { 30 System.out.println(limiter.isActionAllowed("user","login",60,5)); 31 Thread.sleep(5000); 32 } 33 RedisUtils.close(); 34 } 35 }
十一、漏斗限流
Redis4.0提供一个限流Redis模块:Redis-Cell。这个模块使用了漏斗限流算法,并提供原子的限流指令。
漏斗限流主要是控制漏嘴流出的速度与进入漏斗的速度。
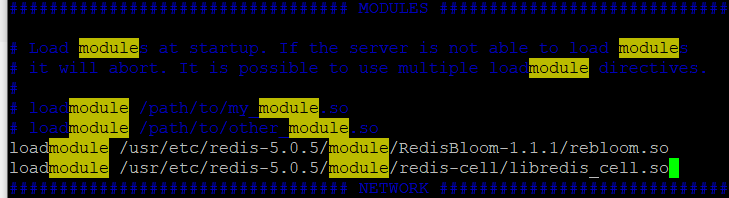
wget https://github.com/brandur/redis-cell/releases/download/v0.2.4/redis-cell-v0.2.4-x86_64-unknown-linux-gnu.tar.gz tar -zxvf *gz //redis.conf中指定路径
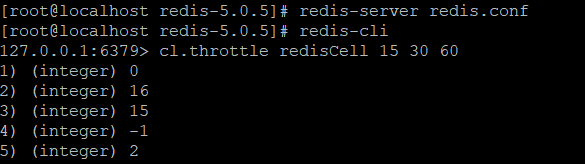
指令集:仅有一条指令cl.throttle
127.0.0.1:6379> cl.throttle redisCell 15 30 60 1) (integer) 0 //0:允许进去,1拒绝 2) (integer) 16 //漏斗容量 3) (integer) 15 //剩余容量 4) (integer) -1 //若被拒绝,多久后重试,单位s,-1永不 5) (integer) 2 //多长时间,容量全部释放(漏嘴漏出)
十二、GeoHash
GeoHash是业界比较通用的地理位置距离排序算法,Redis添加了GeoHash模块。
原理:Geo算法将二维的经纬度数据映射到一维的整数,这样所有地址就是在一条线上,距离靠近的经纬度坐标,映射到一维后的数据,两点之间的距离也会很接近.
怎样映射?
二刀法,将地球看成一个二维平面,然后
两刀切割分成4块,编码00,01,10,11
然后将这四块分别两刀切割,编码0000,0001,0010,0011......1100,1101,1110,1111共16块
然后继续切分......二进制整数会越来越长,精度也就越来越高。
切割算法有很多,具体的描述,例如从地球上找到我现在的位置,首先我是地球人,然后按国家切割,我是中国人,再按省切割,我是湖北人,湖北加油,武汉加油,中国加油。
指令集:
//redis-cli //help @geo GEOADD key longitude latitude member [longitude latitude member ...] GEODIST key member1 member2 [unit] GEOHASH key member [member ...] GEOPOS key member [member ...] GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
测试代码:
1 public class GeoHashTest { 2 3 public static void main(String[] args){ 4 try(Jedis jedis = RedisUtils.getJedis();){ 5 //添加地点经纬度 6 jedis.geoadd("addr",114.404105,30.511786,"GuangGu Square"); 7 jedis.geoadd("addr",114.367382,30.536487,"Wuhan University"); 8 jedis.geoadd("addr",114.420634,30.513279,"Huazhong University"); 9 jedis.geoadd("addr",114.411723,30.482473,"GuangGu Software Park"); 10 //两地点距离 默认M设置单位 11 System.out.println(jedis.geodist("addr","Wuhan University","Huazhong University",GeoUnit.KM)); 12 System.out.println(jedis.geodist("addr","GuangGu Square","GuangGu Software Park")); 13 //获取地点经纬度 14 System.out.println(jedis.geopos("addr","GuangGu Square")); 15 //获取地点hash值 16 System.out.println(jedis.geohash("addr","GuangGu Square")); 17 //搜索地点附近3KM以内的地点 18 List<GeoRadiusResponse> res = jedis.georadiusByMember("addr","GuangGu Square",3,GeoUnit.KM); 19 for (GeoRadiusResponse re : res) { 20 System.out.println(re.getMemberByString()); 21 } 22 }
23 RedisUtils.close(); 24 } 25 }
《redis深度历险》