b站自我充电
tips 学完这一章你可以
知道Kafka基本原理,了解关键术语概念
可以使用Kafka进行消息系统开发
通过Java语言来使用Kafka进行消息收发
Kafka最初是由LinkedIn公司采用Scala语言开发的一个多分区、多副本并且基于ZooKeeper协调的分布
式消息系统,现在已经捐献给了Apache基金会。目前Kafka已经定位为一个分布式流式处理平台,它以
高吞吐、可持久化、可水平扩展、支持流处理等多种特性而被广泛应用。
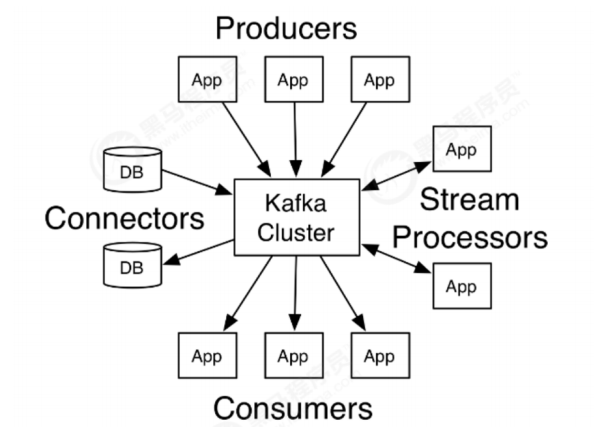
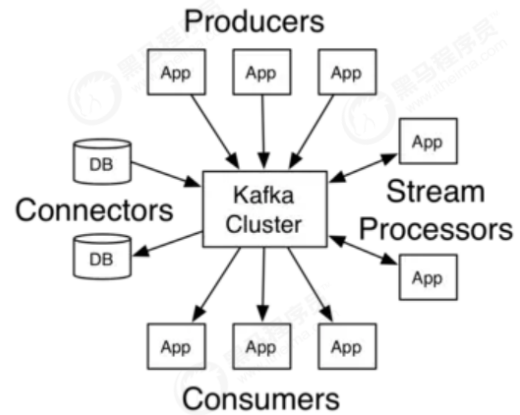
Apache Kafka是一个分布式的发布-订阅消息系统,能够支撑海量数据的数据传递。在离线和实时的消
息处理业务系统中,Kafka都有广泛的应用。Kafka将消息持久化到磁盘中,并对消息创建了备份保证了
数据的安全。Kafka在保证了较高的处理速度的同时,又能保证数据处理的低延迟和数据的零丢失。
特性
(1)高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个主题可以
分多个分区, 消费组对分区进行消费操作;
(2)可扩展性:kafka集群支持热扩展;
(3)持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
(4)容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
(5)高并发:支持数千个客户端同时读写;
用处
(1)日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放
给各种consumer,例如Hadoop、Hbase、Solr等;
(2)消息系统:解耦和生产者和消费者、缓存消息等;
(3)用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点
击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时
的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘;
(4)运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作
的集中反馈,比如报警和报告;
(5)流式处理:比如spark streaming和storm;
技术优势
可伸缩性:Kafka 的两个重要特性造就了它的可伸缩性。
1、Kafka 集群在运行期间可以轻松地扩展或收缩(可以添加或删除代理),而不会宕机。
2、可以扩展一个 Kafka 主题来包含更多的分区。由于一个分区无法扩展到多个代理,所以它的容量受
到代理磁盘空间的限制。能够增加分区和代理的数量意味着单个主题可以存储的数据量是没有限制的。
容错性和可靠性:Kafka 的设计方式使某个代理的故障能够被集群中的其他代理检测到。由于每个主题
都可以在多个代理上复制,所以集群可以在不中断服务的情况下从此类故障中恢复并继续运行。
吞吐量:代理能够以超快的速度有效地存储和检索数据。
适应人群
本教程为专注于使用Apache Kafka消息传递系统或者大数据分析领域发展事业的专业人士做好准备,它
将给你足够的理解如何使用Kafka集群。
课程亮点
l 知识覆盖度广泛;
l 知识覆盖度深入;
l 由浅入深讲解思路;
l 案例分析全面;
l 适应于想学习Kafka技术的不同人群;
Apache官网:http://apache.org
Kafka官网:http://kafka.apache.org
1.1 概念详解

Producer
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,
broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition
中,生产者也可以指定数据存储的partition。
Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
Topic
在Kafka中,使用一个类别属性来划分数据的所属类,划分数据的这个类称为topic。如果把Kafka看做
为一个数据库,topic可以理解为数据库中的一张表,topic的名字即为表名。
Partition
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使
用多个segment文件存储。partition中的数据是有序的,partition间的数据丢失了数据的顺序。如果
topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,
需要将partition数目设为1。
Partition offffset
每条消息都有一个当前Partition下唯一的64字节的offffset,它指明了这条消息的起始位置。
Replicas of partition
副本是一个分区的备份。副本不会被消费者消费,副本只用于防止数据丢失,即消费者不从为follower
的partition中消费数据,而是从为leader的partition中读取数据。副本之间是一主多从的关系。
Broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。broker存储topic的数据。如果某topic有
N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。如果某topic有N个
partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个
broker不存储该topic的partition数据。如果某topic有N个partition,集群中broker数目少于N个,那么
一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种
情况容易导致Kafka集群数据不均衡。
Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的
partition。
Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与
Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与
Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重
新创建一个Follower。
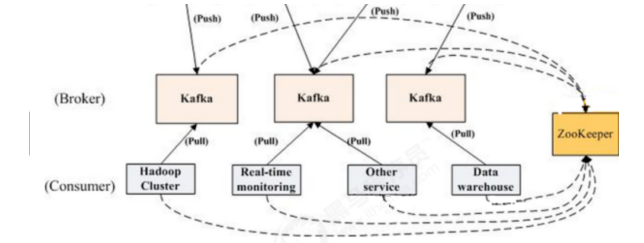
Zookeeper
Zookeeper负责维护和协调broker。当Kafka系统中新增了broker或者某个broker发生故障失效时,由
ZooKeeper通知生产者和消费者。生产者和消费者依据Zookeeper的broker状态信息与broker协调数据
的发布和订阅任务。
AR(Assigned Replicas)
分区中所有的副本统称为AR。
ISR(In-Sync Replicas)
所有与Leader部分保持一定程度的副(包括Leader副本在内)本组成ISR。
OSR(Out-of-Sync-Replicas)
与Leader副本同步滞后过多的副本。
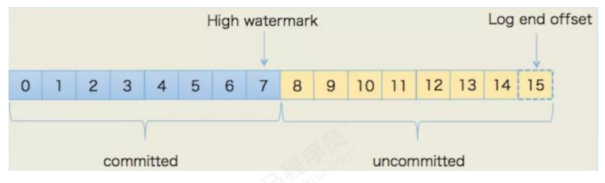
HW(High Watermark)
高水位,标识了一个特定的offffset,消费者只能拉取到这个offffset之前的消息。
LEO(Log End Offffset)
即日志末端位移(log end offffset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消
息!也就是说,如果LEO=10,那么表示该副本保存了10条消息,位移值范围是[0, 9]。
1.2 安装与配置
1.2.1 java环境
我们使用Linux系统进行教学演示,通过虚拟机安装CentOS或者Win10系统自己挂载的ubuntu系统都
可以。
首先需要安装Java环境,同时配置环境变量,步骤如下:
官网下载JDK

解压缩,放到指定目录
配置环境变量
在/etc/profifile文件中配置如下变量
export JAVA_HOME=/java/jdk-12.0.1
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=.:$JAVA_HOME/bin:$JRE_HOME/bin:$KE_HOME/bin:${MAVEN_HOME}/bin:$PATH
测试jdk

1.2.2 ZooKeeper的安装
Zookeeper是安装Kafka集群的必要组件,Kafka通过Zookeeper来实施对元数据信息的管理,包括集
群、主题、分区等内容。
同样在官网下载安装包到指定目录解压缩,步骤如下:
ZooKeeper官网:http://zookeeper.apache.org/

修改Zookeeper的配置文件,首先进入安装路径conf目录,并将zoo_sample.cfg文件修改为
zoo.cfg,并对核心参数进行配置。
文件内容如下:
# The number of milliseconds of each tick
# zk服务器的心跳时间
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
# 投票选举新Leader的初始化时间
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 数据目录
dataDir=temp/zookeeper/data
# 日志目录
dataLogDir=temp/zookeeper/log
# the port at which the clients will connect
# Zookeeper对外服务端口,保持默认
clientPort=2181
启动Zookeeper命令:bin/zkServer.sh start
itcast@Server-node:/mnt/d/zookeeper-3.4.14$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /mnt/d/zookeeper-3.4.14/bin/../conf/zoo.cfg
//启动成功
Starting zookeeper ... STARTED
itcast@Server-node:/mnt/d/zookeeper-3.4.14$
1.2.3 Kafka的安装与配置
官网下载安装解压缩:http://kafka.apache.org/downloads

下载解压启动
启动命令:bin/kafka-server-start.sh confifig/server.properties
server.properties配置中需要关注以下几个参数:
broker.id=0 表示broker的编号,如果集群中有多个broker,则每个broker的编号需要设置
的不同
listeners=PLAINTEXT://:9092 brokder对外提供的服务入口地址
advertised.listeners=PLAINTEXT://you.host.name:9092
log.dirs=/tmp/kafka/log 设置存放消息日志文件的地址
zookeeper.connect=localhost:2181 Kafka所需Zookeeper集群地址,教学中Zookeeper和
Kafka都安装本机
启动成功如下显示:

启动成功之后重新打开一个终端,验证启动进程

1.2.4 Kafka测试消息生产与消费
首先创建一个主题
命令如下:
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic heima --partitions 2 --replication-factor 1
--zookeeper:指定了Kafka所连接的Zookeeper服务地址
--topic:指定了所要创建主题的名称
--partitions:指定了分区个数
--replication-factor:指定了副本因子
--create:创建主题的动作指令
如:
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --zookeeper
localhost:2181 --create --topic heima --partitions 2 -
-replication-factor 1
//主题创建成功
Created topic heima.
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
展示所有主题
命令:bin/kafka-topics.sh --zookeeper localhost:2181 --list
如:
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --zookeeper
localhost:2181 --list
heima
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
查看主题详情
命令:bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic heima
--describe 查看详情动作指令
如:
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --zookeeper
localhost:2181 --describe --topic heima
Topic:heima PartitionCount:2 ReplicationFactor:1 Configs:
Topic: heima Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: heima Partition: 1 Leader: 0 Replicas: 0 Isr: 0
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
启动消费端接收消息
命令:bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic heima
--bootstrap-server 指定了连接Kafka集群的地址
--topic 指定了消费端订阅的主题
如:
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-console-consumer.sh --
bootstrap-server localhost:9092 --topic heima
Hello,Kafka!
生产端发送消息
命令:bin/kafka-console-producer.sh --broker-list localhost:9092 --topic heima
--broker-list 指定了连接的Kafka集群的地址
--topic 指定了发送消息时的主题
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-console-producer.sh --
broker-list localhost:9092 --topic heima
>Hello,Kafka!
>
1.3 Java第一个程序
通过Java程序来进行Kafka收发消息的教学演示
1.3.1 准备
Kafka自身提供的Java客户端来演示消息的收发,与Kafka的Java客户端相关的Maven依赖如下:
<properties>
<scala.version>2.11</scala.version>
<slf4j.version>1.7.21</slf4j.version>
<kafka.version>2.0.0</kafka.version>
<lombok.version>1.18.8</lombok.version>
<junit.version>4.11</junit.version>
<gson.version>2.2.4</gson.version>
<protobuff.version>1.5.4</protobuff.version>
<spark.version>2.3.1</spark.version>
</properties>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
1.3.2 创建生产者
见代码库 com.heima.kafka.chapter1.ProducerFastStart
/**
* Kafka 消息生产者
*/
public class ProducerFastStart {
// Kafka集群地址
private static final String brokerList = "localhost:9092";
// 主题名称-之前已经创建
private static final String topic = "heima";
public static void main(String[] args) {
Properties properties = new Properties();
// 设置key序列化器
properties.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
//另外一种写法
//properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 设置重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 10);
// 设置值序列化器
properties.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// 设置集群地址
properties.put("bootstrap.servers", brokerList);
// KafkaProducer 线程安全
KafkaProducer<String, String> producer = new KafkaProducer<>
(properties);
ProducerRecord<String, String> record = new ProducerRecord<>(topic,
"Kafka-demo-001", "hello, Kafka!");
try {
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
}
producer.close();
}
}
1.3.3 创建消费者
见代码库 com.heima.kafka.chapter1.ConsumerFastStart
*/
public class ProducerFastStart {
// Kafka集群地址
private static final String brokerList = "localhost:9092";
// 主题名称-之前已经创建
private static final String topic = "heima";
public static void main(String[] args) {
Properties properties = new Properties();
// 设置key序列化器
properties.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
//另外一种写法
//properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 设置重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 10);
// 设置值序列化器
properties.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// 设置集群地址
properties.put("bootstrap.servers", brokerList);
// KafkaProducer 线程安全
KafkaProducer<String, String> producer = new KafkaProducer<>
(properties);
ProducerRecord<String, String> record = new ProducerRecord<>(topic,
"Kafka-demo-001", "hello, Kafka!");
try {
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
}
producer.close();
}
}
/**
* Kafka 消息消费者
*/
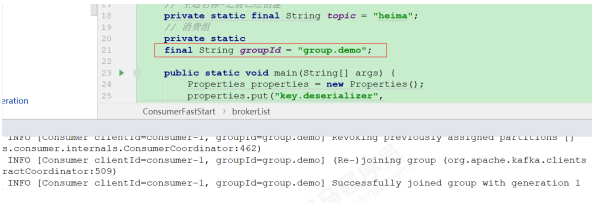
public class ConsumerFastStart {
// Kafka集群地址
private static final String brokerList = "127.0.0.1:9092";
// 主题名称-之前已经创建
private static final String topic = "heima";
// 消费组
private static final String groupId = "group.demo";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
operties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("bootstrap.servers", brokerList);
properties.put("group.id", groupId);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>
(properties);
consumer.subscribe(Collections.singletonList(topic));
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
}
}
1.3.4 效果展示
waring:使用java连接linux下kafka集群需要设置hosts绑定;
先启动消费端,再启动生产端进行消息的发送


1.4 服务端常用参数配置
参数配置:confifig/server.properties
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ egrep
'zookeeper|listeners|broker.id|log.dir|log.dirs' config/server.properties
broker.id=0
# listeners = listener_name://host_name:port
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092
# it uses the value for "listeners" if configured. Otherwise, it will use the
value
#advertised.listeners=PLAINTEXT://your.host.name:9092
#log.dirs=/tmp/kafka-logs
log.dirs=/tmp/kafka/log
# Zookeeper connection string (see zookeeper docs for details).
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ egrep
'zookeeper|listeners|broker.id|log.dir|log.dirs|message.max'
config/server.properties
broker.id=0
# listeners = listener_name://host_name:port
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092
# it uses the value for "listeners" if configured. Otherwise, it will use the
value
#advertised.listeners=PLAINTEXT://your.host.name:9092
#log.dirs=/tmp/kafka-logs
log.dirs=/tmp/kafka/log
# Zookeeper connection string (see zookeeper docs for details).
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
1.4.1 zookeeper.connect
指明Zookeeper主机地址,如果zookeeper是集群则以逗号隔开,如:
172.6.14.61:2181,172.6.14.62:2181,172.6.14.63:2181
1.4.2 listeners
监听列表,broker对外提供服务时绑定的IP和端口。多个以逗号隔开,如果监听器名称不是一个安全的
协议, listener.security.protocol.map也必须设置。主机名称设置0.0.0.0绑定所有的接口,主机名称为
空则绑定默认的接口。如:PLAINTEXT://myhost:9092,SSL://:9091
CLIENT://0.0.0.0:9092,REPLICATION://localhost:9093
1.4.3 broker.id
broker的唯一标识符,如果不配置则自动生成,建议配置且一定要保证集群中必须唯一,默认-1
1.4.4 log.dirs
日志数据存放的目录,如果没有配置则使用log.dir,建议此项配置。
1.4.5 message.max.bytes
服务器接受单个消息的最大大小,默认1000012 约等于976.6KB。
总结:
通过本章的介绍,相信对Kafka已经有了初步的了解,并且能够快速安装Zookeeper、Kafka组件,并且
通过Kafka自身命令进行消息的发送与订阅,对服务端重要参数有了初步的认识,能够通过Java客户端
编写Java程序,完成消息的发布与订阅。
第2章 生产者详解
tips 学完这一章你可以
深入学习Kafka数据生产大致流程
如何创建并使用Kafka生产者
Kafka生产者常用配置
2.1 消息发送
2.1.1 Kafka Java客户端数据生产流程解析
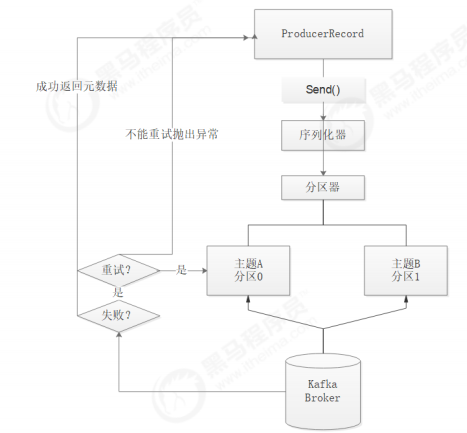
①、首先要构造一个 ProducerRecord 对象,该对象可以声明主题Topic、分区Partition、键 Key以及
值 Value,主题和值是必须要声明的,分区和键可以不用指定。
②、调用send() 方法进行消息发送。
③、因为消息要到网络上进行传输,所以必须进行序列化,序列化器的作用就是把消息的 key 和
value对象序列化成字节数组。
后,生产者就知道该往哪个主题和分区发送记录了。
⑤、接着这条记录会被添加到一个记录批次里面,这个批次里所有的消息会被发送到相同的主题和
分区。会有一个独立的线程来把这些记录批次发送到相应的 Broker 上。
③、Broker成功接收到消息,表示发送成功,返回消息的元数据(包括主题和分区信息以及记录在
分区里的偏移量)。发送失败,可以选择重试或者直接抛出异常。
依赖的包 <kafka.version>2.0.0</kafka.version>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_${scala.version}</artifactId>
<version>${kafka.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
2.1.2 必要参数配置
见代码库:com.heima.kafka.chapter2.KafkaProducerAnalysis
public static Properties initConfig() {
Properties props = new Properties();
// 该属性指定 brokers 的地址清单,格式为 host:port。清单里不需要包含所有的 broker
地址,
// 生产者会从给定的 broker 里查找到其它 broker 的信息。——建议至少提供两个 broker
的信息,因为一旦其中一个宕机,生产者仍然能够连接到集群上。
props.put("bootstrap.servers", brokerList);
// 将 key 转换为字节数组的配置,必须设定为一个实现了
org.apache.kafka.common.serialization.Serializer 接口的类,
// 生产者会用这个类把键对象序列化为字节数组。
// ——kafka 默认提供了 StringSerializer和 IntegerSerializer、
ByteArraySerializer。当然也可以自定义序列化器。
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// 和 key.serializer 一样,用于 value 的序列化
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
生成一个非空字符串。
// 内容形式如:"producer-1"
props.put("client.id", "producer.client.id.demo");
return props;
}
Properties props = initConfig();
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// KafkaProducer<String, String> producer = new KafkaProducer<>(props,
// new StringSerializer(), new StringSerializer());
//生成 ProducerRecord 对象,并制定 Topic,key 以及 value
ProducerRecord<String, String> record = new ProducerRecord<>(topic,
"hello, Kafka!");
try {
// 发送消息
producer.send(record);
2.13 发送类型
发送即忘记
producer.send(record)
同步发送
//通过send()发送完消息后返回一个Future对象,然后调用Future对象的get()方法等待kafka响应
//如果kafka正常响应,返回一个RecordMetadata对象,该对象存储消息的偏移量
// 如果kafka发生错误,无法正常响应,就会抛出异常,我们便可以进行异常处理
producer.send(record).get();
异步发送
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println(metadata.partition() + ":" + metadata.offset());
}
}
});
2.1.4 序列化器
消息要到网络上进行传输,必须进行序列化,而序列化器的作用就是如此。
Kafka 提供了默认的字符串序列化器(org.apache.kafka.common.serialization.StringSerializer),
还有整型(IntegerSerializer)和字节数组(BytesSerializer)序列化器,这些序列化器都实现了接口
(org.apache.kafka.common.serialization.Serializer)基本上能够满足大部分场景的需求。
2.1.5 自定义序列化器
见代码库:com.heima.kafka.chapter2.CompanySerializer
/**
* 自定义序列化器
public class CompanySerializer implements Serializer<Company> {
@Override
public void configure(Map configs, boolean isKey) {
}
@Override
public byte[] serialize(String topic, Company data) {
if (data == null) {
return null;
}
byte[] name, address;
try {
if (data.getName() != null) {
name = data.getName().getBytes("UTF-8");
} else {
name = new byte[0];
}
if (data.getAddress() != null) {
address = data.getAddress().getBytes("UTF-8");
} else {
address = new byte[0];
}
ByteBuffer buffer = ByteBuffer.
allocate(4 + 4 + name.length + address.length);
buffer.putInt(name.length);
buffer.put(name);
buffer.putInt(address.length);
buffer.put(address);
return buffer.array();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return new byte[0];
}
@Override
public void close() {
}
}
使用自定义的序列化器
见代码库:com.heima.kafka.chapter2.ProducerDefifineSerializer
public class ProducerDefineSerializer {
public static final String brokerList = "localhost:9092";
public static final String topic = "heima";
public static void main(String[] args)
throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
CompanySerializer.class.getName());
// properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
// ProtostuffSerializer.class.getName());
properties.put("bootstrap.servers", brokerList);
KafkaProducer<String, Company> producer =
new KafkaProducer<>(properties);
Company company = Company.builder().name("kafka")
.address("北京").build();
// Company company = Company.builder().name("hiddenkafka")
// .address("China").telphone("13000000000").build();
ProducerRecord<String, Company> record =
new ProducerRecord<>(topic, company);
producer.send(record).get();
}
}
2.1.6 分区器.
本身kafka有自己的分区策略的,如果未指定,就会使用默认的分区策略:
Kafka根据传递消息的key来进行分区的分配,即hash(key) % numPartitions。如果Key相同的话,那么
就会分配到统一分区。
源代码org.apache.kafka.clients.producer.internals.DefaultPartitioner分析
public int partition(String topic, Object key, byte[] keyBytes, Object value,
byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = this.nextValue(topic);
List<PartitionInfo> availablePartitions =
cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) %
availablePartitions.size();
return
((PartitionInfo)availablePartitions.get(part)).partition();
} else {
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
自定义分区器见代码库 com.heima.kafka.chapter2.DefifinePartitioner
/**
* 自定义分区器
*/
public class DefinePartitioner implements Partitioner {
private final AtomicInteger counter = new AtomicInteger(0);
@Override
public int partition(String topic, Object key, byte[] keyBytes,
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (null == keyBytes) {
return counter.getAndIncrement() % numPartitions;
} else
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
实现自定义分区器需要通过配置参数ProducerConfifig.PARTITIONER_CLASS_CONFIG来实现
// 自定义分区器的使用
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,DefinePartitioner.class.getNam
e());
2.1.7 拦截器
Producer拦截器(interceptor)是个相当新的功能,它和consumer端interceptor是在Kafka 0.10版本被
引入的,主要用于实现clients端的定制化控制逻辑。
生产者拦截器可以用在消息发送前做一些准备工作。
使用场景
1、按照某个规则过滤掉不符合要求的消息
2、修改消息的内容
3、统计类需求
见代码库:自定义拦截器com.heima.kafka.chapter2.ProducerInterceptorPrefifix
/**
* 自定义拦截器
*/
public class ProducerInterceptorPrefix implements
ProducerInterceptor<String, String> {
private volatile long sendSuccess = 0;
private volatile long sendFailure = 0;
@Override
public ProducerRecord<String, String> onSend(
ProducerRecord<String, String> record) {
String modifiedValue = "prefix1-" + record.value();
return new ProducerRecord<>(record.topic(),
record.partition(), record.timestamp(),
record.key(), modifiedValue, record.headers());
// if (record.value().length() < 5) {
// throw new RuntimeException();
}
// return record;
}
@Override
public void onAcknowledgement(
RecordMetadata recordMetadata,
Exception e) {
if (e == null) {
sendSuccess++;
} else {
sendFailure++;
}
}
@Override
public void close() {
double successRatio = (double) sendSuccess / (sendFailure +
sendSuccess);
System.out.println("[INFO] 发送成功率="
+ String.format("%f", successRatio * 100) + "%");
}
@Override
public void configure(Map<String, ?> map) {
}
}
实现自定义拦截器之后需要在配置参数中指定这个拦截器,此参数的默认值为空,如下:
// 自定义拦截器使用
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,ProducerDefineSerializer.cla
ss.getName());
功能演示:
发送端

接收端

2.2 发送原理剖析

消息发送的过程中,涉及到两个线程协同工作,主线程首先将业务数据封装成ProducerRecord对象,
之后调用send()方法将消息放入RecordAccumulator(消息收集器,也可以理解为主线程与Sender线程
直接的缓冲区)中暂存,Sender线程负责将消息信息构成请求,并最终执行网络I/O的线程,它从
RecordAccumulator中取出消息并批量发送出去,需要注意的是,KafkaProducer是线程安全的,多个
线程间可以共享使用同一个KafkaProducer对象
2.3 其他生产者参数
之前提及的默认三个客户端参数,大部分参数都有合理的默认值,一般情况下不需要修改它们,
参考官网:http://kafka.apache.org/documentation/#producerconfifigs
2.3.1 acks
这个参数用来指定分区中必须有多少个副本收到这条消息,之后生产者才会认为这条消息时写入成功
的。acks是生产者客户端中非常重要的一个参数,它涉及到消息的可靠性和吞吐量之间的权衡。
ack=0, 生产者在成功写入消息之前不会等待任何来自服务器的相应。如果出现问题生产者是感知
不到的,消息就丢失了。不过因为生产者不需要等待服务器响应,所以它可以以网络能够支持的最
大速度发送消息,从而达到很高的吞吐量。
ack=1,默认值为1,只要集群的首领节点收到消息,生产这就会收到一个来自服务器的成功响
应。如果消息无法达到首领节点(比如首领节点崩溃,新的首领还没有被选举出来),生产者会收
到一个错误响应,为了避免数据丢失,生产者会重发消息。但是,这样还有可能会导致数据丢失,
如果收到写成功通知,此时首领节点还没来的及同步数据到follower节点,首领节点崩溃,就会导
致数据丢失。
ack=-1, 只有当所有参与复制的节点都收到消息时,生产这会收到一个来自服务器的成功响应,
这种模式是最安全的,它可以保证不止一个服务器收到消息。
注意:acks参数配置的是一个字符串类型,而不是整数类型,如果配置为整数类型会抛出以下异常
2.3.2 retries
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领)。在这种情况下,如果达到
了 retires 设置的次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待
100ms,可以通过 retry.backoff.ms 参数来修改这个时间间隔。
2.3.3 batch.size
当有多个消息要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可
以使用的内存大小,按照字节数计算,而不是消息个数。当批次被填满,批次里的所有消息会被发送出
去。不过生产者并不一定都会等到批次被填满才发送,半满的批次,甚至只包含一个消息的批次也可能
被发送。所以就算把 batch.size 设置的很大,也不会造成延迟,只会占用更多的内存而已,如果设置
的太小,生产者会因为频繁发送消息而增加一些额外的开销。
2.3.4 max.request.size
该参数用于控制生产者发送的请求大小,它可以指定能发送的单个消息的最大值,也可以指单个请求里
所有消息的总大小。 broker 对可接收的消息最大值也有自己的限制( message.max.size ),所以两
边的配置最好匹配,避免生产者发送的消息被 broker 拒绝。
总结
本章主要讲了生产者客户端的用法以及整体流程架构,主要内容包括配置参数的详解、消息的发送方
式、序列化器、分区器、拦截器等,在实际使用中,Kafka已经提供了良好的Java客户端支持,提高了
开发效率。
第3章 消费者详解
tips 学完这一章你可以、
深入学习Kafka数据消费大致流程
如何创建并使用Kafka消费者
Kafka消费者常用配置
3.1 概念入门
3.1.1 消费者和消费组
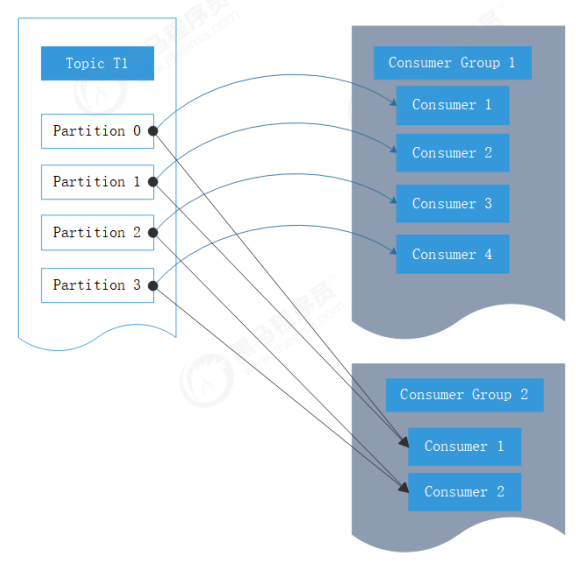
Kafka消费者是消费组的一部分,当多个消费者形成一个消费组来消费主题时,每个消费者会收到不同
分区的消息。假设有一个T1主题,该主题有4个分区;同时我们有一个消费组G1,这个消费组只有一个
消费者C1。那么消费者C1将会收到这4个分区的消息,如下所示:
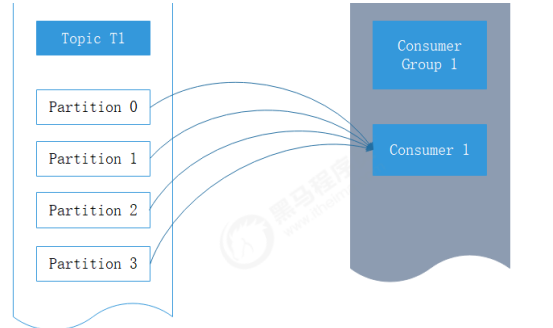
Kafka一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。换句话说,
每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。对
于上面的例子,假如我们新增了一个新的消费组G2,而这个消费组有两个消费者,那么会是这样的:
3.2 消息接收
见代码库:com.heima.kafka.chapter3.KafkaConsumerAnalysis
3.2.1 必要参数设置
KafkaConsumer实例中参数众多,后续会深入讲解
public static Properties initConfig() {
Properties props = new Properties();
// 与KafkaProducer中设置保持一致
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
// 必填参数,该参数和KafkaProducer中的相同,制定连接Kafka集群所需的broker地址清
单,可以设置一个或者多个
props.put("bootstrap.servers", brokerList);
// 消费者隶属于的消费组,默认为空,如果设置为空,则会抛出异常,这个参数要设置成具有一
定业务含义的名称
props.put("group.id", groupId);
// 指定KafkaConsumer对应的客户端ID,默认为空,如果不设置KafkaConsumer会自动生成
一个非空字符串
props.put("client.id", "consumer.client.id.demo");
return props;
}
3.2.2 订阅主题和分区
创建完消费者后我们便可以订阅主题了,只需要通过调用subscribe()方法即可,这个方法接收一个主题
列表
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
另外,我们也可以使用正则表达式来匹配多个主题,而且订阅之后如果又有匹配的新主题,那么这个消
费组会立即对其进行消费。正则表达式在连接Kafka与其他系统时非常有用。比如订阅所有的测试主
题:
consumer.subscribe(Pattern.compile("heima*"));
指定订阅的分区
// 指定订阅的分区
consumer.assign(Arrays.asList(new TopicPartition("topic0701", 0)));
3.2.2 反序列化
与KafkaProducer中设置保持一致
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
3.2.3 位移提交
对于Kafka中的分区而言,它的每条消息都有唯一的offffset,用来表示消息在分区中的位置。
当我们调用poll()时,该方法会返回我们没有消费的消息。当消息从broker返回消费者时,broker并不
跟踪这些消息是否被消费者接收到;Kafka让消费者自身来管理消费的位移,并向消费者提供更新位移
的接口,这种更新位移方式称为提交(commit)。
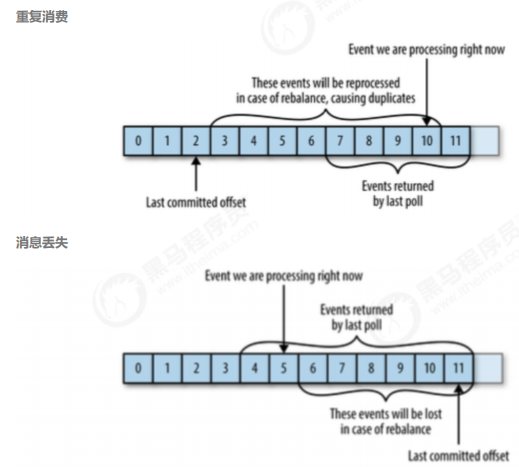
自动提交
这种方式让消费者来管理位移,应用本身不需要显式操作。当我们将enable.auto.commit设置为true,
那么消费者会在poll方法调用后每隔5秒(由auto.commit.interval.ms指定)提交一次位移。和很多其
他操作一样,自动提交也是由poll()方法来驱动的;在调用poll()时,消费者判断是否到达提交时间,如
果是则提交上一次poll返回的最大位移。
需要注意到,这种方式可能会导致消息重复消费。假如,某个消费者poll消息后,应用正在处理消息,
在3秒后Kafka进行了重平衡,那么由于没有更新位移导致重平衡后这部分消息重复消费。
同步提交
见代码库:com.heima.kafka.chapter3.CheckOffffsetAndCommit
public static Properties initConfig() {
Properties props = new Properties();
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 手动提交开启
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
return props;
}
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
if (records.isEmpty()) {
break;
}
List<ConsumerRecord<String, String>> partitionRecords =
records.records(tp);
lastConsumedOffset = partitionRecords.get(partitionRecords.size() -
1).offset();
consumer.commitSync();//同步提交消费位移
}
异步提交
手动提交有一个缺点,那就是当发起提交调用时应用会阻塞。当然我们可以减少手动提交的频率,但这
个会增加消息重复的概率(和自动提交一样)。另外一个解决办法是,使用异步提交的API。
见代码:com.heima.kafka.chapter3.OffffsetCommitAsyncCallback
但是异步提交也有个缺点,那就是如果服务器返回提交失败,异步提交不会进行重试。相比较起来,同
步提交会进行重试直到成功或者最后抛出异常给应用。异步提交没有实现重试是因为,如果同时存在多
个异步提交,进行重试可能会导致位移覆盖。举个例子,假如我们发起了一个异步提交commitA,此时
的提交位移为2000,随后又发起了一个异步提交commitB且位移为3000;commitA提交失败但
commitB提交成功,此时commitA进行重试并成功的话,会将实际上将已经提交的位移从3000回滚到
2000,导致消息重复消费。
异步回调
try {
while (running.get()) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
//do some logical processing.
}
// 异步回调
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition,
OffsetAndMetadata> offsets,
Exception exception) {
if (exception == null) {
System.out.println(offsets);
} else {
log.error("fail to commit offsets {}", offsets,
exception);
}
}
});
}
} finally {
consumer.close();
}
3.2.4 指定位移消费
到目前为止,我们知道消息的拉取是根据poll()方法中的逻辑来处理的,但是这个方法对于普通开发人
员来说就是个黑盒处理,无法精确掌握其消费的起始位置。
seek()方法正好提供了这个功能,让我们得以追踪以前的消费或者回溯消费。
见代码库:com.heima.kafka.chapter3.SeekDemo
/**
* 指定位移消费
*/
public class SeekDemo extends ConsumerClientConfig {
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
// timeout参数设置多少合适?太短会使分区分配失败,太长又有可能造成一些不必要的等待
consumer.poll(Duration.ofMillis(2000));
// 获取消费者所分配到的分区
Set<TopicPartition> assignment = consumer.assignment();
System.out.println(assignment);
for (TopicPartition tp : assignment) {
// 参数partition表示分区,offset表示指定从分区的哪个位置开始消费
consumer.seek(tp, 10);
}
// consumer.seek(new TopicPartition(topic,0),10);
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
//consume the record.
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.offset() + ":" + record.value());
}
}
}
增加判断是否分配到了分区,见代码库:com.heima.kafka.chapter3.SeekDemoAssignment
public static void main(String[] args) {
Properties props = initConfig();
afkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
long start = System.currentTimeMillis();
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) {
consumer.poll(Duration.ofMillis(100));
assignment = consumer.assignment();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(assignment);
for (TopicPartition tp : assignment) {
consumer.seek(tp, 10);
}
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
//consume the record.
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.offset() + ":" + record.value());
}
}
}
指定从分区末尾开始消费 ,见代码库:com.heima.kafka.chapter3.SeekToEnd
// 指定从分区末尾开始消费
Map<TopicPartition, Long> offsets = consumer.endOffsets(assignment);
for (TopicPartition tp : assignment) {
consumer.seek(tp, offsets.get(tp));
}
演示位移越界操作,修改代码如下:
for (TopicPartition tp : assignment) {
//consumer.seek(tp, offsets.get(tp));
consumer.seek(tp, offsets.get(tp) + 1);
}
会通过auto.offffset.reset参数的默认值将位置重置,效果如下:
INFO [Consumer clientId=consumer-1, groupId=group.heima] Fetch offset 1 is out
of range for partition heima-0, resetting offset
(org.apache.kafka.clients.consumer.internals.Fetcher:967)
INFO [Consumer clientId=consumer-1, groupId=group.heima] Fetch offset 10 is out
of range for partition heima-1, resetting offset
(org.apache.kafka.clients.consumer.internals.Fetcher:967)
INFO [Consumer clientId=consumer-1, groupId=group.heima] Resetting offset for
partition heima-0 to offset 0.
(org.apache.kafka.clients.consumer.internals.Fetcher:583)
INFO [Consumer clientId=consumer-1, groupId=group.heima] Resetting offset for
partition heima-1 to offset 9.
(org.apache.kafka.clients.consumer.internals.Fetcher:583)
3.2.4 再均衡监听器
再均衡是指分区的所属从一个消费者转移到另外一个消费者的行为,它为消费组具备了高可用性和伸缩
性提供了保障,使得我们既方便又安全地删除消费组内的消费者或者往消费组内添加消费者。不过再均
衡发生期间,消费者是无法拉取消息的。
见代码库:com.heima.kafka.chapter3.CommitSyncInRebalance
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
consumer.subscribe(Arrays.asList(topic), new ConsumerRebalanceListener()
{
@Override
public void onPartitionsRevoked(Collection<TopicPartition>
partitions) {
// 劲量避免重复消费
consumer.commitSync(currentOffsets);
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition>
partitions) {
//do nothing.
}
});
try {
while (isRunning.get()) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.offset() + ":" + record.value());
// 异步提交消费位移,在发生再均衡动作之前可以通过再均衡监听器的
onPartitionsRevoked回调执行commitSync方法同步提交位移。
currentOffsets.put(new TopicPartition(record.topic(),
record.partition()),
new OffsetAndMetadata(record.offset() + 1));
}
consumer.commitAsync(currentOffsets, null);
}
} finally {
consumer.close();
}
}
3.2.5 消费者拦截器
之前章节讲了生产者拦截器,对应的消费者也有相应的拦截器概念,消费者拦截器主要是在消费到消息
或者在提交消费位移时进行的一些定制化的操作。
使用场景
消息设置一个有效期的属性,如果某条消息在既定的时间窗口内无法到达,那就视为无效,不需
要再被处理
见代码库:com.heima.kafka.chapter3.ConsumerInterceptorTTL
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String>
records) {
System.out.println("before:" + records);
long now = System.currentTimeMillis();
Map<TopicPartition, List<ConsumerRecord<String, String>>> newRecords
= new HashMap<>();
for (TopicPartition tp : records.partitions()) {
List<ConsumerRecord<String, String>> tpRecords =
records.records(tp);
List<ConsumerRecord<String, String>> newTpRecords = new ArrayList<>
();
for (ConsumerRecord<String, String> record : tpRecords) {
if (now - record.timestamp() < EXPIRE_INTERVAL) {
newTpRecords.add(record);
}
}
if (!newTpRecords.isEmpty()) {
newRecords.put(tp, newTpRecords);
}
}
return new ConsumerRecords<>(newRecords);
}
实现自定义拦截器之后,需要在KafkaConsumer中配置指定这个拦截器,如下
// 指定消费者拦截器
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,ConsumerInterceptorTTL.class
.getName());
效果演示
发送端同时发送两条消息,其中一条修改timestamp的值来使其变得超时,如下:
com.heima.kafka.chapter3.ProducerFastStart
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "Kafka-demo-
001", "hello, Kafka!");
ProducerRecord<String, String> record2 = new ProducerRecord<>(topic, 0,
System.currentTimeMillis() - 10 * 1000, "Kafka-demo-001", "hello, Kafka!->超时");
启动消费端运行如下,只收到了未超时的消息:

3.2.6 消费者参数补充
fetch.min.bytes
指定从broker读取消息时最小的数据量。当消费者从broker读取消息时,如果数据
量小于这个阈值,broker会等待直到有足够的数据,然后才返回给消费者。对于写入量不高的主题来
说,这个参数可以减少broker和消费者的压力,因为减少了往返的时间。而对于有大量消费者的主题来
说,则可以明显减轻broker压力。
fetch.max.wait.ms
上面的fetch.min.bytes参数指定了消费者读取的最小数据量,而这个参数则指定了消费者读取时最长等
待时间,从而避免长时间阻塞。这个参数默认为500ms。
max.partition.fetch.bytes
这个参数指定了每个分区返回的最多字节数,默认为1M。也就是说,KafkaConsumer.poll()返回记录
列表时,每个分区的记录字节数最多为1M。如果一个主题有20个分区,同时有5个消费者,那么每个消
费者需要4M的空间来处理消息。实际情况中,我们需要设置更多的空间,这样当存在消费者宕机时,
其他消费者可以承担更多的分区。
max.poll.records
这个参数控制一个poll()调用返回的记录数,这个可以用来控制应用在拉取循环中的处理数据量。
更多参数见官网: http://kafka.apache.org/documentation/#consumerconfifigs
总结
本章主要讲解了消费者和消费组的概念,以及如何正确的使用KafkaConsumer,其中重点讲解了参数
的配置,订阅、反序列化、位移提交、再均衡、拦截器等知识点。
第4章 主题
tips 学完这一章你可以
深入学习Kafka主题的管理
KafkaAdminClient应用
4.1 管理
4.1.1 创建主题
命令
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic heima --partitions 2 --replication
factor 1
localhost:2181 zookeeper所在的ip,zookeeper 必传参数,多个zookeeper用 ‘,’分开。
partitions 用于设置主题分区数,每个线程处理一个分区数据
replication-factor 用于设置主题副本数,每个副本分布在不通节点,不能超过总结点数。如你只有一个
节点,但是创建时指定副本数为2,就会报错。
查看topic元数据信细的方法
topic元数据信细保存在Zookeeper节点中
// 连接zk client
itcast@Server-node:/mnt/d/zookeeper-3.4.14$ bin/zkCli.sh -server localhost:2181
Connecting to localhost:2181
...........................................
[zk: localhost:2181(CONNECTED) 2] get /brokers/topics/heima
{"version":1,"partitions":{"1":[0],"0":[0]}}
cZxid = 0x618
ctime = Wed Aug 28 05:51:35 GMT 2019
mZxid = 0x618
mtime = Wed Aug 28 05:51:35 GMT 2019
pZxid = 0x619
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 44
numChildren = 1
[zk: localhost:2181(CONNECTED) 3]
4.1.2 查看主题
// 查看所有主题
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --list --
zookeeper localhost:2181
__consumer_offsets
__transaction_state
_schemas
heima
topic0701
topic0703
topic0703kafka_source
topic0828
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
// 查看某个特定主题信息,不指定topic则查询所有 通过 --describe
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --describe --
zookeeper localhost:2181 --topic heima
Topic:heima PartitionCount:2 ReplicationFactor:1 Configs:
Topic: heima Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: heima Partition: 1 Leader: 0 Replicas: 0 Isr: 0
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
//查看正在同步的主题
// 通过 --describe 和 under-replicated-partitions命令组合查看 under-replacation状态
4.1.3 修改主题
// 增加配置
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --alter --
zookeeper localhost:2181 --topic heima
--config flush.messages=1
WARNING: Altering topic configuration from this script has been deprecated and
may be removed in future releases.
Going forward, please use kafka-configs.sh for this functionality
// 删除配置
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --alter --
zookeeper localhost:2181 --topic heima --delete-config flush.messages
WARNING: Altering topic configuration from this script has been deprecated and
may be removed in future releases.
Going forward, please use kafka-configs.sh for this functionality
Updated config for topic heima.
4.1.4 删除主题
若 delete.topic.enable=true 直接彻底删除该 Topic。 若 delete.topic.enable=false 如果当前
Topic 没有使用过即没有传输过信息:可以彻底删除。 如果当前 Topic 有使用过即有过传输过信息:
并没有真正删除 Topic 只是把这个 Topic 标记为删除(marked for deletion),重启 Kafka Server 后删
除。
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --delete --
zookeeper localhost:2181 --topic heima
Topic heima is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
// 标记为 marked for deletion
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --list --
zookeeper localhost:2181
__consumer_offsets
topic0701
heima - marked for deletion
4.2 增加分区
// 增加分区数
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --alter --
zookeeper localhost:2181 --topic heima --partitions 3
WARNING: If partitions are increased for a topic that has a key, the partition
logic or ordering of the messages will be affected
Adding partitions succeeded!
//修改分区数时,仅能增加分区个数。若是用其减少 partition 个数,则会报如下错误信息:
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --alter --
zookeeper localhost:2181 --topic heima --partitions 2
WARNING: If partitions are increased for a topic that has a key, the partition
logic or ordering of the messages will be affected
Error while executing topic command : The number of partitions for a topic can
only be increased. Topic heima currently has 3 partitions, 2 would not be an
increase.
[2019-08-28 08:43:41,478] ERROR
org.apache.kafka.common.errors.InvalidPartitionsException: The number of
partitions for a topic can only be increased. Topic heima currently has 3
partitions, 2 would not be an increase.
(kafka.admin.TopicCommand$)
4.3 分区副本的分配--只做了解
见官方文档:http://kafka.apache.org/documentation/#topicconfifigs
Configurations pertinent to topics have both a server default as well an
optional per-topic override. If no per-topic configuration is given the server
default is used. The override can be set at topic creation time by giving one or
more --config options. This example creates a topic named my-topic with a custom
max message size and flush rate:
1
2
> bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-
topic --partitions 1
--replication-factor 1 --config max.message.bytes=64000 --config
flush.messages=1
Overrides can also be changed or set later using the alter configs command. This
example updates the max message size for my-topic:
1
2
> bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-
name my-topic
--alter --add-config max.message.bytes=128000
To check overrides set on the topic you can do
1
> bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-
name my-topic --describe
To remove an override you can do
1
2
> bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --
entity-name my-topic
--alter --delete-config max.message.bytes
The following are the topic-level configurations. The server's default
configuration for this property is given under the Server Default Property
heading. A given server default config value only applies to a topic if it does
not have an explicit topic config override.
4.5 KafkaAdminClient应用
我们都习惯使用Kafka中bin目录下的脚本工具来管理查看Kafka,但是有些时候需要将某些管理查看的
功能集成到系统(比如Kafka Manager)中,那么就需要调用一些API来直接操作Kafka了。
见代码库:com.heima.kafka.chapter4.KafkaAdminConfifigOperation
/**
* KafkaAdminClient应用
*/
public class KafkaAdminConfigOperation {
public static void main(String[] args) throws ExecutionException,
InterruptedException {
// describeTopicConfig();
// alterTopicConfig();
addTopicPartitions();
}
//Config(entries=[ConfigEntry(name=compression.type, value=producer,
source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=leader.replication.throttled.replicas, value=,
source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=message.downconversion.enable, value=true,
source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=min.insync.replicas, value=1, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=segment.jitter.ms, value=0, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=cleanup.policy, value=delete, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=flush.ms,
value=9223372036854775807, source=DEFAULT_CONFIG, isSensitive=false,
isReadOnly=false, synonyms=[]),
ConfigEntry(name=follower.replication.throttled.replicas, value=,
source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=segment.bytes, value=1073741824, source=STATIC_BROKER_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=retention.ms, value=604800000, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=flush.messages, value=9223372036854775807,
source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=message.format.version, value=2.0-IV1, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=file.delete.delay.ms, value=60000, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=max.message.bytes, value=1000012, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=min.compaction.lag.ms, value=0, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=message.timestamp.type, value=CreateTime,
source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=preallocate, value=false, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=min.cleanable.dirty.ratio, value=0.5, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=index.interval.bytes, value=4096, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=unclean.leader.election.enable, value=false,
source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=retention.bytes, value=-1, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=delete.retention.ms, value=86400000, source=DEFAULT_CONFIG,
isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.ms,
value=604800000, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false,
synonyms=[]), ConfigEntry(name=message.timestamp.difference.max.ms,
value=9223372036854775807, source=DEFAULT_CONFIG, isSensitive=false,
isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.index.bytes,
value=10485760, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false,
synonyms=[])])
public static void describeTopicConfig() throws ExecutionException,
InterruptedException {
String brokerList = "localhost:9092";
String topic = "heima";
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000);
AdminClient client = AdminClient.create(props);
ConfigResource resource =
new ConfigResource(ConfigResource.Type.TOPIC, topic);
DescribeConfigsResult result =
client.describeConfigs(Collections.singleton(resource));
Config config = result.all().get().get(resource);
System.out.println(config);
client.close();
}
public static void alterTopicConfig() throws ExecutionException,
InterruptedException {
String brokerList = "localhost:9092";
String topic = "heima";
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000);
AdminClient client = AdminClient.create(props);
ConfigResource resource =
new ConfigResource(ConfigResource.Type.TOPIC, topic);
ConfigEntry entry = new ConfigEntry("cleanup.policy", "compact");
Config config = new Config(Collections.singleton(entry));
Map<ConfigResource, Config> configs = new HashMap<>();
configs.put(resource, config);
AlterConfigsResult result = client.alterConfigs(configs);
result.all().get();
client.close();
}
public static void addTopicPartitions() throws ExecutionException,
InterruptedException {
String brokerList = "localhost:9092";
String topic = "heima";
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000);
AdminClient client = AdminClient.create(props);
NewPartitions newPartitions = NewPartitions.increaseTo(5);
Map<String, NewPartitions> newPartitionsMap = new HashMap<>();
newPartitionsMap.put(topic, newPartitions);
CreatePartitionsResult result =
client.createPartitions(newPartitionsMap);
result.all().get();
client.close();
}
}
本章主要讲解了Kafka两大核心之一:主题,通过对主题的增删该查、配置等内容来了解主题的相关内
容。
第5章 分区
tips 学完这一章你可以***
深入学习Kafka分区的管理
包括:优先副本的选举、分区重新分配等
Kafka可以将主题划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要
如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡
和水平扩展。另外,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力。
顺便说一句,由于消息是以追加到分区中的,多个分区顺序写磁盘的总效率要比随机写内存还要高(引
用Apache Kafka – A High Throughput Distributed Messaging System的观点),是Kafka高吞吐率的
重要保证之一。
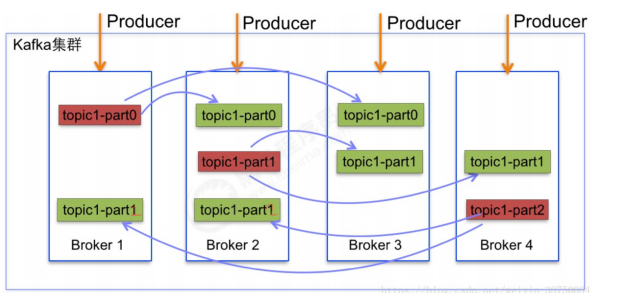
5.1 副本机制
由于Producer和Consumer都只会与Leader角色的分区副本相连,所以kafka需要以集群的组织形式提
供主题下的消息高可用。kafka支持主备复制,所以消息具备高可用和持久性。
一个分区可以有多个副本,这些副本保存在不同的broker上。每个分区的副本中都会有一个作为
Leader。当一个broker失败时,Leader在这台broker上的分区都会变得不可用,kafka会自动移除
Leader,再其他副本中选一个作为新的Leader。
在通常情况下,增加分区可以提供kafka集群的吞吐量。然而,也应该意识到集群的总分区数或是单台
服务器上的分区数过多,会增加不可用及延迟的风险。
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --describe --
zookeeper localhost:2181 --topic heima
// hema这个主题有三个分区,一个副本同处在一个节点当中
Topic:heima PartitionCount:3 ReplicationFactor:1 Configs:
Topic: heima Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: heima Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: heima Partition: 2 Leader: 0 Replicas: 0 Isr: 0
5.2 分区Leader选举
可以预见的是,如果某个分区的Leader挂了,那么其它跟随者将会进行选举产生一个新的leader,之后所有
的读写就会转移到这个新的Leader上,在kafka中,其不是采用常见的多数选举的方式进行副本的Leader
选举,而是会在Zookeeper上针对每个Topic维护一个称为ISR(in-sync replica,已同步的副本)的集合,
显然还有一些副本没有来得及同步。只有这个ISR列表里面的才有资格成为leader(先使用ISR里面的第一
个,如果不行依次类推,因为ISR里面的是同步副本,消息是最完整且各个节点都是一样的)。 通过
ISR,kafka需要的冗余度较低,可以容忍的失败数比较高。假设某个topic有f+1个副本,kafka可以容忍f
个不可用,当然,如果全部ISR里面的副本都不可用,也可以选择其他可用的副本,只是存在数据的不一致。
5.3 分区重新分配
我们往已经部署好的Kafka集群里面添加机器是最正常不过的需求,而且添加起来非常地方便,我们需
要做的事是从已经部署好的Kafka节点中复制相应的配置文件,然后把里面的broker id修改成全局唯一
的,最后启动这个节点即可将它加入到现有Kafka集群中。
但是问题来了,新添加的Kafka节点并不会自动地分配数据,所以无法分担集群的负载,除非我们新建
一个topic。但是现在我们想手动将部分分区移到新添加的Kafka节点上,Kafka内部提供了相关的工具
来重新分布某个topic的分区。
具体步骤:
第一步:我们创建一个有三个节点的集群,详情可查看第九章集群的搭建。
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --create --
zookeeper localhost:2181 --topic heima-par --partitions 3 --replication-factor 3
Created topic heima-par.
详情查看
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --describe
--zookeeper localhost:2181 --topic heima
-par
Topic:heima-par PartitionCount:3 ReplicationFactor:3 Configs:
Topic: heima-par Partition: 0 Leader: 2 Replicas: 2,1,0 Isr:
2,1,0
Topic: heima-par Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0
Topic: heima-par Partition: 2 Leader: 1 Replicas: 1,0,2 Isr:
1,0,2
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$
从上面的输出可以看出heima-par这个主题一共有三个分区,有三个副本
第二步:主题heima-par再添加一个分区
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --alter --
zookeeper localhost:2181 --topic heima-pa
r --partitions 4
WARNING: If partitions are increased for a topic that has a key, the partition
logic or ordering of the messages will be affected
Adding partitions succeeded!
查看详情已经变成4个分区
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --describe
--zookeeper localhost:2181 --topic heima
-par
Topic:heima-par PartitionCount:4 ReplicationFactor:3 Configs:
Topic: heima-par Partition: 0 Leader: 2 Replicas: 2,1,0 Isr:
2,1,0
Topic: heima-par Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0
Topic: heima-par Partition: 2 Leader: 1 Replicas: 1,0,2 Isr:
1,0,2
Topic: heima-par Partition: 3 Leader: 2 Replicas: 2,1,0 Isr:
2,1,0
这样会导致broker2维护更多的分区
第三步:再添加一个broker节点
查看主题信息
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --describe
-zookeeper localhost:2181 --topic heima-par
Topic:heima-par PartitionCount:4 ReplicationFactor:3 Configs:
Topic: heima-par Partition: 0 Leader: 2 Replicas: 2,1,0 Isr:
2,1,0
Topic: heima-par Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0
Topic: heima-par Partition: 2 Leader: 1 Replicas: 1,0,2 Isr:
1,0,2
Topic: heima-par Partition: 3 Leader: 2 Replicas: 2,1,0 Isr:
2,1,0
从上面输出信息可以看出新添加的节点并没有分配之前主题的分区
第四步:重新分配
现在我们需要将原先分布在broker 1-3节点上的分区重新分布到broker 1-4节点上,借助kafka
reassign-partitions.sh工具生成reassign plan,不过我们先得按照要求定义一个文件,里面说明哪些
topic需要重新分区,文件内容如下:
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ cat reassign.json
{"topics":[{"topic":"heima-par"}],
"version":1
}
然后使用 kafka-reassign-partitions.sh 工具生成reassign plan
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to -move-json-fifile
reassign.json --broker-list "0,1,2,3" --generate
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-reassign-
partitions.sh --zookeeper localhost:2181 --topics-to
-move-json-file reassign.json --broker-list "0,1,2,3" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"heima-par","partition":2,"replicas":
[1,0,2],"log_dirs":["any","any","any"]},{"topic":"heima-
par","partition":1,"replicas":[0,2,1],"log_dirs":["any","any","any"]},
{"topic":"heima-par","partition":0,"replicas":[2,1,0],"log_dirs":
["any","any","any"]},{"topic":"heima-par","partition":3,"replicas":
[2,1,0],"log_dirs":["any","any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"heima-par","partition":0,"replicas":
[1,2,3],"log_dirs":["any","any","any"]},{"topic":"heima-
par","partition":2,"replicas":[3,0,1],"log_dirs":["any","any","any"]},
{"topic":"heima-par","partition":1,"replicas":[2,3,0],"log_dirs":
["any","any","any"]},{"topic":"heima-par","partition":3,"replicas":
[0,1,2],"log_dirs":["any","any","any"]}]}
上面命令中
--generate 表示指定类型参数
--topics-to-move-json-fifile 指定分区重分配对应的主题清单路径
注意:
命令输入两个Json字符串,第一个JSON内容为当前的分区副本分配情况,第二个为重新分配的候
选方案,注意这里只是生成一份可行性的方案,并没有真正执行重分配的动作。
我们将第二个JSON内容保存到名为result.json文件里面(文件名不重要,文件格式也不一定要以json为
结尾,只要保证内容是json即可),然后执行这些reassign plan:
重新分配JSON文件
{
"version": 1,
"partitions": [
{
"topic": "heima-par",
"partition": 0,
"replicas": [
1,
2,
3
],
"log_dirs": [
"any",
"any",
"any"
]
},
{
"topic": "heima-par",
"partition": 2,
"replicas": [
3,
0,
1
],
"log_dirs": [
"any",
"any",
"any"
]
},
{
"topic": "heima-par",
"partition": 1,
"replicas": [
2,
3,
0
],
"log_dirs": [
"any",
"any",
"any"
]
},
{
"topic": "heima-par",
"partition": 3,
"replicas": [
0,
1,
2
],
"log_dirs": [
"any",
"any",
"any"
]
}
]
}
执行分配策略
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-reassign-
partitions.sh --zookeeper localhost:2181 --reassignm
ent-json-file result.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"heima-par","partition":2,"replicas":
[1,0,2],"log_dirs":["any","any","any"]},{"topic":"heima-
par","partition":1,"replicas":[0,2,1],"log_dirs":["any","any","any"]},
{"topic":"heima-par","partition":0,"replicas":[2,1,0],"log_dirs":
["any","any","any"]},{"topic":"heima-par","partition":3,"replicas":
[2,1,0],"log_dirs":["any","any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
查看分区重新分配的进度:
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-reassign-
partitions.sh --zookeeper localhost:2181 --reassignment-json-file result.json --
verify
Status of partition reassignment:
Reassignment of partition heima-par-3 completed successfully
Reassignment of partition heima-par-0 is still in progress
Reassignment of partition heima-par-2 is still in progress
Reassignment of partition heima-par-1 is still in progress
从上面信息可以看出 heima-par-3已经完成,其他三个正在进行中。
5.4 修改副本因子
场景
实际项目中我们可能在创建topic时没有设置好正确的replication-factor,导致kafka集群虽然是高可用
的,但是该topic在有broker宕机时,可能发生无法使用的情况。topic一旦使用又不能轻易删除重建,
因此动态增加副本因子就成为最终的选择。
说明:kafka 1.0版本配置文件默认没有default.replication.factor=x, 因此如果创建topic时,不指定–
replication-factor 想, 默认副本因子为1. 我们可以在自己的server.properties中配置上常用的副本因
子,省去手动调整。例如设置default.replication.factor=3
首先我们配置topic的副本,保存为json文件
{
"version":1,
"partitions":[
{"topic":"heima","partition":0,"replicas":[0,1,2]},
{"topic":"heima","partition":1,"replicas":[0,1,2]},
{"topic":"heima","partition":2,"replicas":[0,1,2]}
]
}
然后执行脚本 bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-fifile
replication-factor.json --execute
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-reassign-partitions.sh --
zookeeper localhost:2181 --reassignment-json-file replication-factor.json --
execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topic0703","partition":1,"replicas":
[1,0],"log_dirs":["any","any"]},{"topic":"topic0703","partition":0,"replicas":
[0,1],"log_dirs":["any","any"]},{"topic":"topic0703","partition":2,"replicas":
[2,0],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
验证:
server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --describe --
zookeeper localhost:2181 --topic topic0703
Topic:topic0703 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: topic0703 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0
Topic: topic0703 Partition: 1 Leader: 1 Replicas: 0,1,2 Isr: 1,0
Topic: topic0703 Partition: 2 Leader: 2 Replicas: 0,1,2 Isr: 2,0
5.5 分区分配策略
按照Kafka默认的消费逻辑设定,一个分区只能被同一个消费组(ConsumerGroup)内的一个消费者
消费。假设目前某消费组内只有一个消费者C0,订阅了一个topic,这个topic包含7个分区,也就是说
这个消费者C0订阅了7个分区,参考下图

此时消费组内又加入了一个新的消费者C1,按照既定的逻辑需要将原来消费者C0的部分分区分配给消
费者C1消费,情形上图(2),消费者C0和C1各自负责消费所分配到的分区,相互之间并无实质性的干
扰。
接着消费组内又加入了一个新的消费者C2,如此消费者C0、C1和C2按照上图(3)中的方式各自负责
消费所分配到的分区。
如果消费者过多,出现了消费者的数量大于分区的数量的情况,就会有消费者分配不到任何分区。参考
下图,一共有8个消费者,7个分区,那么最后的消费者C7由于分配不到任何分区进而就无法消费任何
消息。
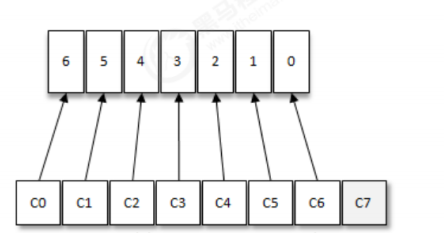
面各个示例中的整套逻辑是按照Kafka中默认的分区分配策略来实施的。Kafka提供了消费者客户端参
数partition.assignment.strategy用来设置消费者与订阅主题之间的分区分配策略。默认情况下,此参
数的值为:org.apache.kafka.clients.consumer.RangeAssignor,即采用RangeAssignor分配策略。除
此之外,Kafka中还提供了另外两种分配策略: RoundRobinAssignor和StickyAssignor。消费者客户端
参数partition.asssignment.strategy可以配置多个分配策略,彼此之间以逗号分隔。
RangeAssignor分配策略
参考源码:org.apache.kafka.clients.consumer.RangeAssignor
RangeAssignor策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按
照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每一个topic,
RangeAssignor策略会将消费组内所有订阅这个topic的消费者按照名称的字典序排序,然后为每个消费
者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
假设n=分区数/消费者数量,m=分区数%消费者数量,那么前m个消费者每个分配n+1个分区,后面的
(消费者数量-m)个消费者每个分配n个分区。
假设消费组内有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有4个分区,那么所订阅的
所有分区可以标识为:t0p0、t0p1、t0p2、t0p3、t1p0、t1p1、t1p2、t1p3。最终的分配结果为:
消费者C0:t0p0、t0p1、t1p0、t1p1
消费者C1:t0p2、t0p3、t1p2、t1p3
假设上面例子中2个主题都只有3个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、
t1p0、t1p1、t1p2。最终的分配结果为:
消费者C0:t0p0、t0p1、t1p0、t1p1
消费者C1:t0p2、t1p2
可以明显的看到这样的分配并不均匀,如果将类似的情形扩大,有可能会出现部分消费者过载的情况。
RoundRobinAssignor分配策略
参考源码:org.apache.kafka.clients.consumer.RoundRobinAssignor
RoundRobinAssignor策略的原理是将消费组内所有消费者以及消费者所订阅的所有topic的partition按
照字典序排序,然后通过轮询方式逐个将分区以此分配给每个消费者。RoundRobinAssignor策略对应
的partition.assignment.strategy参数值为:
org.apache.kafka.clients.consumer.RoundRobinAssignor。
假设消费组中有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有3个分区,那么所订阅的
所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
消费者C0:t0p0、t0p2、t1p1
消费者C1:t0p1、t1p0、t1p2
如果同一个消费组内的消费者所订阅的信息是不相同的,那么在执行分区分配的时候就不是完全的轮询
分配,有可能会导致分区分配的不均匀。如果某个消费者没有订阅消费组内的某个topic,那么在分配分
区的时候此消费者将分配不到这个topic的任何分区。
假设消费组内有3个消费者C0、C1和C2,它们共订阅了3个主题:t0、t1、t2,这3个主题分别有1、2、
3个分区,即整个消费组订阅了t0p0、t1p0、t1p1、t2p0、t2p1、t2p2这6个分区。具体而言,消费者
C0订阅的是主题t0,消费者C1订阅的是主题t0和t1,消费者C2订阅的是主题t0、t1和t2,那么最终的分
配结果为:
消费者C0:t0p0
消费者C1:t1p0
消费者C2:t1p1、t2p0、t2p1、t2p2
可以看到RoundRobinAssignor策略也不是十分完美,这样分配其实并不是最优解,因为完全可以将分
区t1p1分配给消费者C1。
StickyAssignor分配策略
参考源码:org.apache.kafka.clients.consumer.StickyAssignor
Kafka从0.11.x版本开始引入这种分配策略,它主要有两个目的:
分区的分配要尽可能的均匀; 分区的分配尽可能的与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标。鉴于这两个目标,StickyAssignor策略的具体实现
要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多。
假设消费组内有3个消费者:C0、C1和C2,它们都订阅了4个主题:t0、t1、t2、t3,并且每个主题有2
个分区,也就是说整个消费组订阅了t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1这8个分
区。最终的分配结果如下:
消费者C0:t0p0、t1p1、t3p0
消费者C1:t0p1、t2p0、t3p1
消费者C2:t1p0、t2p1
假设此时消费者C1脱离了消费组,那么消费组就会执行再平衡操作,进而消费分区会重新分配。如果采
用RoundRobinAssignor策略,那么此时的分配结果如下:
消费者C0:t0p0、t1p0、t2p0、t3p0
消费者C2:t0p1、t1p1、t2p1、t3p1
如分配结果所示,RoundRobinAssignor策略会按照消费者C0和C2进行重新轮询分配。而如果此时使用
的是StickyAssignor策略,那么分配结果为:
消费者C0:t0p0、t1p1、t3p0、t2p0
消费者C2:t1p0、t2p1、t0p1、t3p1
可以看到分配结果中保留了上一次分配中对于消费者C0和C2的所有分配结果,并将原来消费者C1的“负
担”分配给了剩余的两个消费者C0和C2,最终C0和C2的分配还保持了均衡。
自定义分配策略
需实现:org.apache.kafka.clients.consumer.internals.PartitionAssignor
继承自:org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor
总结
本章讲解了对分区及副本的一系列操作,如分区副本机制、分区重新分配、修改副本因子等。
第6张 Kafka存储
tips 学完这一章你可以***
在完成Kafka应用开发的基础上,知道文件存储机制
Kafka为什么使用磁盘作为存储介质
分析文件存储格式
快速检索消息
6.1 存储结构概述
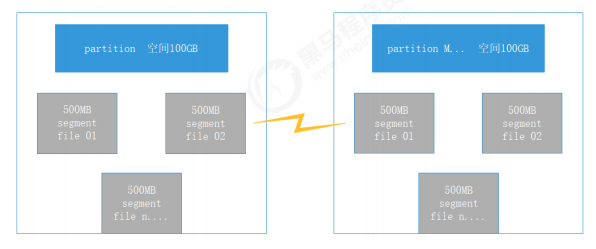
每一个partion(文件夹)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件里。
但每一个段segment fifile消息数量不一定相等,这样的特性方便old segment fifile高速被删除。
(默认情况下每一个文件大小为1G)
每一个partiton仅仅须要支持顺序读写即可了。segment文件生命周期由服务端配置參数决定。
partiton中segment文件存储结构
segment fifile组成:由2大部分组成。分别为index fifile和data fifile,此2个文件一一相应,成对出现,后
缀”.index”和“.log”分别表示为segment索引文件、数据文件.
segment文件命名规则:partion全局的第一个segment从0开始,兴许每一个segment文件名称为上一
个segment文件最后一条消息的offffset值。
数值最大为64位long大小。19位数字字符长度,没有数字用0填充。
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ ll /tmp/kafka/log/heima-0/
total 20480
drwxr-xr-x 1 itcast sudo 512 Aug 29 09:38 ./
drwxrwxrwx 1 dayuan dayuan 512 Aug 29 09:41 ../
-rw-r--r-- 1 itcast sudo 10485760 Aug 29 09:38 00000000000000000000.index
-rw-r--r-- 1 itcast sudo 0 Aug 29 09:38 00000000000000000000.log
-rw-r--r-- 1 itcast sudo 10485756 Aug 29 09:38 00000000000000000000.timeindex
-rw-r--r-- 1 itcast sudo 8 Aug 29 09:38 leader-epoch-checkpoint
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
6.2 日志索引
6.2.1 数据文件的分段
kafka解决查询效率的手段之一是将数据文件分段,比如有100条Message,它们的offffset是从0到99。
假设将数据文件分成5段,第一段为0-19,第二段为20-39,以此类推,每段放在一个单独的数据文件里
面,数据文件以该段中最小的offffset命名。这样在查找指定offffset的Message的时候,用二分查找就可
以定位到该Message在哪个段中。
6.2.2 偏移量索引
数据文件分段使得可以在一个较小的数据文件中查找对应offffset的Message了,但是这依然需要顺序扫
描才能找到对应offffset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立
了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。

比如:要查找绝对offffset为7的Message:
首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。 打开这个Segment的
index文件,也是用二分查找找到offffset小于或者等于指定offffset的索引条目中最大的那个offffset。自然
offffset为6的那个索引是我们要找的,通过索引文件我们知道offffset为6的Message在数据文件中的位置
为9807。
打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offffset为7的那条Message。
这套机制是建立在offffset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
一句话,Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达
到了高效性。
6.3 日志清理
6.3.1 日志删除
Kafka日志管理器允许定制删除策略。目前的策略是删除修改时间在N天之前的日志(按时间删除),
也可以使用另外一个策略:保留最后的N GB数据的策略(按大小删除)。为了避免在删除时阻塞读操作,
采用了copy-on-write形式的实现,删除操作进行时,读取操作的二分查找功能实际是在一个静态的快
照副本上进行的,这类似于Java的CopyOnWriteArrayList。 Kafka消费日志删除思想:Kafka把topic中
一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,
减少磁盘占用
log.cleanup.policy=delete 启用删除策略
直接删除,删除后的消息不可恢复。可配置以下两个策略:
清理超过指定时间清理:
log.retention.hours=16
超过指定大小后,删除旧的消息:
log.retention.bytes=1073741824
6.3.2 日志压缩
将数据压缩,只保留每个key最后一个版本的数据。首先在broker的配置中设置
log.cleaner.enable=true启用cleaner,这个默认是关闭的。在Topic的配置中设置
log.cleanup.policy=compact启用压缩策略。
.







压缩后的offffset可能是不连续的,比如上图中没有5和7,因为这些offffset的消息被merge了,当从这些
offffset消费消息时,将会拿到比这个offffset大的offffset对应的消息,比如,当试图获取offffset为5的消息
时,实际上会拿到offffset为6的消息,并从这个位置开始消费。
这种策略只适合特俗场景,比如消息的key是用户ID,消息体是用户的资料,通过这种压缩策略,整个
消息集里就保存了所有用户最新的资料。
压缩策略支持删除,当某个Key的最新版本的消息没有内容时,这个Key将被删除,这也符合以上逻
辑。
6.4 磁盘存储优势
Kafka在设计的时候,采用了文件追加的方式来写入消息,即只能在日志文件的尾部追加新的消息,并
且不允许修改已经写入的消息,这种方式属于典型的顺序写入此判断的操作,所以就算是Kafka使用磁
盘作为存储介质,所能实现的额吞吐量也非常可观。
Kafka中大量使用页缓存,这页是Kafka实现高吞吐的重要因素之一。
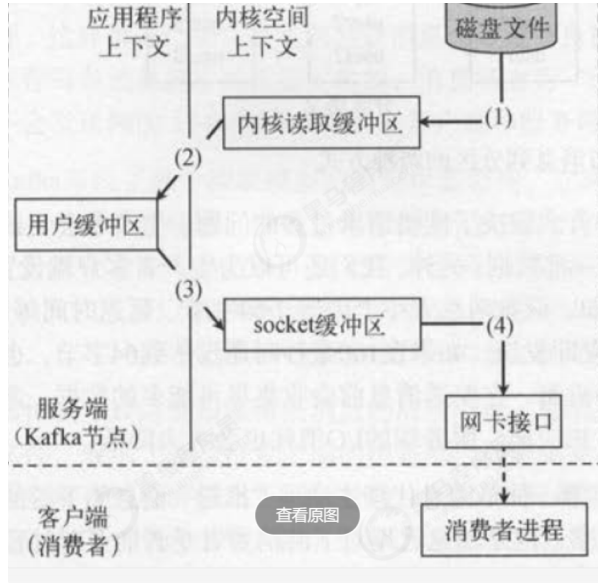
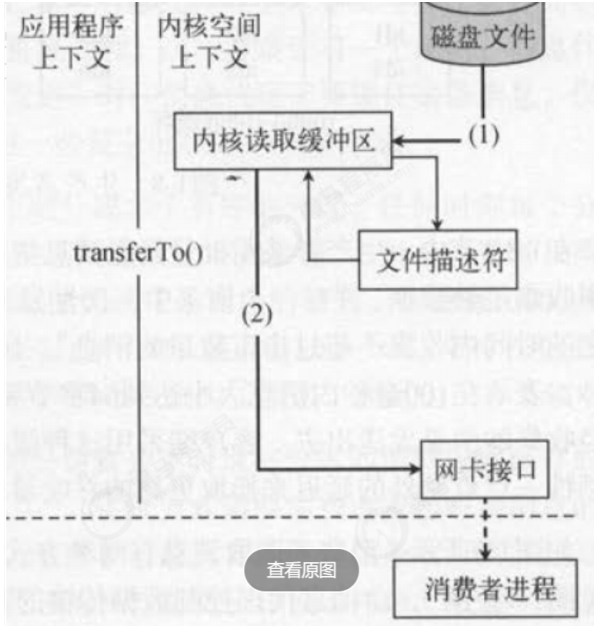
除了消息顺序追加,页缓存等技术,Kafka还使用了零拷贝技术来进一步提升性能。“零拷贝技术”只用将
磁盘文件的数据复制到页面缓存中一次,然后将数据从页面缓存直接发送到网络中(发送给不同的订阅
者时,都可以使用同一个页面缓存),避免了重复复制操作。如果有10个消费者,传统方式下,数据复
制次数为4*10=40次,而使用“零拷贝技术”只需要1+10=11次,一次为从磁盘复制到页面缓存,10次表
示10个消费者各自读取一次页面缓存。
总结
本章主要讲述了Kafka中与存储相关的知识点,包含了Kafka自身的日志格式、日志索引、日志清理等方
面的内容,也涉及到底层物理存储相关的知识。通过本章的学习,可以Kafka核心机理有较深入的认
知。
第7章 稳定性
*tips 学完这一章你可以
深入学习Kafka在保证高性能、高吞吐的同时通过各种机制来保证高可用性
Kafka的消息传输保障机制非常直观。当producer向broker发送消息时,一旦这条消息被commit,由
于副本机制(replication)的存在,它就不会丢失。但是如果producer发送数据给broker后,遇到的网
络问题而造成通信中断,那producer就无法判断该条消息是否已经提交(commit)。虽然Kafka无法
确定网络故障期间发生了什么,但是producer可以retry多次,确保消息已经正确传输到broker中,所
以目前Kafka实现的是at least once。
7.1 幂等性
场景
所谓幂等性,就是对接口的多次调用所产生的结果和调用一次是一致的。生产者在进行重试的时候有可
能会重复写入消息,二使用Kafka的幂等性功能就可以避免这种情况。
幂等性是有条件的:
只能保证 Producer 在单个会话内不丟不重,如果 Producer 出现意外挂掉再重启是无法保证的
(幂等性情况下,是无法获取之前的状态信息,因此是无法做到跨会话级别的不丢不重);
幂等性不能跨多个 Topic-Partition,只能保证单个 partition 内的幂等性,当涉及多个 Topic
Partition 时,这中间的状态并没有同步。
Producer 使用幂等性的示例非常简单,与正常情况下 Producer 使用相比变化不大,只需要把
Producer 的配置 enable.idempotence 设置为 true 即可,如下所示:
Properties props = new Properties();
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
props.put("acks", "all"); // 当 enable.idempotence 为 true,这里默认为 all
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
producer.send(new ProducerRecord(topic, "test");
7.2 事务
场景
幂等性并不能跨多个分区运作,而事务可以弥补这个缺憾,事务可以保证对多个分区写入操作的原子
性。操作的原子性是指多个操作要么全部成功,要么全部失败,不存在部分成功部分失败的可能。
为了实现事务,应用程序必须提供唯一的transactionalId,这个参数通过客户端程序来进行设定。
见代码库:com.heima.kafka.chapter7.ProducerTransactionSend
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionId);
前期准备
事务要求生产者开启幂等性特性,因此通过将transactional.id参数设置为非空从而开启事务特性的同时
需要将ProducerConfifig.ENABLE_IDEMPOTENCE_CONFIG设置为true(默认值为true),如果显示设
置为false,则会抛出异常。
KafkaProducer提供了5个与事务相关的方法,详细如下:
初始化事务,前提是配置了transactionalId
public void initTransactions()
//开启事务
public void beginTransaction()
//为消费者提供事务内的位移提交操作
public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata>
offsets, String consumerGroupId)
//提交事务
public void commitTransaction()
//终止事务,类似于回滚
public void abortTransaction()
案例解析
见代码库:com.heima.kafka.chapter7.ProducerTransactionSend
消息发送端
/**
* Kafka Producer事务的使用
*/
public class ProducerTransactionSend {
public static final String topic = "topic-transaction";
public static final String brokerList = "localhost:9092";
public static final String transactionId = "transactionId";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionId);
KafkaProducer<String, String> producer = new KafkaProducer<>
(properties);
producer.initTransactions();
producer.beginTransaction();
try {
//处理业务逻辑并创建ProducerRecord
ProducerRecord<String, String> record1 = new ProducerRecord<>(topic,
"msg1");
producer.send(record1);
ProducerRecord<String, String> record2 = new ProducerRecord<>(topic,
"msg2");
producer.send(record2);
ProducerRecord<String, String> record3 = new ProducerRecord<>(topic,
"msg3");
producer.send(record3);
//处理一些其它逻辑
producer.commitTransaction();
} catch (ProducerFencedException e) {
producer.abortTransaction();
}
producer.close();
}
}
模拟事务回滚案例
try {
//处理业务逻辑并创建ProducerRecord
ProducerRecord<String, String> record1 = new ProducerRecord<>(topic,
"msg1");
producer.send(record1);
//模拟事务回滚案例
System.out.println(1/0);
ProducerRecord<String, String> record2 = new ProducerRecord<>(topic,
"msg2");
producer.send(record2);
ProducerRecord<String, String> record3 = new ProducerRecord<>(topic,
"msg3");
producer.send(record3);
//处理一些其它逻辑
producer.commitTransaction();
} catch (ProducerFencedException e) {
producer.abortTransaction();
}
从上面案例中,msg1发送成功之后,出现了异常事务进行了回滚,则msg1消费端也收不到消息。
7.3 控制器
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),
它负责管理整个集群中所有分区和副本的状态。当某个分区的leader副本出现故障时,由控制器负责为
该分区选举新的leader副本。当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker
更新其元数据信息。当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责分
区的重新分配。
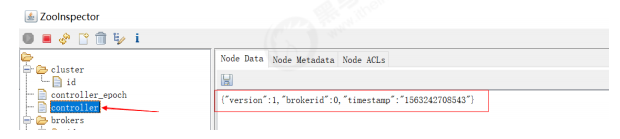
Kafka中的控制器选举的工作依赖于Zookeeper,成功竞选为控制器的broker会在Zookeeper中创
建/controller这个临时(EPHEMERAL)节点,此临时节点的内容参考如下:
ZooInspector管理
使用zookeeper图形化的客户端工具(ZooInspector)提供的jar来进行管理,启动如下:
1、定位到jar所在目录
2、运行jar文件 java -jar zookeeper-dev-ZooInspector.jar
3、连接Zookeeper
{"version":1,"brokerid":0,"timestamp":"1529210278988"}
其中version在目前版本中固定为1,brokerid表示称为控制器的broker的id编号,timestamp表示竞选
称为控制器时的时间戳。
在任意时刻,集群中有且仅有一个控制器。每个broker启动的时候会去尝试去读取/controller节点的
brokerid的值,如果读取到brokerid的值不为-1,则表示已经有其它broker节点成功竞选为控制器,所
以当前broker就会放弃竞选;如果Zookeeper中不存在/controller这个节点,或者这个节点中的数据异
常,那么就会尝试去创建/controller这个节点,当前broker去创建节点的时候,也有可能其他broker同
时去尝试创建这个节点,只有创建成功的那个broker才会成为控制器,而创建失败的broker则表示竞选
失败。每个broker都会在内存中保存当前控制器的brokerid值,这个值可以标识为activeControllerId。
Zookeeper中还有一个与控制器有关的/controller_epoch节点,这个节点是持久(PERSISTENT)节
点,节点中存放的是一个整型的controller_epoch值。controller_epoch用于记录控制器发生变更的次
数,即记录当前的控制器是第几代控制器,我们也可以称之为“控制器的纪元”。
controller_epoch的初始值为1,即集群中第一个控制器的纪元为1,当控制器发生变更时,没选出一个
新的控制器就将该字段值加1。每个和控制器交互的请求都会携带上controller_epoch这个字段,如果
请求的controller_epoch值小于内存中的controller_epoch值,则认为这个请求是向已经过期的控制器
所发送的请求,那么这个请求会被认定为无效的请求。如果请求的controller_epoch值大于内存中的
controller_epoch值,那么则说明已经有新的控制器当选了。由此可见,Kafka通过controller_epoch来
保证控制器的唯一性,进而保证相关操作的一致性。
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
1、监听partition相关的变化。
2、监听topic相关的变化。
3、监听broker相关的变化
7.4 可靠性保证
1. 可靠性保证:确保系统在各种不同的环境下能够发生一致的行为
2. Kafka的保证
保证分区消息的顺序
如果使用同一个生产者往同一个分区写入消息,而且消息B在消息A之后写入
那么Kafka可以保证消息B的偏移量比消息A的偏移量大,而且消费者会先读取消息A再
读取消息B
只有当消息被写入分区的所有同步副本时(文件系统缓存),它才被认为是已提交
生产者可以选择接收不同类型的确认,控制参数 acks
只要还有一个副本是活跃的,那么已提交的消息就不会丢失
消费者只能读取已经提交的消息
失效副本
怎么样判定一个分区是否有副本是处于同步失效状态的呢?从Kafka 0.9.x版本开始通过唯一的一个参数
replica.lag.time.max.ms(默认大小为10,000)来控制,当ISR中的一个follower副本滞后leader副本
的时间超过参数replica.lag.time.max.ms指定的值时即判定为副本失效,需要将此follower副本剔出除
ISR之外。具体实现原理很简单,当follower副本将leader副本的LEO(Log End Offffset,每个分区最后
一条消息的位置)之前的日志全部同步时,则认为该follower副本已经追赶上leader副本,此时更新该
副本的lastCaughtUpTimeMs标识。Kafka的副本管理器(ReplicaManager)启动时会启动一个副本过
期检测的定时任务,而这个定时任务会定时检查当前时间与副本的lastCaughtUpTimeMs差值是否大于
参数replica.lag.time.max.ms指定的值。千万不要错误的认为follower副本只要拉取leader副本的数据
就会更新lastCaughtUpTimeMs,试想当leader副本的消息流入速度大于follower副本的拉取速度时,
follower副本一直不断的拉取leader副本的消息也不能与leader副本同步,如果还将此follower副本置
于ISR中,那么当leader副本失效,而选取此follower副本为新的leader副本,那么就会有严重的消息丢
失。
副本复制
Kafka 中的每个主题分区都被复制了 n 次,其中的 n 是主题的复制因子(replication factor)。这允许
Kafka 在集群服务器发生故障时自动切换到这些副本,以便在出现故障时消息仍然可用。Kafka 的复制
是以分区为粒度的,分区的预写日志被复制到 n 个服务器。 在 n 个副本中,一个副本作为 leader,其
他副本成为 followers。顾名思义,producer 只能往 leader 分区上写数据(读也只能从 leader 分区上
进行),followers 只按顺序从 leader 上复制日志。
一个副本可以不同步Leader有如下几个原因 慢副本:在一定周期时间内follower不能追赶上leader。最
常见的原因之一是I / O瓶颈导致follower追加复制消息速度慢于从leader拉取速度。 卡住副本:在一定
周期时间内follower停止从leader拉取请求。follower replica卡住了是由于GC暂停或follower失效或死
亡。
新启动副本:当用户给主题增加副本因子时,新的follower不在同步副本列表中,直到他们完全赶上了
leader日志。
如何确定副本是滞后的
replica.lag.max.messages=4
在服务端现在只有一个参数需要配置replica.lag.time.max.ms。这个参数解释replicas响应partition
leader的最长等待时间。检测卡住或失败副本的探测——如果一个replica失败导致发送拉取请求时间间
隔超过replica.lag.time.max.ms。Kafka会认为此replica已经死亡会从同步副本列表从移除。检测慢副
本机制发生了变化——如果一个replica开始落后leader超过replica.lag.time.max.ms。Kafka会认为太
缓慢并且会从同步副本列表中移除。除非replica请求leader时间间隔大于replica.lag.time.max.ms,因
此即使leader使流量激增和大批量写消息。Kafka也不会从同步副本列表从移除该副本。
7.5 一致性保证
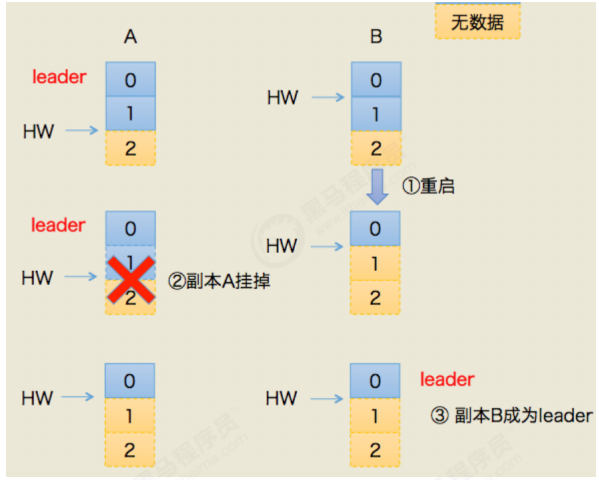
在leader宕机后,只能从ISR列表中选取新的leader,无论ISR中哪个副本被选为新的leader,它都
知道HW之前的数据,可以保证在切换了leader后,消费者可以继续看到HW之前已经提交的数
据。
HW的截断机制:选出了新的leader,而新的leader并不能保证已经完全同步了之前leader的所有
数据,只能保证HW之前的数据是同步过的,此时所有的follower都要将数据截断到HW的位置,
再和新的leader同步数据,来保证数据一致。 当宕机的leader恢复,发现新的leader中的数据和
自己持有的数据不一致,此时宕机的leader会将自己的数据截断到宕机之前的hw位置,然后同步
新leader的数据。宕机的leader活过来也像follower一样同步数据,来保证数据的一致性。
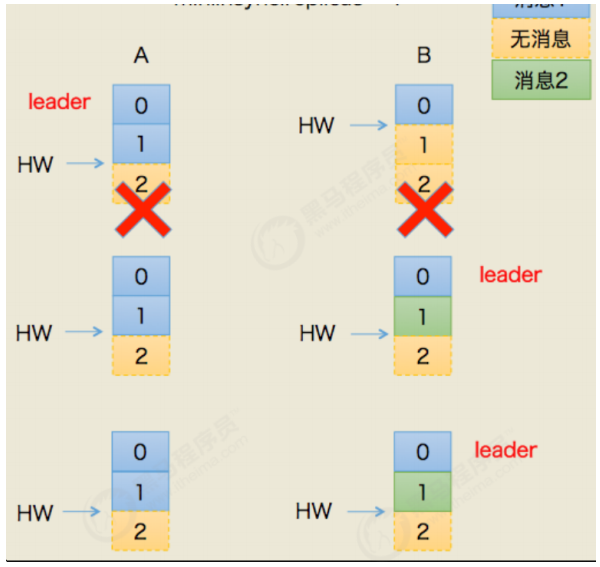
Leader Epoch引用
数据丢失场景
数据出现不一致场景
Kafka 0.11.0.0.版本解决方案
造成上述两个问题的根本原因在于HW值被用于衡量副本备份的成功与否以及在出现failture时作为日志
截断的依据,但HW值的更新是异步延迟的,特别是需要额外的FETCH请求处理流程才能更新,故这中
间发生的任何崩溃都可能导致HW值的过期。鉴于这些原因,Kafka 0.11引入了leader epoch来取代HW
值。Leader端多开辟一段内存区域专门保存leader的epoch信息,这样即使出现上面的两个场景也能很
好地规避这些问题。
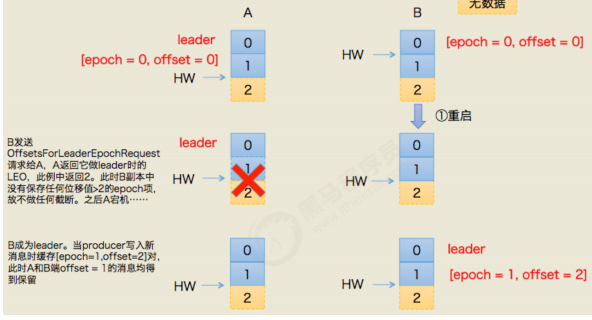
所谓leader epoch实际上是一对值:(epoch,offffset)。epoch表示leader的版本号,从0开始,当
leader变更过1次时epoch就会+1,而offffset则对应于该epoch版本的leader写入第一条消息的位移。因
此假设有两对值:
(0, 0)
(1, 120)
则表示第一个leader从位移0开始写入消息;共写了120条[0, 119];而第二个leader版本号是1,从位移
120处开始写入消息。
leader broker中会保存这样的一个缓存,并定期地写入到一个checkpoint文件中。
避免数据丢失:
避免数据不一致
7.6 消息重复的场景及解决方案
7.6.1 生产者端重复
生产发送的消息没有收到正确的broke响应,导致producer重试。
producer发出一条消息,broke落盘以后因为网络等种种原因发送端得到一个发送失败的响应或者网络
中断,然后producer收到一个可恢复的Exception重试消息导致消息重复。
解决方案:
1、启动kafka的幂等性
要启动kafka的幂等性,无需修改代码,默认为关闭,需要修改配置文
件:enable.idempotence=true 同时要求 ack=all 且 retries>1。
2、ack=0,不重试。
7.6.2 消费者端重复
1、根本原因
数据消费完没有及时提交offffset到broker。
解决方案
1、取消自动自动提交
每次消费完或者程序退出时手动提交。这可能也没法保证一条重复。
2、下游做幂等
一般的解决方案是让下游做幂等或者尽量每消费一条消息都记录offffset,对于少数严格的场景可能需要
把offffset或唯一ID,例如订单ID和下游状态更新放在同一个数据库里面做事务来保证精确的一次更新或者
在下游数据表里面同时记录消费offffset,然后更新下游数据的时候用消费位点做乐观锁拒绝掉旧位点的
数据更新。
7.7 __consumer_offffsets
_consumer_offffsets是一个内部topic,对用户而言是透明的,除了它的数据文件以及偶尔在日志中出现
这两点之外,用户一般是感觉不到这个topic的。不过我们的确知道它保存的是Kafka新版本consumer
的位移信息。
7.7.1 何时创建
一般情况下,当集群中第一有消费者消费消息时会自动创建主题__consumer_offffsets,分区数可以通过
offffsets.topic.num.partitions参数设定,默认值为50,如下
7.7.2 解析分区
见代码库:com.heima.kafka.chapter7.ConsumerOffffsetsAnalysis
获取所有分区
总结
本章主要讲解了Kafka相关稳定性的操作,包括幂等性、事务的处理,同时对可靠性保证与一致性保证
做了讲解,讲解了消息重复以及解决方案。
第8章 高级应用
*tips 学完这一章你可以
作为运维人员掌握命令行工具
使用Connect进行流信息处理
掌握延迟消息、流式处理等
Kafka和SpringBoot整合
8.1 命令行工具
参考官网:http://kafka.apache.org/22/documentation.html
8.1.1 消费组管理
查看消费组
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-consumer-groups.sh --
bootstrap-server localhost:9092 --list
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
从上面可以看出,没有输出任何消费组信息,接下来我们启动一个消费端,再次查询即有消费组信息
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-consumer-groups.sh --
bootstrap-server localhost:9092 --list
group.demo
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
查看消费组详情
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-consumer-groups.sh --
bootstrap-server localhost:9092 --describe --group group.demo
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG
CONSUMER-ID HOST CLIENT-ID
heima 0 0 0 0
consumer-1-38efa901-4917-4660-ab66-3e5b989cbac3 /127.0.0.1 consumer-1
heima 1 0 0 0
consumer-1-38efa901-4917-4660-ab66-3e5b989cbac3 /127.0.0.1 consumer-1
heima 2 0 0 0
consumer-1-38efa901-4917-4660-ab66-3e5b989cbac3 /127.0.0.1 consumer-1
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
查看消费组当前的状态
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-consumer-groups.sh --
bootstrap-server localhost:9092 --describe --group group.demo --state
COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE
#MEMBERS
Server-node.localdomain:9092 (0) range Stable
1
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
消费组内成员信息
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-consumer-groups.sh --
bootstrap-server localhost:9092 --describe --group group.demo --members
CONSUMER-ID HOST CLIENT-ID
#PARTITIONS
consumer-1-38efa901-4917-4660-ab66-3e5b989cbac3 /127.0.0.1 consumer-1
3
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
删除消费组,如果有消费者在使用则会失败
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-consumer-groups.sh --
bootstrap-server localhost:9092 --delete --group group.demo
Error: Deletion of some consumer groups failed:
* Group 'group.demo' could not be deleted due to:
java.util.concurrent.ExecutionException:
org.apache.kafka.common.errors.GroupNotEmptyException: The group is not empty.
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
8.1.2 消费位移管理
重置消费位移,前提是没有消费者在消费,提示信息如下:
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-consumer-groups.sh --
bootstrap-server localhost:9092 --group g
roup.demo --all-topics --reset-offsets --to-earliest --execute
Error: Assignments can only be reset if the group 'group.demo' is inactive, but
the current state is Stable.
TOPIC PARTITION NEW-OFFSET
dayuan@MY-20190430BUDR:/mnt/d/kafka_2.12-2.2.1$
参数:--all-topics指定了所有主题,可以修改为--topics,指定单个主题。
8.2 数据管道Connect
8.2.1 概述
Kafka是一个使用越来越广的消息系统,尤其是在大数据开发中(实时数据处理和分析)。为何集成其
他系统和解耦应用,经常使用Producer来发送消息到Broker,并使用Consumer来消费Broker中的消
息。Kafka Connect是到0.9版本才提供的并极大的简化了其他系统与Kafka的集成。Kafka Connect运
用用户快速定义并实现各种Connector(File,Jdbc,Hdfs等),这些功能让大批量数据导入/导出Kafka很方
便。
在Kafka Connect中还有两个重要的概念:Task 和 Worker。
Connect中一些概念
连接器:实现了Connect API,决定需要运行多少个任务,按照任务来进行数据复制,从work进程获取
任务配置并将其传递下去
任务:负责将数据移入或移出Kafka
work进程:相当与connector和任务的容器,用于负责管理连接器的配置、启动连接器和连接器任务,
提供REST API
转换器:kafka connect和其他存储系统直接发送或者接受数据之间转换数据
8.2.2 独立模式--文件系统
场景
以下示例使用到了两个Connector,将文件source.txt 中的内容通过Source连接器写入Kafka主题中,
然后将内容写入srouce.sink.txt中。
FileStreamSource:从source.txt中读取并发布到Broker中
FileStreamSink:从Broker中读取数据并写入到source.sink.txt文件中
步骤详情
首先我们来看下Worker进程用到的配置文件${KAFKA_HOME}/confifig/connect-standalone.properties
// Kafka集群连接的地址
bootstrap.servers=localhost:9092
// 格式转化类
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
// json消息中是否包含schema
key.converter.schemas.enable=true
value.converter.schemas.enable=true
// 保存偏移量的文件路径
offset.storage.file.filename=/tmp/connect.offsets
// 设定提交偏移量的频率
offset.flush.interval.ms=10000
其中的Source使用到的配置文件是${KAFKA_HOME}/confifig/connect-fifile-source.properties
// 配置连接器的名称
name=local-file-source
// 连接器的全限定名称,设置类名称也是可以的
connector.class=FileStreamSource
// task数量
tasks.max=1
// 数据源的文件路径
file=/tmp/source.txt
// 主题名称
topic=topic0703
其中的Sink使用到的配置文件是${KAFKA_HOME}/confifig/connect-fifile-sink.properties
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=/tmp/source.sink.txt
topics=topic0703
启动source连接器
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/connect-standalone.sh
config/connect-standalone.properties config/connect-file-source.properties
启动slink连接器
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/connect-standalone.sh
config/connect-standalone.properties config/connect-file-sink.properties
source写入文本信息
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ echo "Hello kafka,I
coming;">>/tmp/source.txt
查看slink文件
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ cat /tmp/source.sink.txt
hello,kafka
I to do some
ello kafka,I coming;
Hello kafka,I coming;
8.2.3 信息流--ElasticSearch
概述
Kafka connect workers有两种工作模式,单机模式和分布式模式。在开发和适合使用单机模式的场景
下,可以使用standalone模式, 在实际生产环境下由于单个worker的数据压力会比较大,distributed模
式对负载均和和扩展性方面会有很大帮助。(本测试使用standalone模式)
关于Kafka Connect的详细情况可以参考[Kafka Connect]
Kafka Connect 安装
Worker配置
本测试使用standalone模式,因此修改../etc/schema-registry/connect-avro-standalone.properties
bootstrap.servers=localhost:9092
Elasticsearch Connector配置
修改../etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties
name=elasticsearch-sink
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
tasks.max=1
//其中topics不仅对应Kafka的topic名称,同时也是Elasticsearch的索引名,
//当然也可以通过topic.index.map来设置从topic名到Elasticsearch索引名的映射
topics=topic0703
key.ignore=true
connection.url=http://localhost:9200
type.name=kafka-connect
启动
Elasticsearch
itcast@Server-node:~$ curl 'http://localhost:9200/?pretty'
{
"name" : "MY-20190430BUDR",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "ha3pnLkhRuGEIgXQstYnbQ",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
启动schema Registry
itcast@Server-node:/mnt/d/confluent-5.3.0$ bin/schema-registry-start etc/schema-
registry/schema-registry.properties
[2019-07-22 06:01:00,059] INFO SchemaRegistryConfig values:
access.control.allow.headers =
access.control.allow.methods =
access.control.allow.origin =
authentication.method = NONE
authentication.realm =
authentication.roles = [*]
avro.compatibility.level = backward
compression.enable = true
debug = false
host.name = MY-20190430BUDR.localdomain
idle.timeout.ms = 30000
inter.instance.headers.whitelist = []
inter.instance.protocol = http
kafkastore.bootstrap.servers = []
查看服务是否正常
itcast@Server-node:~$ jps -l
1139 kafka.Kafka
2403 io.confluent.kafka.schemaregistry.rest.SchemaRegistryMain
2474 jdk.jcmd/sun.tools.jps.Jps
2172 org.elasticsearch.bootstrap.Elasticsearch
28 org.apache.zookeeper.server.quorum.QuorumPeerMain
启动Connector
itcast@Server-node:/mnt/d/confluent-5.3.0$ ./bin/connect-standalone etc/schema-
registry/connect-avro-standalone.properties etc/kafka-connect-
elasticsearch/quickstart-elasticsearch.properties
8.4 流式处理Spark
Spark最初诞生于美国加州大学伯克利分校(UC Berkeley)的AMP实验室,是一个可应用于大规模数
据处理的快速、通用引擎。2013年,Spark加入Apache孵化器项目后,开始获得迅猛的发展,如今已
成为Apache软件基金会最重要的三大分布式计算系统开源项目之一(即Hadoop、Spark、Storm)。
Spark最初的设计目标是使数据分析更快——不仅运行速度快,也要能快速、容易地编写程序。为了使
程序运行更快,Spark提供了内存计算,减少了迭代计算时的IO开销;而为了使编写程序更为容易,
Spark使用简练、优雅的Scala语言编写,基于Scala提供了交互式的编程体验。虽然,Hadoop已成为大
数据的事实标准,但其MapReduce分布式计算模型仍存在诸多缺陷,而Spark不仅具备Hadoop
MapReduce所具有的优点,且解决了Hadoop MapReduce的缺陷。Spark正以其结构一体化、功能多
元化的优势逐渐成为当今大数据领域最热门的大数据计算平台。
8.4.1 Spark安装与应用
官网
http://spark.apache.org/downloads.html
下载安装包解压即可
启动
itcast@Server-node:/mnt/d/spark-2.4.3-bin-hadoop2.7$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /mnt/d/spark-2.4.3-
bin-hadoop2.7/logs/spark-dayuan-org.apache.spark.deploy.master.Master-1-MY-
20190430BUDR.out
itcast@localhost's password:
localhost: starting org.apache.spark.deploy.worker.Worker, logging to
/mnt/d/spark-2.4.3-bin-hadoop2.7/logs/spark-dayuan-
org.apache.spark.deploy.worker.Worker-1-MY-20190430BUDR.out
验证
itcast@Server-node:/mnt/d/spark-2.4.3-bin-hadoop2.7$ jps -l
2819 kafka.Kafka
3972 jdk.jcmd/sun.tools.jps.Jps
3894 org.apache.spark.deploy.worker.Worker
28 org.apache.zookeeper.server.quorum.QuorumPeerMain
3726 org.apache.spark.deploy.master.Master
dayuan@MY-20190430BUDR:/mnt/d/spark-2.4.3-bin-hadoop2.7$
浏览器输入:http://127.0.0.1:8080 验证
8.4.3 Spark和Kafka整合
见代码:com.spark.SparkStreamingFromkafka
演示
发送消息
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-console-producer.sh --
broker-list localhost:9092 --topic heima
>hello
>hello
>I coming;
>
>
>
>I coming;
>
接收消息
8.5 SpringBoot Kafka
kafka是一个消息队列产品,基于Topic partitions的设计,能达到非常高的消息发送处理性能。下面通
过一个SpringBoot项目来演示整合Kafka。
8.5.1 创建SpringBoot项目
Kafka_Spring_Learn
验证主类:com.heima.kafka.KafkaApplication
8.5.2 Springboot整合Kafka
添加pom.xml
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka -
->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.2.6.RELEASE</version>
</dependency>
添加application.properties
# Kafka config
spring.kafka.producer.bootstrap-servers=127.0.0.1:9092
消息的发送
/**
* 发送消息
*/
@GetMapping("/send/{input}")
public String sendToKafka(@PathVariable String input) {
this.template.send(topic, input);
return "send success";
}
消息的接收
/**
* 接收消息
*/
@KafkaListener(id = "", topics = topic, groupId = "group.demo")
public void listener(String input) {
logger.info("input value:{}", input);
}
演示效果如下
2019-07-31 10:13:50.653 INFO 11228 --- [nio-8080-exec-3]
o.a.kafka.common.utils.AppInfoParser : Kafka version : 2.0.1
2019-07-31 10:13:50.653 INFO 11228 --- [nio-8080-exec-3]
o.a.kafka.common.utils.AppInfoParser : Kafka commitId : fa14705e51bd2ce5
2019-07-31 10:13:50.659 INFO 11228 --- [ad | producer-1]
org.apache.kafka.clients.Metadata : Cluster ID: VLMqkoXiTt26zV9Inatu2A
2019-07-31 10:13:50.718 INFO 11228 --- [ntainer#0-0-C-1]
com.dayuan.kafka.KafkaApplication : input value:kafka
8.5.3 事务操作
第一种方式
当输入参数为“error”值时,进行了回滚操作。
# 事务支持
spring.kafka.producer.transaction-id-prefix=kafka_tx.
// 事务操作
template.executeInTransaction(t -> {
t.send(topic, input);
if ("error".equals(input)) {
throw new RuntimeException("input is error");
}
t.send(topic, input + " anthor");
return true;
});
return "send success";
第二种方式
@GetMapping("/sendt/{input}")
@Transactional(rollbackFor = RuntimeException.class)
public String sendToKafka2(@PathVariable String input) throws
ExecutionException, InterruptedException {
template.send(topic, input);
if ("error".equals(input)) {
throw new RuntimeException("input is error");
}
template.send(topic, input + " anthor");
return "send success";
}
8.6 消息中间件选型对比
见附录一;
总结
本章主要针对的是Kafka的一些高级应用,作为运维人员经常使用的命令行工具,同时对Kafka的数据管
道做了不同场景的演示,并且使用SpringBoot与Kafka做了整合
第9章 集群管理
*tips 学完这一章你可以
熟悉Kafka集群管理相关内容
配置与调优
集群是一种计算机系统, 它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计
算工作。在某种意义上,他们可以被看作是一台计算机。集群系统中的单个计算机通常称为节点,通常
通过局域网连接,但也有其它的可能连接方式。集群计算机通常用来改进单个计算机的计算速度和/或
可靠性。一般情况下集群计算机比单个计算机,比如工作站或超级计算机性能价格比要高得多。
集群拥有以下两个特点:
1. 可扩展性:集群的性能不限制于单一的服务实体,新的服务实体可以动态的添加到集群,从而增强
集群的性能。
2. 高可用性:集群当其中一个节点发生故障时,这台节点上面所运行的应用程序将在另一台节点被自
动接管,消除单点故障对于增强数据可用性、可达性和可靠性是非常重要的。
集群的能力
1. 负载均衡:负载均衡把任务比较均匀的分布到集群环境下的计算和网络资源,以提高数据吞吐量。
2. 错误恢复:如果集群中的某一台服务器由于故障或者维护需要无法使用,资源和应用程序将转移到
可用的集群节点上。这种由于某个节点的资源不能工作,另一个可用节点中的资源能够透明的接管
并继续完成任务的过程,叫做错误恢复。
负载均衡和错误恢复要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源
来说,执行任务所需的信息视图必须是相同的。
9.1 集群使用场景
Kafka 是一个分布式消息系统,具有高水平扩展和高吞吐量的特点。在Kafka 集群中,没有 “中心主节
点” 的概念,集群中所有的节点都是对等的。
Broker(代理)
每个 Broker 即一个 Kafka 服务实例,多个 Broker 构成一个 Kafka 集群,生产者发布的消息将保存在
Broker 中,消费者将从 Broker 中拉取消息进行消费。
从图中可以看出 Kafka 强依赖于 ZooKeeper ,通过 ZooKeeper 管理自身集群,如:Broker 列表管
理、Partition 与 Broker 的关系、Partition 与 Consumer 的关系、Producer 与 Consumer 负载
均衡、消费进度 Offffset 记录、消费者注册 等,所以为了达到高可用,ZooKeeper 自身也必须是集群。
9.2 集群搭建
9.2.1 ZooKeeper集群搭建
场景
真实的集群是需要部署在不同的服务器上的,但是在我们测试时同时启动十几个虚拟机内存会吃不消,
所以这里我们搭建伪集群,也就是把所有的服务都搭建在一台虚拟机上,用端口进行区分。
我们这里要求搭建一个三个节点的Zookeeper集群(伪集群)。
安装JDK
集群目录
创建zookeeper-cluster目录,将解压后的Zookeeper复制到以下三个目录
itcast@Server-node:/mnt/d/zookeeper-cluster$ ll
total 0
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 ./
drwxrwxrwx 1 dayuan dayuan 512 Aug 19 18:42 ../
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 zookeeper-1/
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 zookeeper-2/
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 zookeeper-3/
itcast@Server-node:/mnt/d/zookeeper-cluster$
ClientPort设置
配置每一个Zookeeper 的dataDir(zoo.cfg) clientPort 分别为2181 2182 2183
# the port at which the clients will connect
clientPort=2181
myid配置
在每个zookeeper的 data 目录下创建一个 myid 文件,内容分别是0、1、2 。这个文件就是记录每个服
务器的ID
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$ cat
temp/zookeeper/data/myid
0
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$
zoo.cfg
在每一个zookeeper 的 zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表。
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$ cat conf/zoo.cfg
# The number of milliseconds of each tick
# zk服务器的心跳时间
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir=/tmp/zookeeper
dataDir=temp/zookeeper/data
dataLogDir=temp/zookeeper/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.0=127.0.0.1:2888:3888
server.1=127.0.0.1:2889:3889
server.2=127.0.0.1:2890:3890
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$
解释:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
启动集群
启动集群就是分别启动每个实例,启动后我们查询一下每个实例的运行状态
itcast@Server-node:/mnt/d/zookeeper-cluster/zookeeper-1$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /mnt/d/zookeeper-cluster/zookeeper-1/bin/../conf/zoo.cfg
Mode: leader
itcast@Server-node:/mnt/d/zookeeper-cluster/zookeeper-2$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /mnt/d/zookeeper-cluster/zookeeper-2/bin/../conf/zoo.cfg
Mode: follower
itcast@Server-node:/mnt/d/zookeeper-cluster/zookeeper-3$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /mnt/d/zookeeper-cluster/zookeeper-3/bin/../conf/zoo.cfg
Mode: follower
9.2.2 Kafka集群搭建
集群目录
itcast@Server-node:/mnt/d/kafka-cluster$ ll
total 0
drwxrwxrwx 1 dayuan dayuan 512 Aug 28 18:15 ./
drwxrwxrwx 1 dayuan dayuan 512 Aug 19 18:42 ../
drwxrwxrwx 1 dayuan dayuan 512 Aug 28 18:39 kafka-1/
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 14:02 kafka-2/
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 14:02 kafka-3/
drwxrwxrwx 1 dayuan dayuan 512 Aug 28 18:15 kafka-4/
itcast@Server-node:/mnt/d/kafka-cluster$
server.properties
# broker 编号,集群内必须唯一
broker.id=1
# host 地址
host.name=127.0.0.1
# 端口
port=9092
# 消息日志存放地址
log.dirs=/tmp/kafka/log/cluster/log3
# ZooKeeper 地址,多个用,分隔
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
启动集群
分别通过 cmd 进入每个 Kafka 实例,输入命令启动
[2019-07-24 06:18:19,793] INFO [Transaction Marker Channel Manager 2]: Starting
(kafka.coordinator.transaction.TransactionMarkerChannelManager)
[2019-07-24 06:18:19,793] INFO [TransactionCoordinator id=2] Startup complete.
(kafka.coordinator.transaction.TransactionCoordinator)
[2019-07-24 06:18:19,846] INFO [/config/changes-event-process-thread]: Starting
(kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread)
[2019-07-24 06:18:19,869] INFO [SocketServer brokerId=2] Started data-plane
processors for 1 acceptors (kafka.network.SocketServer)
[2019-07-24 06:18:19,879] INFO Kafka version: 2.2.1
(org.apache.kafka.common.utils.AppInfoParser)
[2019-07-24 06:18:19,879] INFO Kafka commitId: 55783d3133a5a49a
(org.apache.kafka.common.utils.AppInfoParser)
[2019-07-24 06:18:19,883] INFO [KafkaServer id=2] started
(kafka.server.KafkaServer)
9.3 多集群同步
MirrorMaker是为解决Kafka跨集群同步、创建镜像集群而存在的;下图展示了其工作原理。该工具消
费源集群消息然后将数据重新推送到目标集群。
9.3.1 配置
创建镜像
使用MirrorMaker创建镜像是比较简单的,搭建好目标Kafka集群后,只需要启动mirror-maker程序即
可。其中,一个或多个consumer配置文件、一个producer配置文件是必须的,whitelist、blacklist是
可选的。在consumer的配置中指定源Kafka集群的Zookeeper,在producer的配置中指定目标集群的
Zookeeper(或者broker.list)。
kafka-run-class.sh kafka.tools.MirrorMaker –
consumer.config sourceCluster1Consumer.config –
consumer.config sourceCluster2Consumer.config –num.streams 2 –
producer.config targetClusterProducer.config –whitelist=“.*”
consumer配置文件:
# format: host1:port1,host2:port2 ...
bootstrap.servers=localhost:9092
# consumer group id
group.id=test-consumer-group
# What to do when there is no initial offset in Kafka or if the current
# offset does not exist any more on the server: latest, earliest, none
#auto.offset.reset=
producer配置文件:
# format: host1:port1,host2:port2 ...
bootstrap.servers=localhost:9092
# specify the compression codec for all data generated: none, gzip, snappy, lz4,
zstd
compression.type=none
9.3.2 调优
同步数据如何做到不丢失 首先发送到目标集群时需要确认:request.required.acks=1 发送时采用阻塞
模式,否则缓冲区满了数据丢弃:queue.enqueue.timeout.ms=-1
总结
本章主要对Kafka集群展开讲解,介绍了集群使用场景,Zookeeper和Kafka多借点集群的搭建,以及多
集群的同步操作。
第10章 监控
*tips 学完这一章你可以
知道Kafka的监控体系
掌握JMX监控指标
数据异动实时提醒
在开发工作当中,消费 Kafka 集群中的消息时,数据的变动是我们所关心的,当业务并不复杂的前提
下,我们可以使用 Kafka 提供的命令工具,配合 Zookeeper 客户端工具,可以很方便的完成我们的工
作。
10.1 监控度量指标
10.1.1 JMX
在实现Kafka监控系统的过程中,首先我们要知道监控的数据从哪来,Kafka自身提供的监控指标(包括
broker和主题的指标,集群层面的指标通过各个broker的指标累加来获取)都可以通过JMX(Java
Managent Extension)来进行获取。在使用JMX之前首先要确保Kafka开启了JMX的功能(默认是关闭
的)
在kafka官网中 http://kafka.apache.org/082/documentation.html#monitoring 这样说:
Kafka uses Yammer Metrics for metrics reporting in both the server and the client. This can
be confifigured to report stats using pluggable stats reporters to hook up to your monitoring
system.
The easiest way to see the available metrics to fifire up jconsole and point it at a running
kafka client or server; this will all browsing all metrics with JMX.
在使用jmx之前需要确保kafka开启了jmx监控,kafka启动时要添加JMX_PORT=9999这一项,也就是:
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ JMX_PORT=9999 bin/kafka-server-
start.sh config/server.properties
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},
"endpoints":["PLAINTEXT://Server-node.localdomain:9092"],
"jmx_port":-1,"host":"Server-node.localdomain","timestamp":"1567042701998",
"port":9092,"version":4}
10.1.2 JConsole
在开启JMX之后最简单的监控指标的方式就是使用JConsole,可以通过jconsole连接
service:jmx:rmi:///jndi/rmi://localhost:9999/jmxrmi或者localhost:9999来查看相应的数据值。
10.1.3 编程手段来获取监控指标
详情查看代码:com.heima.kafka.chapter10.JmxConnectionDemo
/**
* JMX Connection
*/
public class JmxConnectionDemo {
private MBeanServerConnection conn;
private String jmxURL;
private String ipAndPort;
public JmxConnectionDemo(String ipAndPort) {
this.ipAndPort = ipAndPort;
}
public boolean init(){
jmxURL = "service:jmx:rmi:///jndi/rmi://" + ipAndPort + "/jmxrmi";
try {
JMXServiceURL serviceURL = new JMXServiceURL(jmxURL);
JMXConnector connector = JMXConnectorFactory
.connect(serviceURL, null);
conn = connector.getMBeanServerConnection();
if (conn == null) {
return false;
}
} catch (IOException e) {
e.printStackTrace();
}
return true;
}
public double getMsgInPerSec() {
String objectName = "kafka.server:type=BrokerTopicMetrics," +
"name=MessagesInPerSec";
Object val = getAttribute(objectName, "OneMinuteRate");
if (val != null) {
return (double) (Double) val;
}
return 0.0;
}
private Object getAttribute(String objName, String objAttr) {
ObjectName objectName;
try {
objectName = new ObjectName(objName);
return conn.getAttribute(objectName, objAttr);
} catch (MalformedObjectNameException | IOException |
ReflectionException | InstanceNotFoundException |
AttributeNotFoundException | MBeanException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) {
JmxConnectionDemo jmxConnectionDemo =
new JmxConnectionDemo("localhost:9999");
jmxConnectionDemo.init();
System.out.println(jmxConnectionDemo.getMsgInPerSec());
}
}
10.2 broker监控指标
10.2.1 活跃控制器
该指标表示 broker 是否就是当前的集群控制器,其值可以是 0 或 l。如果是 1 ,表示 broker 就是当前
的控制器。任何时候,都应该只有一个 broker 是控制器,而且这个 broker 必须一直是集群控制器。如
果出现了两个控制器,说明有一个本该退出的控制器线程被阻 塞了,这会导致管理任务无陆正常执行,
比如移动分区。为了解决这个问题,需要将这两 个 broker 重启,而且不能通过正常的方式重启,因为
此时它们无陆被正常关闭。
kafka.controller:type=KafkaController,name=ActiveControllerCount
值区间:0或1
10.2.2 请求处理器空闲率
Kafka 使用了两个线程地来处理客户端的请求:网络处理器线程池和请求处理器线程池。 网络处理器线
程地负责通过网络读入和写出数据。这里没有太多的工作要做, 也就是说, 不用太过担心这些线程会
出现问题。请求处理器线程地负责处理来自客户端的请求,包括 从磁盘读取消息和往磁盘写入消息。因
此, broker 负载的增长对这个线程池有很大的影响。
kafka.server:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent
10.2.3 主题流入字节
主题流入字节速率使用 bis 来表示,在对 brok巳r 接收的生产者客户端悄息流量进行度量时, 这个度量
指标很有用。该指标可以用于确定何时该对集群进行扩展或开展其他与规模增长 相关的工作。它也可以
用于评估一个 broker 是否比集群里的其他 broker 接收了更多的流 量, 如果出现了这种情况,就需要
对分区进行再均衡。
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec
RateUni.t 这是速率的时间段,在这里是“秒\ 这两个属性表明,速率是通过 bis 来表示的,不管它的值
是基于多长的时间段算出的平均 值。速率还有其他 4 个不同粒度的属性。 OneMi.nuteRate 前 1 分钟
的平均值。 Fi.ve问i.nuteRate 前 5 分钟的平均值。 Fi.fteenMi.nuteRate 前 15 分钟的平均值。
MeanRate 从 broker 启动到目前为止的平均值。
10.2.4 主题流出字节
主题流出字节速率与流入字节速率类似,是另一个与规模增长有关的度量指标。流出字节速 率显示的是
悄费者从 broker读取消息的速率。流出速率与流入速率的伸缩方式是不一样的, 这要归功于 Kafka 对
多消费者客户端的支持。
kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec
10.2.5 主题流入的消息
之前介绍的字节速率以字节的方式来表示 broker 的流量, 而消息速率则以每秒生成消息个 数的方式来
表示流量,而且不考虑消息的大小。这也是一个很有用的生产者流量增长规模 度量指标。它也可以与字
节速率一起用于计算消息的平均大小
kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec
10.2.6 分区数量
broker 的分区数量一般不会经常发生改变,它是指分配给 broker 的分区总数。它包括 broker 的每一
个分区副本,不管是首领还是跟随者
kafka.server:type=ReplicaManager,name=PartitionCount
10.2.7 首领数量
该度量指标表示 broker 拥有的首领分区数量。与 broker 的其他度量一样,该度量指标也应 该在整个
集群的 broker 上保持均等。我们需要对该指析J进行周期性地检查,井适时地发出 告警,即使在副本的
数量和大小看起来都很完美的时候,它仍然能够显示出集群的不均衡 问题。因为 broker 有可能出于各
种原因释放掉一个分区的首领身份,比如 Zookeeper 会话 过期,而在会话恢复之后,这个分区并不会
自动拿回首领身份(除非启用了自动首领再均 衡功能)。在这些情况下,该度量指标会显示较少的首领
分区数,或者直接显示为零。这 个时候需要运行一个默认的副本选举,重新均衡集群的首领