1.在HADOOP扮演的角色
JournalNode是在MR2也就是Yarn中新加的,journalNode的作用是存放EditLog的,
在MR1中editlog是和fsimage存放在一起的然后SecondNamenode做定期合并,Yarn在这上面就不用SecondNamanode了.
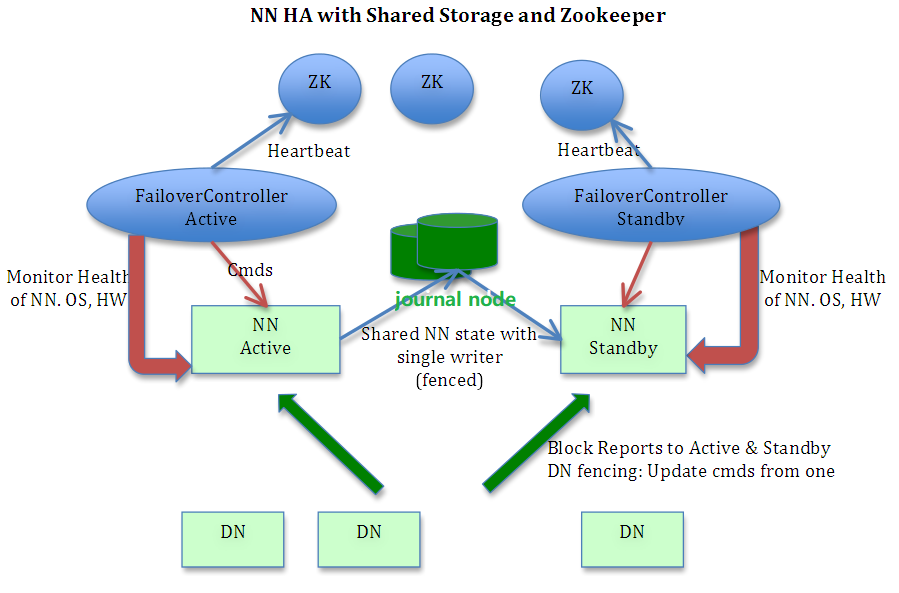
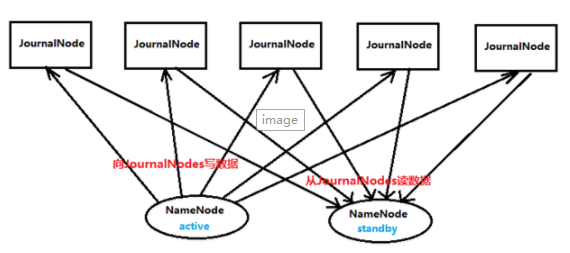
Active Namenode与StandBy Namenode之间的就是JournalNode,作用相当于NFS共享文件系统.Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步.
配置文件是;hdfs-site.xml文件负责

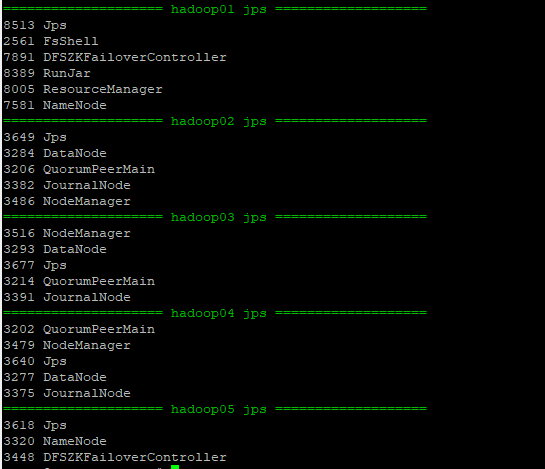
最后进程JPS如下图:
2.作用
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。
standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
3.资源配置
NameNode服务器:运行NameNode的服务器应该有相同的硬件配置。
* JournalNode服务器:运行的JournalNode进程非常轻量,可以部署在其他的服务器上。注意:必须允许至少3个节点。当然可以运行更多,但是必须是奇数个,如3、5、7、9个等等。
当运行N个节点时,系统可以容忍至少(N-1)/2(N至少为3)个节点失败而不影响正常运行。
在HA集群中,standby状态的NameNode可以完成checkpoint操作,因此没必要配置Secondary NameNode、CheckpointNode、BackupNode。如果真的配置了,还会报错。