spark和mapreduce差不多,都是一种计算引擎,spark相对于MapReduce来说,他的区别是,MapReduce会把计算结果放
在磁盘,spark把计算结果既放在磁盘中有放在内存中,mapreduce把可能会把一个大任务分成多个stage,瓶颈发生在IO,spark有一个叫DAG(有向无环图)的东西,可以把多个算子都放在一个stage进行合并。
spark shuffle的时候一定会把数据放在磁盘中,因为如果在shuffle的时候数据丢失,代价特别的昂贵
spark和mapreduce最大的区别是,spark可以把中间结果即放在内存,又可以放在磁盘中。
因为现在内存和以前比已经很大了,能放在内存就放在内存里。但mapreduce是把中间结果放在磁盘中的
,磁盘的IO速度太慢了,所以spark比mapreduce快很多了
spark仅仅可以替代的是mapreduce。spark有个很重要的东西是DAG(有向无环图)
可以将多个相同的算子合并到一个stage里面(以后学。。)
spark在shuffle的时候一定是在内存中的,但为了保证数据的安全性,也会把数据写入磁盘,不然恢复的时候代价比较大
spark可以运行在hadoop,yarn,Mesos(Apache的一个资源调度框架),standalone(spark自带的)。。。
spark主节点master,工作节点worker,master可以部署两个,解决单点故障,这时候可以引入zookeeper
安装
首先我们的电脑上要有jdk8以上的版本
还有hadoop的hdfs就行
我们机器的规划可以是两个master,一个zookeeper
我们现在官网上下载一个spark,然后传到你的机器集群中,解压安装到指定目录
然后进入到conf目录
然后修改两个配置文件

vim spark-env.sh
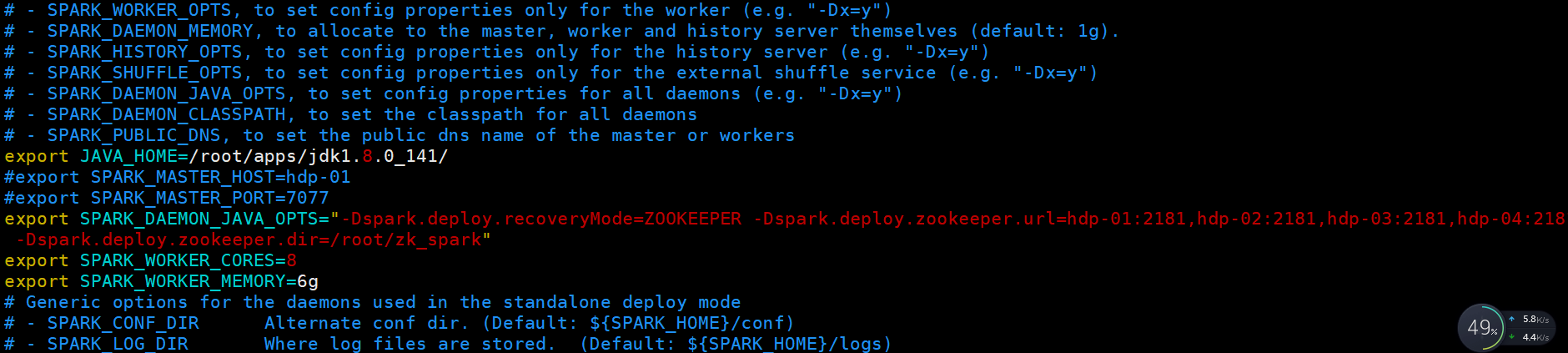
里面含义,指定你的jdk路径,指定你的zookeeper机器都有哪台,指定每台机器的内核数(线程数量),每台机器的使用内存
这里面不用安装scala了,因为spark里面已经安装好了
:r! echo /root/spark //小知识在vim里面输出
linux脚本
一个简单的for循环
for i in {5..8}; do echo $i; done
scp的时候如果机器太多可以写个脚本
for i in {1..5}; do scp -r /root/apps/spark/ hdp-0$i:/root/apps/; done
然后修改slaves文件,把你的worker机器给写入进去就行了
然后把你的spark 给拷贝到其他机器上
然后启动的话sbin下有一个start-all.sh
sbin/start-all.sh 启动即可,这个最好首先配置好master上对其他机器的免密登录
master上的网页显示端口是8080,内部通信端口是7077
现在可以试着配置spark的高可用
修改spark-env.sh
export JAVA_HOME=/root/apps/jdk1.8.0_141/
#export SPARK_MASTER_HOST=hdp-01
#export SPARK_MASTER_PORT=7077export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hdp-01:2181,hdp-02:2181,hdp-03:2181,hdp-04:2181 -Dspark.deploy.zookeeper.dir=/root/zk_spark"
export SPARK_WORKER_CORES=8
export SPARK_WORKER_MEMORY=6g
修改后启动你的zookeeper
县启动你的集群
sbin/start-all.sh
然后再一台有zookeeper的机器上在启动一个master
sbin/start-master.sh
提交第一个spark程序
提交一个程序需要一个客户端 人家名字叫sparkSubmit(Driver)
给活跃的master提交任务,
随便找一台机器当做客户端,在安装包里有一个example
[root@hdp-02 spark-2.4.3-bin-hadoop2.7]# bin/spark-submit --master spark://hdp-01:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.3.jar 500
这里只是用了人家的样例,最后数字是采多少样本
在执行任务的时候,master会启动sparksubmit,还有个coarserGrainedExecutorBackend
这个东西是真正执行任务的东西
程序执行完,这几个进程就会被释放。
可以指定参数,可以指定多个master,比如用多大内存,内核数
参数说明:
--master spark://node1.edu360.cn:7077 指定Master的地址
--executor-memory 2g 指定每个worker可用内存为2G
--total-executor-cores 2 指定整个集群使用的cup核数为2个
[root@hdp-02 spark-2.4.3-bin-hadoop2.7]# bin/spark-submit --master spark://hdp-01:7077,hdp-02:7077 --class org.apache.spark.examples.SparkPi --executor-memory 2048mb --total-executor-cores 12 examples/jars/spark-examples_2.11-2.4.3.jar 500
spark shell交互式命令行,方便学习和测试,可以写spark程序,也是一个客户端
启动spark shell
bin/spark-shell,这样启动没有启动master,是local模式运行的,是模拟的
bin/spark-shell --master spark://hdp-01:7077
此时执行spark-shell的机器也会执行subsubmit
workder也会启动coarserGrainedExecutorBackend,即使现在还没有提交任务,他们在准备工作
在spark-shell中提交一个wordcount程序.....scale一句搞定
sc.textFile 指定读取哪里的文件,注意要是所有的机器都能访问的,不能只是本地的,最好是HDFS的
sc.textFile("hdfs://hdp-01:9000/wordcount/input").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect
sc是spark core(RDD)的执行入口
spark都有哪些进程
首先启动master,然后启动worker,worker会向master注册,然后不停发送心跳检测
master,如果只有一个,会把这些信息保存到磁盘,如果有多个,会保存在zookeeper
1.客户端通过命令行参数知道master在哪,并设置一些参数,比如内存资源和内核数,会先添加任务,然后向master申请资源
2.然后master就会在worker里面查找,负责资源调度(就是将executor在哪些worker启动)
3.master和work进行RPC通信,让worker启动executor(将分配的参数传递过去)然后worker启动executor。
4.接下来,executor和客户端sparksubmit进行通信(通过master-》worker-》execotor这样知道客户端在哪)。
5.然后把sparksubmit把真正的计算逻辑生成task发送给executor。
6.然后再executor执行真正的计算逻辑
yarn和spark的standalone调度模式对比
resourcemanager master 管理子节点,资源调度,接受任务请求
nodemanager worker 管理当前结点,并管理子进程
yarnchild executor 运行真正的计算逻辑的
client sparksubmit (client+ApplicationMaster)提交任务,管理该任务的executor,并将task提交给集群
ApplicationMaster
用scala语言简单写一个wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/
object wordcount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//spark程序的入口
val sc = new SparkContext(conf)
//得到在哪开始读取数据
val lines: RDD[String] = sc.textFile(args(0))
//切分压平
val words: RDD[String] = lines.flatMap(_.split(" "))
//把每个单词都变成(单词,1)的元组
val wordAndOne: RDD[(String,Int)] = words.map((_,1))
//然后进行聚合
val reduced: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序
val sorts = reduced.sortBy(_._2, false)
//保存
sorts.saveAsTextFile(args(1))
sc.stop()
}
}
然后把这个程序打包放到集群中
./spark-submit --master spark://hdp-01:7077 --class test.ScalaWordCount /root/test.jar hdfs://hdp-01:9000/wc hdfs://hdp-01:9000/wcout