学习scala的原因主要是因为以后要学习spark。
scala是运行在java虚拟机上的,它是一种面向对象和函数式编程结合的语言,并兼容java程序
相对于java更简单
安装scala前提你要保证你已经安装好了jdk
然后
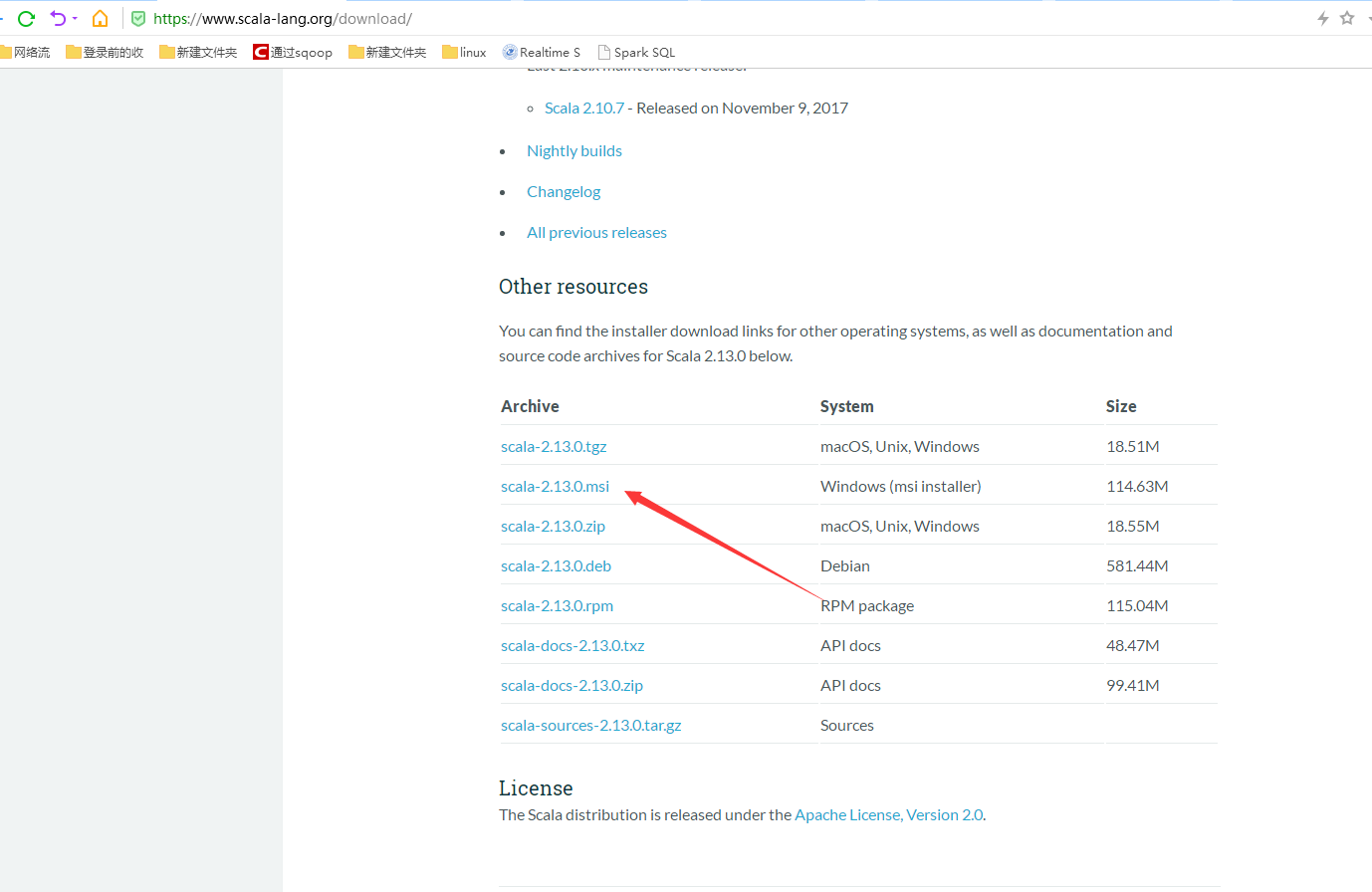
下载这个msi版本的,下载完直接下一步下一步傻瓜安装
然后下载个IDEA
第一次新的IDEA没法创建scala

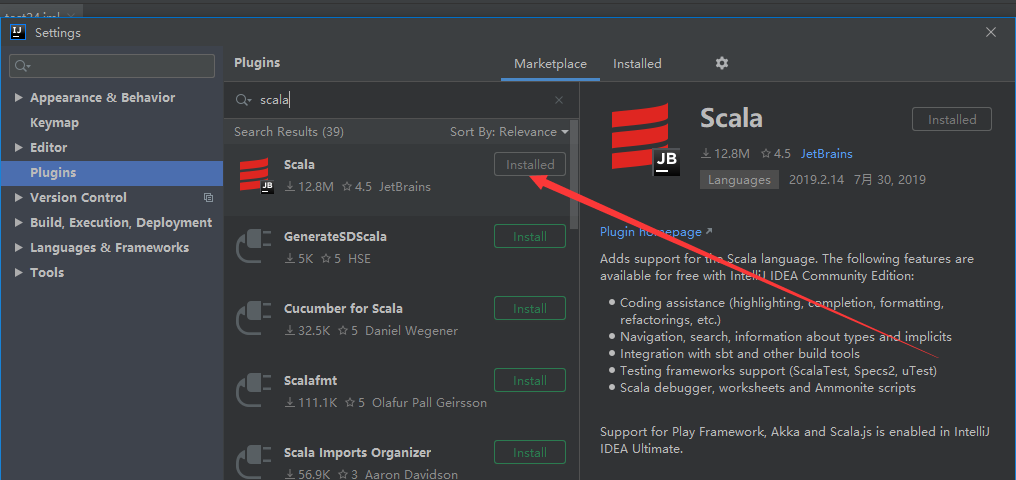
然后创建一个scala程序
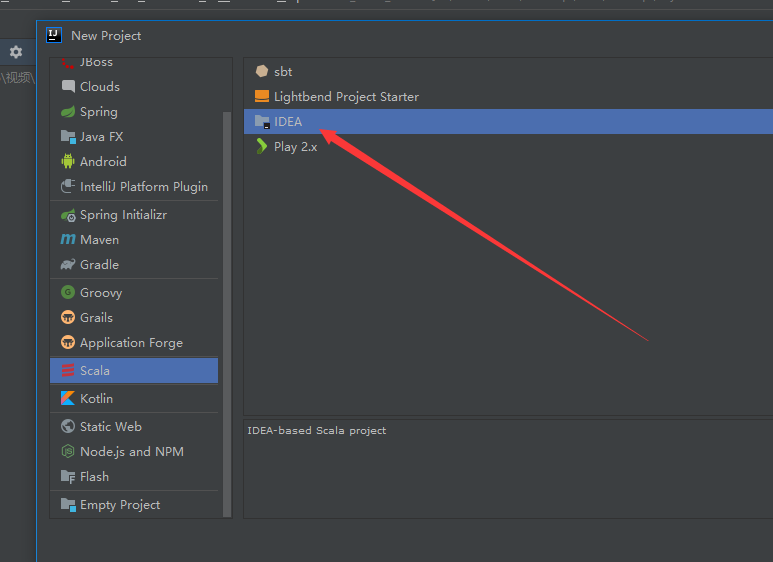
然后选择你的sdk位置和jdk版本
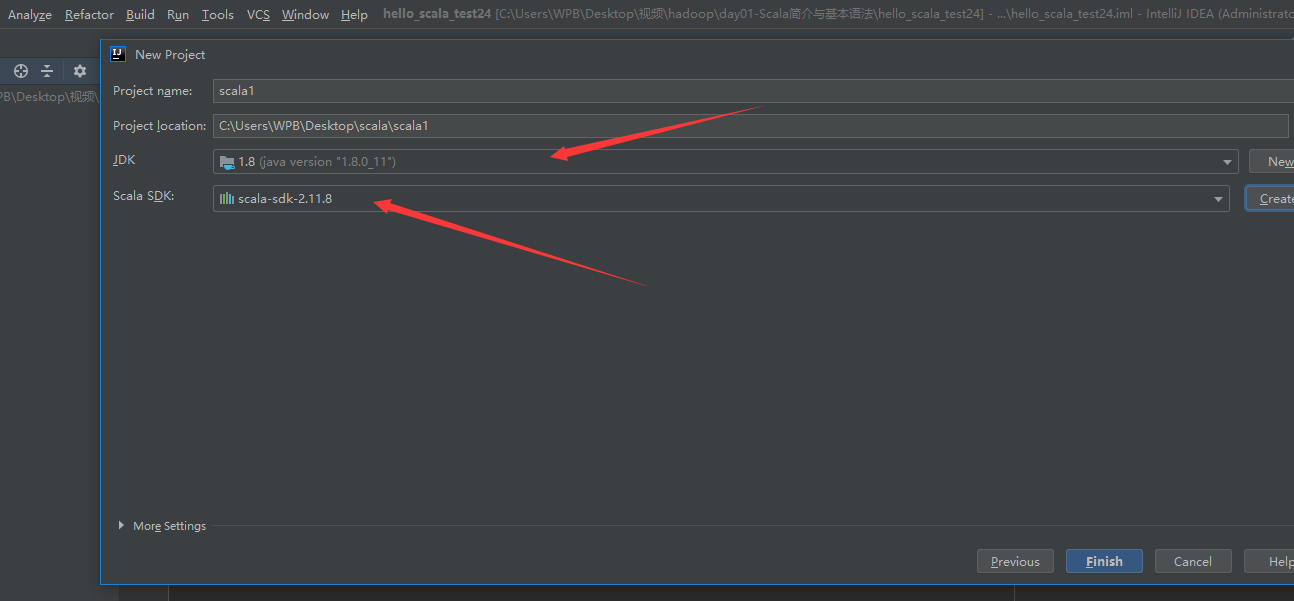
然后finsh
在src下创建一个scala class文件

在这里可以为你的工程添加依赖外部包啥的
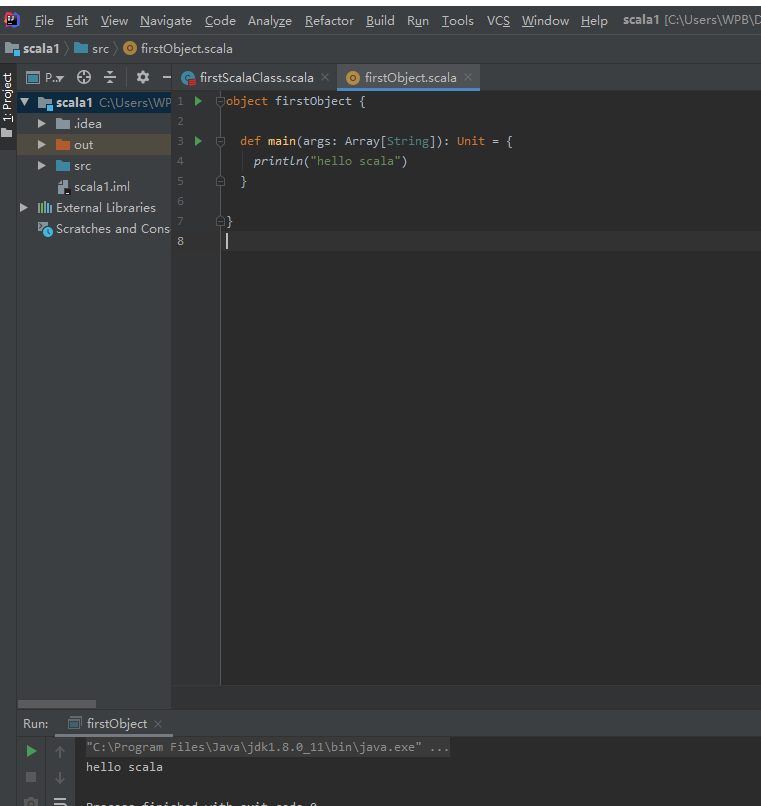
ok开始一些简单地学习
scala和java一样,有9种数值类型Byte,Char,Short,Int,Long,Float,Double,Boolean,
还有一个Unit类型,它表示无值和void差不多
在java,object是所有类的祖先,在scala中是Any,上面说的几种类型都是Anyval,其他的都是AnyRef
object firstObject {
def main(args: Array[String]): Unit = {
var name = "wangpeibing"
var age = 18.0//编译器会根据你的值默认的指定你的数据类型
var name1: String = "zhangsan"//你也可以指定这个数据类型
val name2: String = "lisi" //val也可以创建,但val修饰的东西他不能再改变,类似于java中的final
val s = ()//此时s为unit类型的
println("name = "+name, "age=" + age)
println("name = "+name + "age=" + age)//加,在外面输出的时候会带上括号,不加就不带
printf("name %s age %f",name,age)//类似于c语言中动态的取值
println()
println(f"$name $age")//f插值器允许创建一个格式化的字符串
println(s"1 + 1 = ${1+1}")//使用$可以去表达式的值
val s1 = if(age > 20) 20 else if(age > 10) 10 else 0//条件表达式
val s2 = if(age > 10){//条件表达式会把最后一行当做返回值 虽然没有return,但默认的带上了,自己就不要再加return 了
age
age * 10
} else {
0
100
}
println(s2)
var s3 = if(age > 10)"xxxx" else 20//此时s3是一个Any类型的,因为XXXX是String,是AnyRef,Int是AnyVal类型,他们都是Any类型的
print(s3)
} }
定义函数和for循环
package cn.edu360.day3
object learning {
def sayhello = print("hello")
def sayhello2() = println("hello2")
//def 方法名(属性名:属性类型.....):方法返回值(也可以不写,系统自动生成) = {具体的方法}
def sum(a:Int,b:Int):Int = {
return a+b //最后一行自带return,所以这个也可以不加return
}
def main(args: Array[String]): Unit = {
val arr = Array(1,2,3,4,5)
sayhello
sayhello2()
println("a + b:" + sum(1,2))
for(ele <- 0 to 4){
println(arr(ele))
}
for(ele <- arr){ //一个for循环类似java的增强for循环
println(ele)
}
//scala里面的to方法,1 to 10 其实是1.to(10),是从1到10
// 1 until 10是1到9
for(e <- arr if e % 2 == 0){//增加一个条件
println(e)
}
for(i <- 1 to 3; j <- 1 to 5 if(i == j)){//双重for循环
println(i)
}
var test = for(e <- arr if e % 2 == 0) yield e //此时会将结果放到一个新的集合中去,然后返回给test
//scala的运算符都是一个方法1+2为 1.+(2)
//讲方法转化成函数
val fun = sum _
//定义一个方法
var fun1 = (a:Int, b:Int, c:Int) => a+b+c
println(fun1(1,2,3))
//另一种麻烦的写法
//var 函数名:(参数类型...)=>函数返回值=(对前面参数类型的引用) =>(具体方法)
var fun2:(Int, Int, Int) => Int =(x,y,z) =>(x+y+z)
println(fun2(1,2,3))
}
}
函数作为参数传到方法里面
package cn.edu360.day3
object learning2 {
//函数作为参数传入方法,只写出参数类型和返回类型
//方法其实就像是java里面的接口,思想就是这个,只不过实现起来更加方便
def add2(f:(Int, Int)=> Int, a: Int, b: Int)={
f(a,b)
}
def add3(f:Int=>Int, t:Int):Int={
f(t) + t
}
def main(args: Array[String]): Unit = {
var f:(Int, Int)=>Int=(x,y)=>(x+y)
var test = add2(f,1,2)
var test2 = add2((x,y)=>(x+y),3,4)//使用匿名函数
println(test)
println(test2)
var f1:(Int)=>Int = (a: Int) => a*10//两种定义函数
var f2 = (a:Int) => a*10
val test3 = add3(f1, 2)
println(test3)
}
}
可变参数,java里面的可变参数
public class JavaDemo { public static void m1(String name, String ...arg) { } public static void main(String[] args) { m1("xx", "x", "b", "c"); } }
package test object learn1 { def add(ints: Int*):Int={//在参数类型后面加一个*就可以了,但只能放到最后 var sum = 0; for(v <- ints){ sum += v } sum } def make(test: Any*):Unit={//如果不知道要穿什么类型的参数,可以写成Any* } def main(args: Array[String]): Unit = { println(add(1,2,3,4,5)) println(add(1,2,3)) } }
方法定义的时候可以定义默认值
object learn1 { def add(a: Int = 1,b : Int = 2)={ a+b } def main(args: Array[String]): Unit = { println(add()) println(add(7,8)) println(add(9)) println(b=9) } }
object learn1 { //高阶函数,就是将其他函数作为参数或者结果的函数 //参数是一个函数,一个v,返回值也是个函数 def apply(f: Int=>String, v: Int) = f(v) def layout(x: Int) = "这个数是"+x.toString def main(args: Array[String]): Unit = { println(apply(layout, 10)) } }
被包在花括号内没有 match 的一组 case 语句是一个偏函数,它是 PartialFunction[A, B]的一个 实例,A 代表参数类型,B 代表返回类型,常用作输入模式匹配。
package day02 object ScalaPartialFunction { def func(str: String) : Int = { if(str.equals("a")) 97 else 0 } /** * 偏函数:PartialFunction[参数类型,返回值类型] */ def func1: PartialFunction[String, Int] = { case "a" => 97 case _ => 0 //补一个任意型的 } def f1: PartialFunction[Any, Int] = { case i: Int => i * 10 } def main(args: Array[String]): Unit = { println(func("a")) println(func1("a")) val arr = Array[Any](1,2,4, "你大爷的") val arr1 = Array[Int](1,2,4) val collect = arr.collect(f1) arr1.map((x:Int)=>x*10) //都会把里面的值乘以10 arr1.map(x=>x*10) arr1.map(_*10) arr.map {case x: Int => x*10}//这样就会把它转换成一个偏函数 println(collect.toBuffer) } }
数组的使用,以及常用方法
package day02 object ArrayOpt { def main(args: Array[String]): Unit = { val test = Array(1,2,3,4,5,"xxx") val arr = Array[Int](1,3,5,8,9) // map 映射,把arr里面的每个数据当参数传进去 val fx = (x: Int) => x * 10 // arr 见过map映射操作之后会返回一个新的数组,意思是一一对应 val r1 = arr.map(fx) //三种简化的方式 arr.map((x: Int) => x * 10) arr.map(x => x * 10) arr.map(_ * 10) // flatten 扁平化操作 //意思可以理解为把多个Array合成了一个Array(不去重) val arr1: Array[String] = Array("hello hello tom", "hello jerry") // Array(Array("hello","hello","tom"), Array("hello", "jerry")) //这样切分后,每一个字符串都切分成了一个Array,现在r2里面是多个Array val r2: Array[Array[String]] = arr1.map(_.split(" ")) // Array("hello","hello","tom", "hello", "jerry") 扁平化操作 r2.flatten // flatMap = map -> flatten(这个等于把map,flatten两个方法一起做了) arr1.flatMap(_.split(" ")) //foreach,循环遍历,里面需要传一个函数 arr1.flatMap(_.split(" ")).foreach(println) // 求每个单词出现的数量 word count //Array("hello","hello","tom", "hello", "jerry") val r3 = arr1.flatMap(x =>x.split(" ")) //groupBy 按照什么方法分组,里面传的是一个函数 // Map("hello" -> Array("hello", hello, hello), tom -> Array("tom") .groupBy(x => x) //取出上面分组后的value的长度,并转换成list,并按照length排序,map是没有排序方法的 //.map(x => x._2.length) //按照降序就加个-,正序就sortBy(x = > x._2) .mapValues(x => x.length).toList.sortBy(x => - x._2) println(r3) } }
然后一个比较详细的Wordcount
object WordCount { def main(args: Array[String]): Unit = { val words: Array[String] = Array("hello tom hello jim", "hello hatano hello 菲菲") // words 数组中的每个元素进行切分 // Array(Array(hello,tom,hello,jim), Array(hello,hatano,hello,菲菲)) val wordSplit: Array[Array[String]] = words.map((x: String) => x.split(" ")) // 将数组中的Array扁平化 // Array(hello,tom,hello,jim, hello,hatano,hello,菲菲) val fltWords: Array[String] = wordSplit.flatten // hello -> Array(hello, hello, hello, hello) val mapWords: Map[String, Array[String]] = fltWords.groupBy((wd: String) => wd) // (hello, 4), (tom, 1)。。。。 val wrdResult: Map[String, Int] = mapWords.map(wdKV => (wdKV._1, wdKV._2.length)) // Map不支持排序,需要将map转换成List, 调用sortBy方法按照单词数量降序排序 val sortResult: List[(String, Int)] = wrdResult.toList.sortBy(t => - t._2) sortResult.foreach(t => println(t)) } }
元组的使用