1.XML概念和体系
1.1XML概念
- XML指可扩展标记语言(EXtensible Markup Language)
- XML没有预定义标签,需要自行定义标签
1.2XML特点
- XML数据以纯文本格式存储
- 实现不同应用程序之间的数据通信
- 实现不同平台间的数据通信
- 实现不同平台间的数据共享
- 使用xml将不同的程序、不同的平台之间联系起来
1.3XML的作用
- 数据存储和数据传输
1.4XML和HTML之间的差异
- XML主要作用是数据存储和传输(传输)
- HTML主要作用是用来显示数据(显示)
1.5 一个标准的 XML 文档

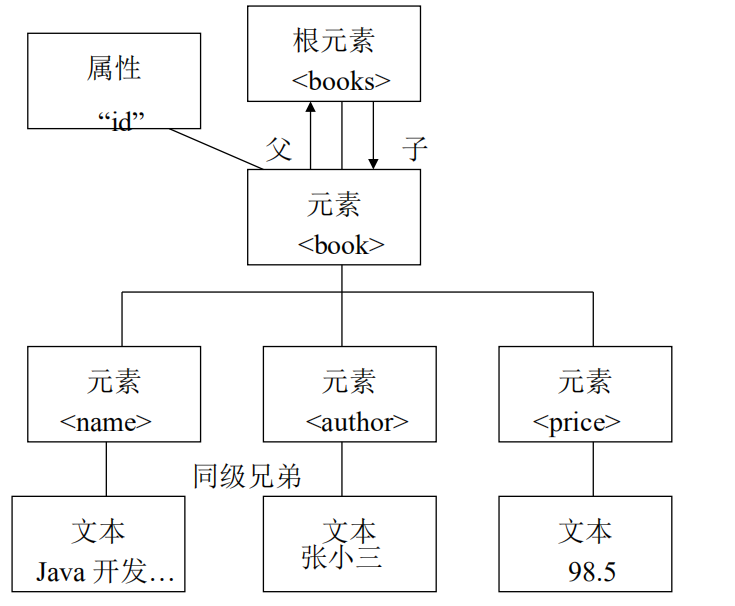
1.6XML 文件的体系
- 1) XHTML 可扩展标识语言
- 2) WSDL Web Services Description Language 网络服务描
- 3) WAP 和 WML 手持设备的标记语言
- 4) RSS( 广 泛 用 于 网 上 新 闻 频 道 ) : Really Simple
Syndication 简易信息聚合,使用 RSS 订阅能更快地获取
信息,网站提供 RSS 输出,有利于让用户获取网站内容
的最新更新
- 5) RDF 和 OWL: 重要的语义网技术语义网是为资产管理、
企业整合及网络数据的共享和重用提供的一个框架。
- 6) SMIL 同步多媒体集成语言,它是由万维网联盟规定的多
媒体操纵语言。最新的 SMIL 版本是 2001 年 8 月推出的
SMIL 2.0 版本,它通过时序排列对声音、影像、文字及图
形文件进行顺序安排,然后将这些媒体表现看起来是同步
的
2.XML 基本语法
2.1XML 的基本语法
- 1) 有且只有一个根元素
- 2) XML 文档声明必须放在文档的第一行
- 3) 所有标签必须成对出现
- 4) XML 的标签严格区分大小写
- 5) XML 必须正确嵌套
- 6) XML 中的属性值必须加引号
- 7) XML 中,一些特殊字符需要使用“实体”
- 8) XML 中可以应用适当的注释
2.2XML 元素
XML 元素指的是开始标签到结束标签的部分
一个元素中可以包含
- 1) 其他元素
- 2) 文本
- 3) 属性
- 4) 以上的混合
2.3XML 命名规则
- 1) 名称可以包含字母、数字及其他字符
- 2) 名称不能以数字或者标点符号开始
- 3) 名称不能以字母 xml 开始
- 4) 名称不能包含空格
3.Schema 技术
3.1DTD 验证
概念:DTD 文档类型定义
作用:验证是否是“有效”的 XML
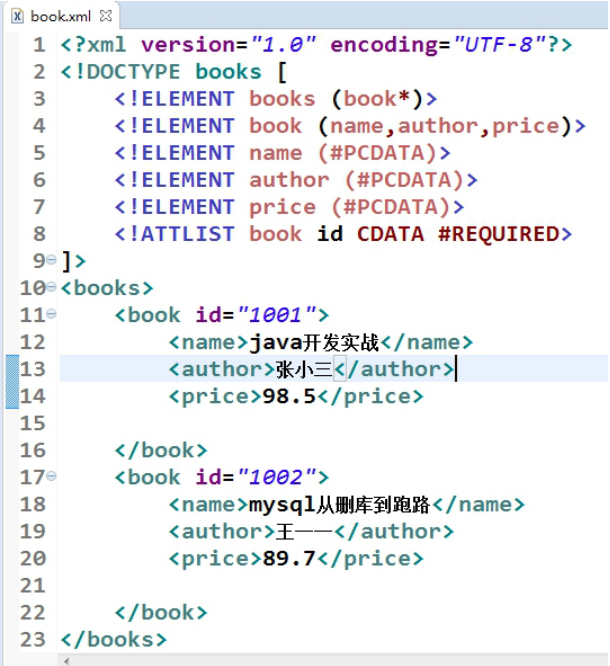
PCDATA(Parsed Character DATA)的意思是被解析的字符数据
CDATA(Unparsed Character Data)不应由 XML 解析器进行解析的文本数据
使用 DTD 的局限性
1) DTD 不遵守 XML 语法
2) DTD 数据类型有限
3) DTD 不可扩展
4) DTD 不支持命名空间
3.2Schema 技术
Schema 是 DTD 的代替者,名称为 XML Schema,用于描述XML 文档结构,比 DTD 更加强大,最主要的特征之一就是XML Schema 支持数据类型
1) Schema 是用 XML 验证 XML 遵循 XML 的语法
2) Schema 可以用能处理 XML 文档的工具处理
3) Schema 大大扩充了数据类型,而且还可以自定义数据类型
4) Schema 支持元素的继承
5) Schema 支持属性组
3.3Schema 的文档结构

所有的 Schema 文档使用 schema 作为其根元素
http://www.w3.org/2001/XMLSchema:用于验证当前 Schema
文档的命名空间(用于验证Schema本身)同时它还规定了来自
命名空间 http://www.w3.org/2001/XMLSchema 的元素和数据
类型应该使用前缀 xs:
xmlns 相当于 java 中的 import, :xs
“小名”,在使用时要写加
“小名”做前缀
(XML 使用 Schema 验证,那 Schema 也是一个 XML,谁来
验证它?DTD)
3.3 使用 Schema 验证 XML 文档
1) 创建 SchemaFactory 工厂
2) 建立验证文件对象
3) 利用 SchemaFactory 工厂对象,接收验证的文件对象,生
成 Schema 对象
4) 产生对此 schema 的验证器
5) 要验证的数据(准备数据源)
6) 开始验证


1 package com.bjsxt.schema; 2 3 import java.io.File; 4 import java.io.IOException; 5 6 import javax.xml.transform.Source; 7 import javax.xml.transform.stream.StreamSource; 8 import javax.xml.validation.Schema; 9 import javax.xml.validation.SchemaFactory; 10 import javax.xml.validation.Validator; 11 12 import org.xml.sax.SAXException; 13 14 public class Test { 15 public static void main(String[] args) throws SAXException { 16 //(1)创建SchemaFactory工厂 17 SchemaFactory sch=SchemaFactory.newInstance("http://www.w3.org/2001/XMLSchema"); 18 //(2)建立验证文件对象 19 File schemaFile=new File("book.xsd"); 20 //(3)利用SchemaFactory工厂对象,接收验证的文件对象,生成Schema对象 21 Schema schema=sch.newSchema(schemaFile); 22 //(4)产生对此schema的验证器 23 Validator validator=schema.newValidator(); 24 //(5)要验证的数据(准备数据源) 25 Source source=new StreamSource("book.xml"); 26 //(6)开始验证 27 try { 28 validator.validate(source); 29 System.out.println("成功"); 30 } catch (IOException e) { 31 // TODO Auto-generated catch block 32 e.printStackTrace(); 33 System.out.println("失败"); 34 } 35 } 36 }
<?xml version="1.0" encoding="UTF-8"?> <!-- <!DOCTYPE books [ <!ELEMENT books (book*)> <!ELEMENT book (name,author,price)> <!ELEMENT name (#PCDATA)> <!ELEMENT author (#PCDATA)> <!ELEMENT price (#PCDATA)> <!ATTLIST book id CDATA #REQUIRED> ]>--> <books xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="{book.xsd}"> <book id="1001"> <name>java开发实战</name> <author>张小三</author> <price>98.5</price> </book> <book id="1002"> <name>mysql从删库到跑路</name> <author>王一一</author> <price>89.7</price> </book> </books>
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" >
<xs:element name="books">
<xs:complexType>
<xs:sequence>
<xs:element name="book" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string"></xs:element>
<xs:element name="author" type="xs:string"></xs:element>
<xs:element name="price" type="xs:double"></xs:element>
</xs:sequence>
<xs:attribute name="id" type="xs:positiveInteger" use="required"></xs:attribute>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
4.DOM 方式解析 XML 数据
在 Java 程序中读取 XML 文件的过程称为解析 XML
4.1 解析 XML 文件的方式
- 1) DOM 解析 (java 官方提供)
- 2) SAX 解析(java 官方提供)
- 3) JDOM 解析(第三方提供)
- 4) DOM4J 解析(第三方提供)
4.2DOM 解析 XML 的步骤
- 1) 创建一个 DocumentBuilderFactory 的对象
- 2) 创建一个 DocumentBuilder 对象
- 3) 通过DocumentBuilder的parse(...)方法得到Document对象
- 4) 通过 getElementsByTagName(...)方法获取到节点的列表
- 5) 通过 for 循环遍历每一个节点
- 6) 得到每个节点的属性和属性值
- 7) 得到每个节点的节点名和节点值
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="1001">
<name>java开发实战</name>
<author>张小三</author>
<price>98.5</price>
</book>
<book id="1002">
<name>mysql从删库到跑路</name>
<author>王一</author>
<price>93.5</price>
</book>
</books>
package dom; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.NamedNodeMap; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class TestDOMParse { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { //1创建一个documentBuilderFactory的对象 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance(); //2创建一个DocumentBuilder对象 DocumentBuilder db=dbf.newDocumentBuilder(); //3通过DocumentBuilder的parse(...)方法得到Document对象 Document doc = db.parse("book.xml"); //4通过getElementsByTagName(...)方法获取节点的列表 NodeList bookList = doc.getElementsByTagName("book");/// System.out.println(bookList.getLength()); //5通过for循环遍历每一个节点 for (int i = 0; i < bookList.getLength(); i++) { //6得到每个节点的属性和属性值 Node book = bookList.item(i); NamedNodeMap attrs = book.getAttributes(); //循环遍历每一个属性 for(int j=0;j<attrs.getLength();j++){ //得到每一个属性 Node id=attrs.item(j); System.out.println("属性的名称:"+id.getNodeName()+" "+id.getNodeValue()); } } System.out.println(" 每个节点的名和节点的值"); //7得到每个节点的节点名和节点值 for (int i = 0; i < bookList.getLength(); i++) { //得到每个book节点 Node book = bookList.item(i); NodeList subNode = book.getChildNodes(); System.out.println("得到子节点的个数"+subNode.getLength()); //使用for循环遍历每一个book子节点 for(int j=0;j<subNode.getLength();j++){ Node childNode = subNode.item(j); // System.out.println(childNode.getNodeName()); short type=childNode.getNodeType();//获取节点的类型 if(type==Node.ELEMENT_NODE){ System.out.println("节点的名称:"+childNode.getNodeName()+" "+childNode.getTextContent()); } } } } }
5.SAX 方式解析 XML 数据
5.1SAX 的概述
SAX,全称 Simple API for XML,是一种以事件驱动的
XMl API,SAX 与 DOM 不同的是它边扫描边解析,自顶向下
依次解析,由于边扫描边解析,所以它解析 XML 具有速度
快,占用内存少的优点
5.2SAX 解析 XML 的步骤
- 1) 创建 SAXParserFactory 的对象
- 2) 创建 SAXParser 对象 (解析器)
- 3) 创建一个 DefaultHandler 的子类
- 4) 调用 parse 方法
package com.bjsxt.sax; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; public class BookDeaultHandler extends DefaultHandler { //重写第一个方法 /**解析xml文档开始时调用*/ @Override public void startDocument() throws SAXException { // TODO Auto-generated method stub super.startDocument(); System.out.println("解析xml文档开始"); } /*解析xml文档结束时调用*/ @Override public void endDocument() throws SAXException { // TODO Auto-generated method stub super.endDocument(); System.out.println("解析xml文档结束"); } /**解析xml文档中的节点时调用*/ @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { // TODO Auto-generated method stub super.startElement(uri, localName, qName, attributes); //System.out.println("解析xml文档中的节点时调用"); /**判断,如果是book节点,获取节点的属性和属性值*/ if("book".equals(qName)){ //获取所有的属性 int count=attributes.getLength();//属性的个数 //循环获取每个属性 for(int i=0;i<count;i++){ String attName=attributes.getQName(i);//属性名称 String attValue=attributes.getValue(i);//属性值 System.out.println("属性名称:"+attName+" 属性值为:"+attValue); } }else if(!"books".equals(qName)&&!"book".equals(qName)){ System.out.print("节点的名称:"+qName+" "); } } /**解析xml文档中的节点结束调用*/ @Override public void endElement(String uri, String localName, String qName) throws SAXException { // TODO Auto-generated method stub super.endElement(uri, localName, qName); //System.out.println("解析xml文档中的节点结束调用"); } @Override public void characters(char[] ch, int start, int length) throws SAXException { // TODO Auto-generated method stub super.characters(ch, start, length); String value=new String(ch,start,length); if(!"".equals(value.trim())){ System.out.println(value); } } }
package com.bjsxt.sax; import java.io.IOException; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.SAXException; public class TestSAXParse { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { //1) 创建SAXParserFactory的对象 SAXParserFactory spf=SAXParserFactory.newInstance(); //2) 创建SAXParser对象 (解析器) SAXParser parser=spf.newSAXParser(); //3) 创建一个DefaultHandler的子类 BookDeaultHandler bdh=new BookDeaultHandler(); //4) 调用parse方法 parser.parse("book.xml", bdh); } }
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="1001">
<name>java开发实战</name>
<author>张小三</author>
<price>98.5</price>
</book>
<book id="1002">
<name>mysql从删库到跑路</name>
<author>王一</author>
<price>93.5</price>
</book>
</books>
6.JDOM 解析 XML 数据
6.1JDOM 概述
JDOM 是一种解析 XML 的 Java 工具包,它基于树型结构,
利用纯Java的技术对XML文档实现解析。所以中适合于Java
语言
6.2JDOM 解析 XML 的步骤
- 1) 创建一个 SAXBuilder 对象
- 2) 调用 build 方法,得到 Document 对象(通过 IO 流)
- 3) 获取根节点
- 4) 获取根节点的直接子节点的集合
- 5) 遍历集合
package com.bjsxt.jdom; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.util.List; import org.jdom.Attribute; import org.jdom.Document; import org.jdom.Element; import org.jdom.JDOMException; import org.jdom.input.SAXBuilder; public class TestJDOM { public static void main(String[] args) throws FileNotFoundException, JDOMException, IOException { // 1) 创建一个SAXBuilder对象 SAXBuilder sb=new SAXBuilder(); // 2) 调用build方法,得到Document对象(通过IO流) Document doc=sb.build(new FileInputStream("book.xml")); // 3) 获取根节点 Element root=doc.getRootElement(); //books元素 // 4) 获取根节点的直接子节点的集合 List<Element> bookEle=root.getChildren();//book,2个book // 5) 遍历集合,得到book的每一个子节点(子元素) for(int i=0;i<bookEle.size();i++){ Element book=bookEle.get(i); //得到属性集合 List<Attribute> attList=book.getAttributes(); //遍历属性的集合得到每一个属性 for (Attribute attr : attList) { System.out.println(attr.getName()+" "+attr.getValue()); } } //得到每一个子节点 System.out.println(" -----------------------"); for(int i=0;i<bookEle.size();i++){ Element book=bookEle.get(i);//得到每一个book节点 List<Element> subBook=book.getChildren(); //遍历每一个节点,获取节点名称节点值 for (Element ele : subBook) { System.out.println(ele.getName()+" "+ele.getValue()); } System.out.println("========================================="); } } }
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="1001">
<name>java开发实战</name>
<author>张小三</author>
<price>98.5</price>
</book>
<book id="1002">
<name>mysql从删库到跑路</name>
<author>王一一</author>
<price>89.7</price>
</book>
</books>
7.DOM4J 方式解析 XML 数据
DOM4J 是一个 Java 的 XML API,是 JDOM 的升级品,
用来读写 XML 文件的
7.1DOM4J 解析 XML 的步骤
- 1) 创建 SAXReader 对象
- 2) 调用 read 方法
- 3) 获取根元素
- 4) 通过迭代器遍历直接节点
7.2 四种解析 XML 的特点
- 1)DOM 解析:形成了树结构,有助于更好的理解、掌握,且代码容易编写。解析过程中,树结构保存在内存中,方便修改。
- 2)SAX 解析:采用事件驱动模式,对内存耗费比较小。适用于只处理 XML 文件中的数据时
- 3)JDOM 解析:仅使用具体类,而不使用接口。API 大量使用了 Collections 类。
package com.bjsxt.entity; public class Book { //私有属性 private String name; private String author; private double price; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getAuthor() { return author; } public void setAuthor(String author) { this.author = author; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } public Book(String name, String author, double price) { super(); this.name = name; this.author = author; this.price = price; } public Book() { super(); } }
package com.bjsxt.dom4j; import java.io.File; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; import com.bjsxt.entity.Book; public class TestDOM4J { public static void main(String[] args) throws DocumentException { // 1) 创建SAXReader对象 SAXReader reader=new SAXReader(); // 2) 调用read方法 Document doc=reader.read(new File("book.xml")); // 3) 获取根元素 Element root=doc.getRootElement();//books // 4) 通过迭代器遍历直接节点 for(Iterator<Element> iteBook=root.elementIterator();iteBook.hasNext();){ Element bookEle=iteBook.next(); //System.out.println(bookEle.getName()); //得到book的属性 for(Iterator<Attribute> iteAtt=bookEle.attributeIterator();iteAtt.hasNext();){ Attribute att=iteAtt.next(); System.out.println(att.getName()+" "+att.getText()); } } System.out.println(" ------------------------------------"); List<Book> bookList=new ArrayList<Book>(); for(Iterator<Element> iteBook=root.elementIterator();iteBook.hasNext();){ //创建Book对象 Book book=new Book(); Element bookEle=iteBook.next();//得到每一个book //使用for循环继续遍历 for(Iterator<Element> subBookEle=bookEle.elementIterator();subBookEle.hasNext();){ //得到每一个子元素 Element subEle=subBookEle.next(); System.out.println(subEle.getName()+" "+subEle.getText()); /** * 封装成Book对象 * */ //获取节点的名称 String nodeName=subEle.getName();//name,author,price //使用switch判断 switch (nodeName) { case "name": book.setName(subEle.getText()); break; case "author": book.setAuthor(subEle.getText()); break; case "price": book.setPrice(Double.parseDouble(subEle.getText())); break; } } //添加到集合中 bookList.add(book); } //遍历集合 System.out.println(" 遍历集合----------------------- "); for (Book b : bookList) { System.out.println(b.getName()+" "+b.getAuthor()+" "+b.getPrice()); } } }
8.XPATH 技术_快速获取节点
8.1 准备资源
- 1) DOM4J 的 jar 包
- 2) Jaxen 的 jar 包
- 3) Xpath 中文文档
package com.bjsxt.xpath; import java.util.List; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Node; import org.dom4j.io.SAXReader; public class Test { public static void main(String[] args) throws DocumentException { //(1)SAXReader对象 SAXReader reader=new SAXReader(); //(2)读取XML文件 Document doc=reader.read("book.xml"); //得到第一个author节点 Node node=doc.selectSingleNode("//author"); System.out.println("节点的名称:"+node.getName()+" "+node.getText()); //获取所有的author System.out.println(" -----------------------"); List<Node> list=doc.selectNodes("//author"); for (Node n : list) { System.out.println("节点名称:"+n.getName()+" "+n.getText()); } //选择有id属性的book元素 List<Attribute> attList=doc.selectNodes("//book/@id"); for (Attribute att : attList) { System.out.println("属性的名称:"+att.getName()+" "+att.getText()); } } }
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="1001">
<name>java开发实战</name>
<author>张小三</author>
<price>98.5</price>
</book>
<book id="1002">
<name>mysql从删库到跑路</name>
<author>王一一</author>
<price>89.7</price>
</book>
</books>