1.创建表 Staff
CREATE TABLE [dbo].[Staff]( [ID] [int] IDENTITY(1,1) NOT NULL, [Name] [varchar](50) NULL, [Sex] [varchar](50) NULL, [Department] [varchar](50) NULL, [Money] [int] NULL, [CreateDate] [datetime] NULL ) ON [PRIMARY] GO
2.为Staff表填充数据
INSERT INTO [dbo].[Staff]([Name],[Sex],[Department],[Money],[CreateDate]) SELECT 'Name1','男','技术部',3000,'2011-11-12' UNION ALL SELECT 'Name2','男','工程部',4000,'2013-11-12' UNION ALL SELECT 'Name3','女','工程部',3000,'2013-11-12' UNION ALL SELECT 'Name4','女','技术部',5000,'2012-11-12' UNION ALL SELECT 'Name5','女','技术部',6000,'2011-11-12' UNION ALL SELECT 'Name6','女','技术部',4000,'2013-11-12' UNION ALL SELECT 'Name7','女','技术部',5000,'2012-11-12' UNION ALL SELECT 'Name8','男','工程部',3000,'2012-11-12' UNION ALL SELECT 'Name9','男','工程部',6000,'2011-11-12' UNION ALL SELECT 'Name10','男','工程部',3000,'2011-11-12' UNION ALL SELECT 'Name11','男','技术部',3000,'2011-11-12'
GROUP BY 分组查询, 一般和聚合函数配合使用
SELECT [DEPARTMENT],SEX, COUNT(1) FROM DBO.[STAFF] GROUP BY SEX, [DEPARTMENT]
该段SQL是用于查询 某个部门下的男女员工数量 其数据结果如下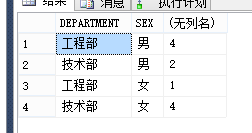

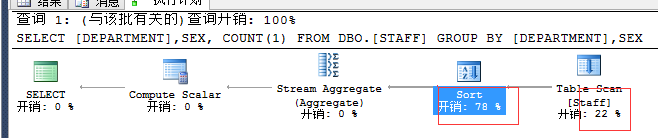
开销比较大
GROUPING SETS
使用 GROUPING SETS 的 GROUP BY 子句可以生成一个等效于由多个简单 GROUP BY 子句的 UNION ALL 生成的结果集,并且其效率比 GROUP BY 要高,SQL Server 2008引入。
1.使用GROUP BY 子句的 UNION ALL 来统计 Staff 表中的性别、部门、薪资、入职年份
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT N'总人数' ,'',COUNT(0) FROM [DBO].[STAFF] UNION ALL SELECT N'按性别划分', SEX,COUNT(0) FROM [DBO].[STAFF] GROUP BY SEX UNION ALL SELECT N'按部门统计',[DEPARTMENT],COUNT(0) FROM [DBO].[STAFF] GROUP BY [DEPARTMENT] UNION ALL SELECT N'按薪资统计',CONVERT(VARCHAR(10),[MONEY]),COUNT(0) FROM [DBO].[STAFF] GROUP BY [MONEY] UNION ALL SELECT N'按入职年份',CONVERT(VARCHAR(10),YEAR([CREATEDATE])),COUNT(0) FROM [DBO].[STAFF] GROUP BY YEAR([CREATEDATE])
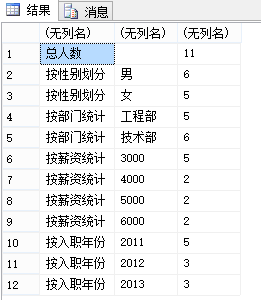


2.换成GROUPING SETS的写法
SET STATISTICS IO ON SET STATISTICS TIME ON GO SELECT (CASE WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=15 THEN N'总人数' WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=7 THEN N'按性别划分' WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=11 THEN N'按部门统计' WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=13 THEN N'按薪资统计' WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=14 THEN N'按入职年份' END ), (CASE WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=15 THEN '' WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=7 THEN SEX WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=11 THEN [DEPARTMENT] WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=13 THEN CONVERT(VARCHAR(10),[MONEY]) WHEN GROUPING_ID(SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]))=14 THEN CONVERT(VARCHAR(10),YEAR([CREATEDATE])) END ) , COUNT(1) FROM DBO.[STAFF] GROUP BY GROUPING SETS (SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]),())
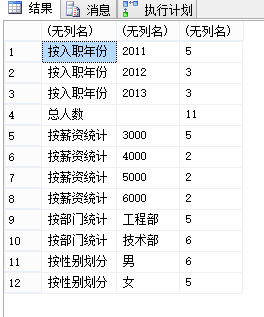

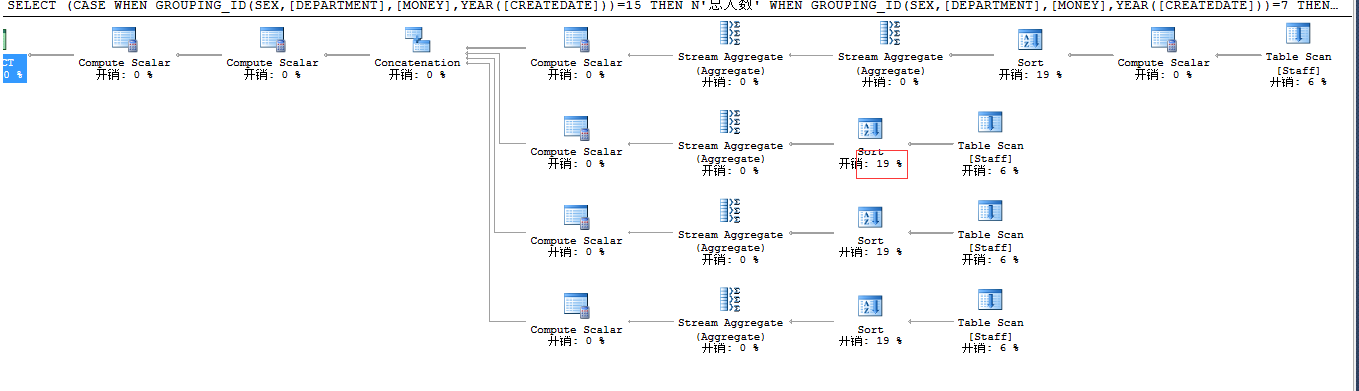
从上述结果中可以看出,采用UNION ALL 是多次扫描表,并将扫描后的查询结果进行组合操作,会增加IO开销,减少CPU和内存开销。
采用GROUPING SETS 是一次性读取所有数据,并在内存中进行聚合操作生成结果,减少IO开销,对CPU和内存消耗增加。但GROUPING SETS 在多列分组时,其性能会比group by高。
这里扫描四次是因为我 GROUP BY GROUPING SETS (SEX,[DEPARTMENT],[MONEY],YEAR([CREATEDATE]),()) 了四列
ROLLUP与CUBE
ROLLUP与CUBE 按一定的规则产生多种分组,然后按各种分组统计数据
ROLLUP与CUBE 区别:
CUBE 会对所有的分组字段进行统计,然后合计。
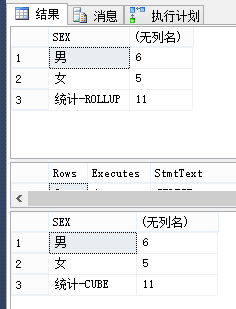
SELECT CASE WHEN (GROUPING(SEX) = 1) THEN '统计-ROLLUP' ELSE ISNULL(SEX, 'UNKNOWN') END AS SEX , COUNT(0) FROM DBO.[STAFF] GROUP BY SEX WITH ROLLUP SELECT CASE WHEN (GROUPING(SEX) = 1) THEN '统计-CUBE' ELSE ISNULL(SEX, 'UNKNOWN') END AS SEX , COUNT(0) FROM DBO.[STAFF] GROUP BY SEX WITH CUBE
SELECT CASE WHEN (GROUPING(SEX) = 1) THEN '统计-ROLLUP' ELSE ISNULL(SEX, 'UNKNOWN') END AS SEX , CASE WHEN (GROUPING([DEPARTMENT]) = 1) THEN '统计-ROLLUP' ELSE ISNULL([DEPARTMENT], 'UNKNOWN') END AS [DEPARTMENT], COUNT(0) FROM DBO.[STAFF] GROUP BY SEX,[DEPARTMENT] WITH ROLLUP SELECT CASE WHEN (GROUPING(SEX) = 1) THEN '统计-CUBE' ELSE ISNULL(SEX, 'UNKNOWN') END AS SEX , CASE WHEN (GROUPING([DEPARTMENT]) = 1) THEN '统计-CUBE' ELSE ISNULL([DEPARTMENT], 'UNKNOWN') END AS [DEPARTMENT], COUNT(0) FROM DBO.[STAFF] GROUP BY SEX,[DEPARTMENT] WITH CUBE
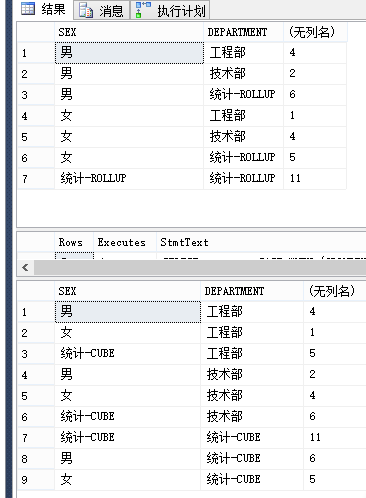
可以看出 使用 ROLLUP 会先统计分组下的,然后在对GROUP BY的第一列字段进行统计,最后计算总数,而 CUBE 则是先分组统计,然后统计GRUOP BY 的每个字段,最后进行汇总。
http://www.cnblogs.com/woxpp/p/4688715.html