- 接上篇 solr7.7.0 添加多个core
- 现在我们首先需要下载ik分词器文件:
分词器ikanalyzer-solr下载地址
-
链接:https://pan.baidu.com/s/1dsJKtonhD-0R1GzCe0hzaA
-
提取码:gaov
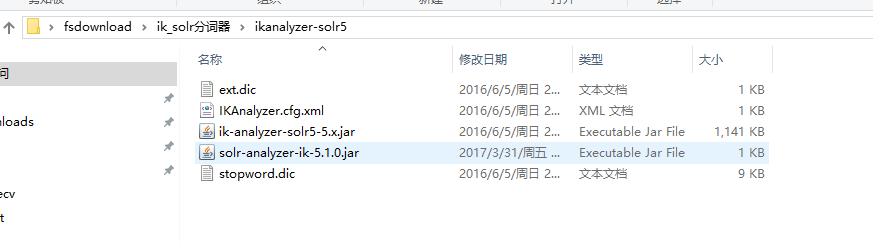
下载解压后如下目录结构:
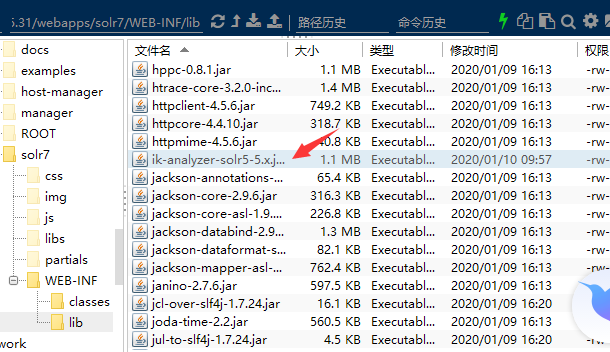
第一步:拷贝ik-analyzer-solr5-5.x.jar到/usr/local/solr/apache-tomcat-8.5.31/webapps/solr7/WEB-INF/lib目录下面
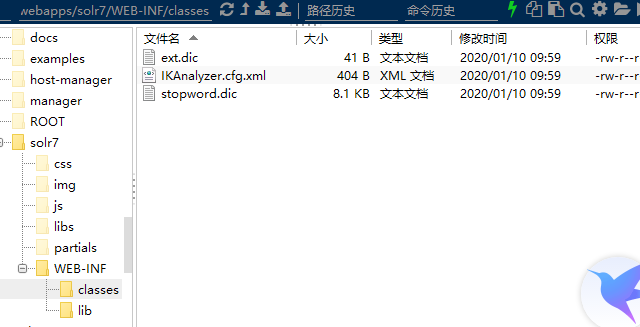
第二步:拷贝ext.dic ,stopword.dic,ikAnalyzer.cfg.xml到/usr/local/solr/apache-tomcat-8.5.31/webapps/solr7/WEB-INF/classes目录下面。
ikAnalyzer.cfg.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic;</entry> </properties>
ext.dic里面添加新词汇:比如“王者荣耀”这类的。
stopword.dic里面添加不需要分词的词语,比如 “的 了 个 你 我 他”
第三步:修改/usr/local/solr/solrhome/new_core/conf下面的managed-schema文件。
1.添加一个自定义的fieldType
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
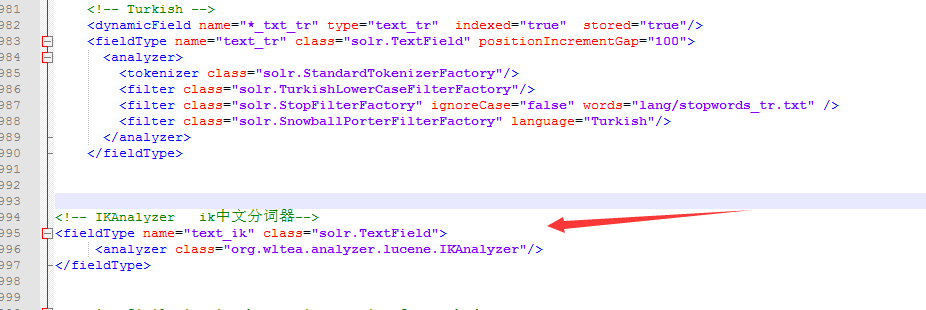
2.定义一个field,指定field的Type属性为text_ik
<!--IKAnalyzer Field--> <field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="true"/>
//<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
第四步:重启tomcat,让配置生效。
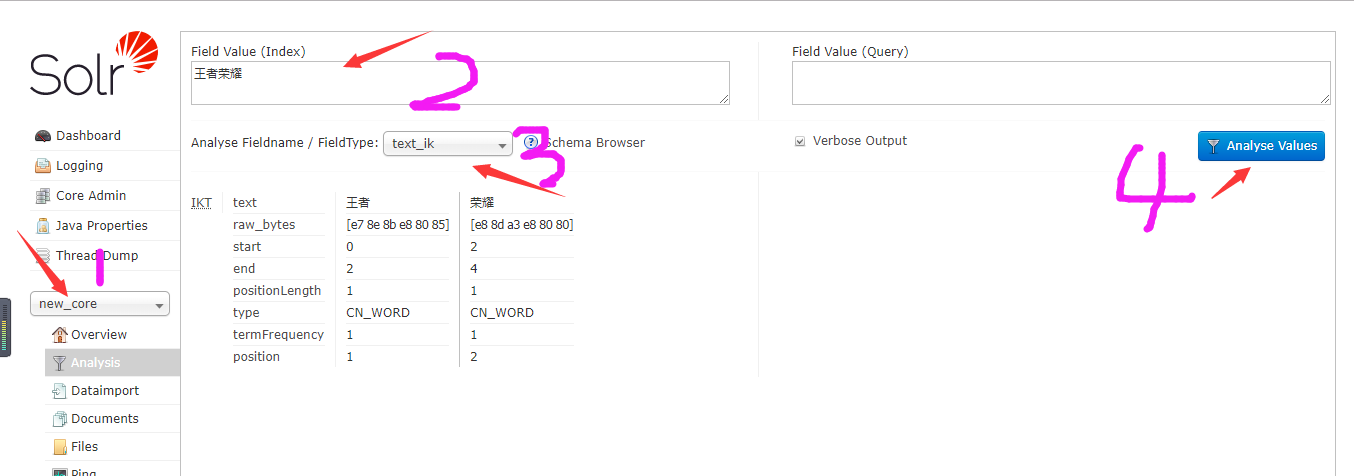
第五步:测试