前期准备
操作系统
hadoop目前对linux操作系统支持是最好的,可以部署2000个节点的服务器集群;在hadoop2.2以后,开始支持windows操作系统,但是兼容性没有linux好。因此,建议在MAC OS或者linux(CentOS或者Unbuntu)操作系统上安装。
安装java
hadoop2.6以前的版本,需要jdk1.6以上的版本;从hadoop2.7开始,则需要jdk1.7以上的版本。
我们可以使用jdk1.8,下载地址
对于linux操作系统用户
下载jdk-8u161-linux-x64.tar.gz压缩包文件,进行解压。
tar zxvf jdk-8u161-linux-x64.tar.gz -C /opt
接着就需要配置环境变量
编辑环境变量文件,添加如下代码
$ vim /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
对于MacOS操作系统用户
直接安装jdk-8u161-macosx-x64.dmg文件
接着就需要配置环境变量
编辑环境变量文件,添加如下代码
$ vim /etc/profile
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_161.jdk/Contents/Home
export PATH=$PATH:$JAVA_HOME/bin
检查java是否安装成功
$ java -version
输入上面的命令后,会输出java的基本信息
安装Hadoop
hadoop的安装方式有三种,本地模式、伪分布模式和完全分布模式。三种模式安装步骤有少许区别,本文介绍伪分布模式,也是开发环境最常用的方式。
通过官方网站下载hadoop版本,建议安装2.6版本,此版本相对更稳定,也是使用最为广泛的版本。
$ tar zxvf hadoop-2.6.0.tar.gz -C /opt
配置环境变量
$vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
hadoop配置文件
/opt/hadoop-2.6.0/hadoop-env.sh:
export JAVA_HOME=使用你上面配置的java_home路径
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
/opt/hadoop-2.6.0/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.0/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<!--垃圾保存一天-->
</property>
/opt/hadoop-2.6.0/hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
/opt/hadoop-2.6.0/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
/opt/hadoop-2.6.0/yarn-site.xml
<configuration>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:19888/jobhistory/job/</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 设置HDFS可以使用硬盘的百分比,对于硬盘小的人很重要 -->
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>99.0</value>
</property>
</configuration>
SSH免密码登录
检查一下,是否可以对本地进行免密码登录
$ ssh localhost
如果你在ssh本地时,需要输入密码,那么按以下步骤,配置免密码登录
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
格式化hdfs目录
$ hdfs namenode -format
该命令执行后,只会格式化你的/opt/hadoop-2.6.0/tmp目录
启动HDFS
$ start-dfs.sh
启动hdfs后,会生成日志文件,在$HADOOP_HOME/logs目录下
如果启动成功,你可以通过浏览器打开http://localhost:50070/,查看hdfs的相关信息
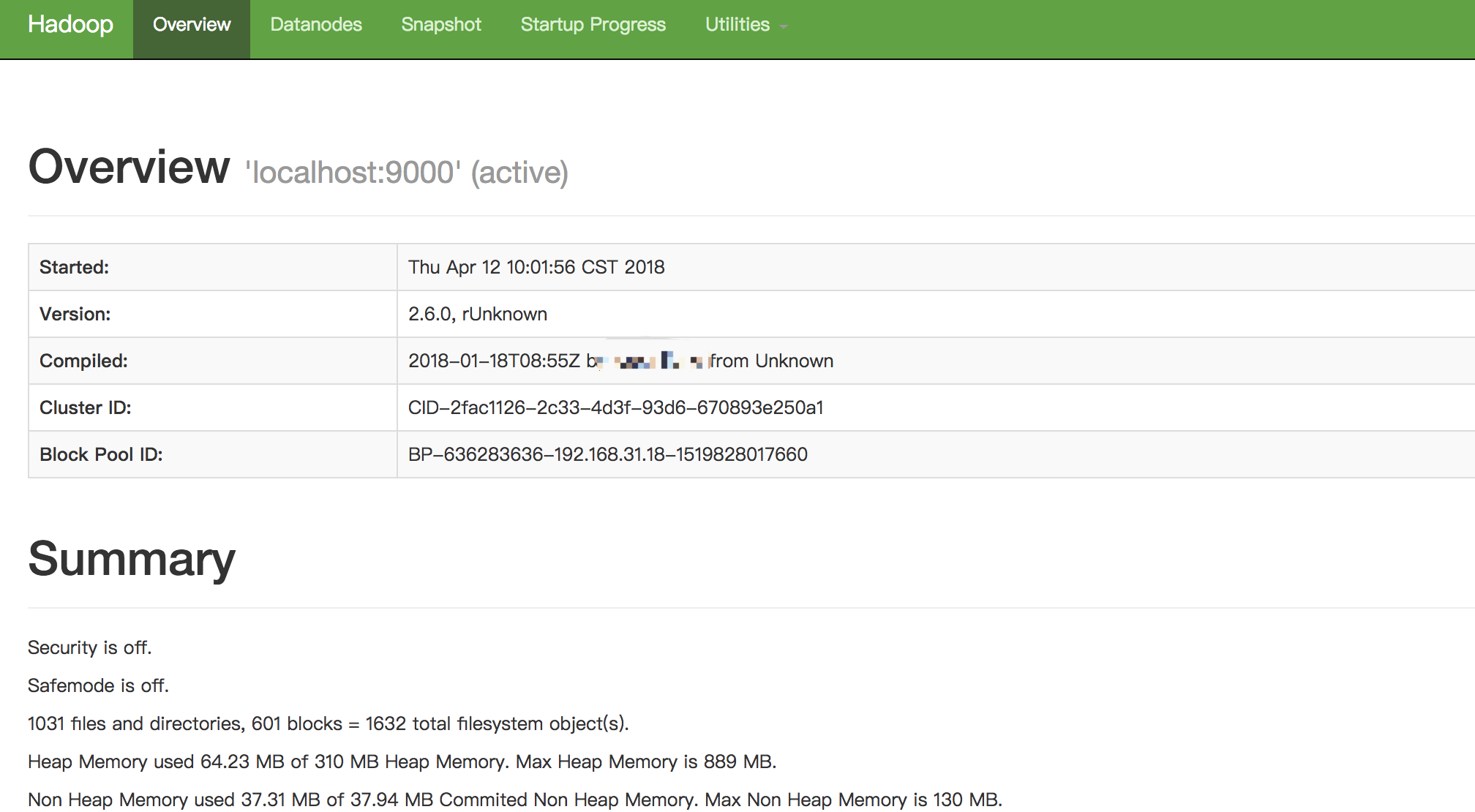
如果你想停止hdfs,请输入以下命令
$ stop-dfs.sh
启动yarn
$ start-yarn.sh
启动yarn后,会生成日志文件,在$HADOOP_HOME/logs目录下
如果启动成功,你可以通过浏览器打开http://localhost:8088/,查看yarn的相关信息
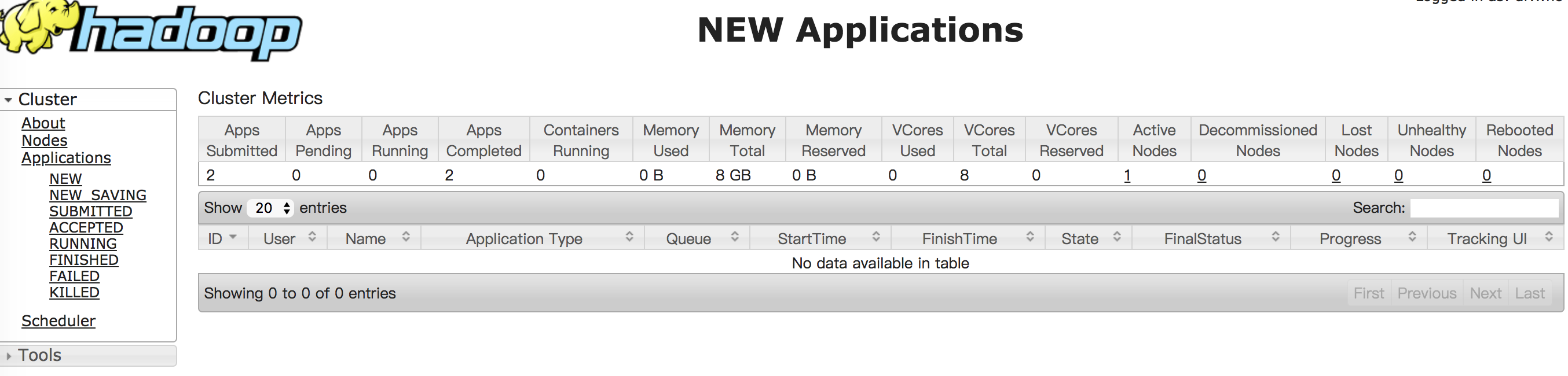
如果你想停止yarn,请输入以下命令
$ stop-yarn.sh
启动JobHistory
$ mr-jobhistory-daemon.sh start historyserver
启动JobHistory后,会生成日志文件,在$HADOOP_HOME/logs目录下
如果启动成功,你可以通过浏览器打开http://localhost:19888/,查看jobhistory的相关信息
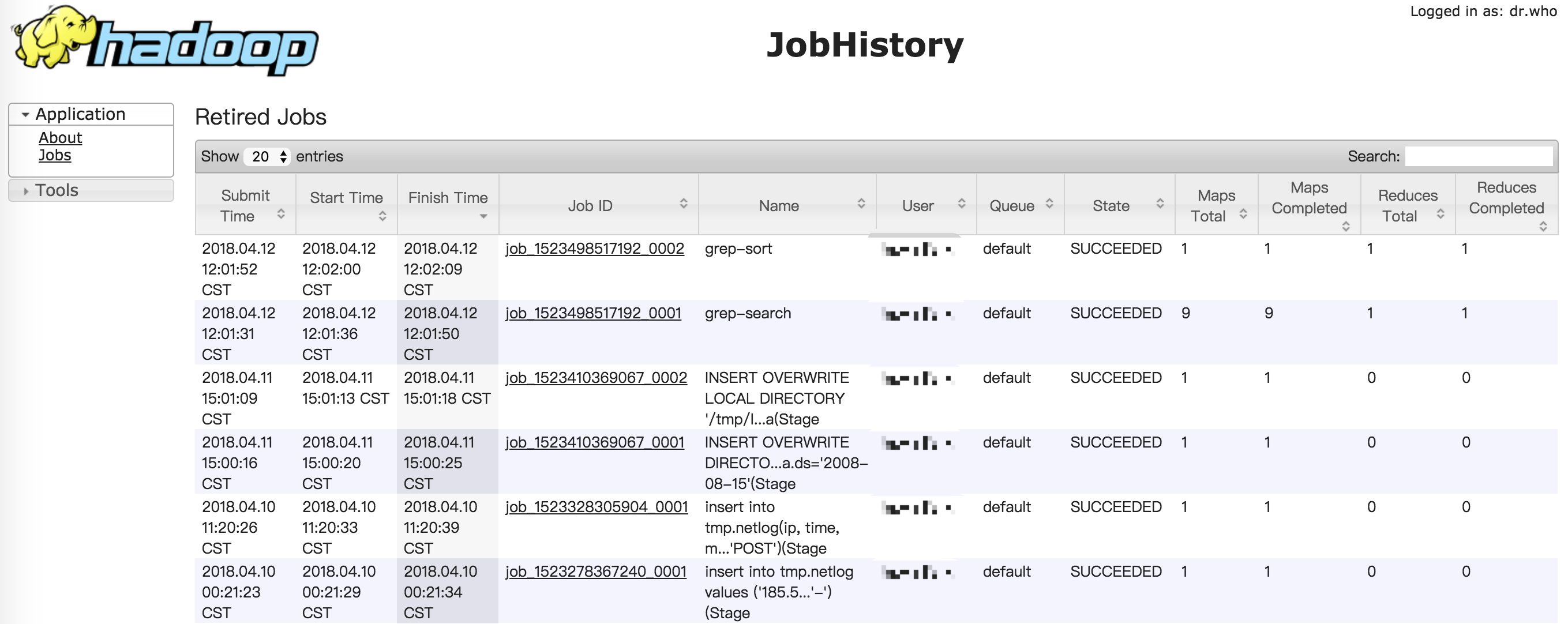
如果你想停止JobHistory,请输入以下命令
$ mr-jobhistory-daemon.sh stop historyserver
测试hadoop
成功安装完hadoop后,我们可以通过一些命令来感受一下hadoop
创建目录
$ hdfs dfs -mkdir /tmp/input
上传本地文件到hdfs $ hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml /tmp/input
使用MapReduce来计算我们刚才上传文件的以dfs开头的单词个数
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep /tmp/input /tmp/output 'dfs[a-z.]+'
查看MapReduce的结果
可以把hdfs上的结果文件下载到本地后查看
$ hdfs dfs -get /tmp/output output $ cat output/*
也可以通过hdfs查看命令直接查看
$ hdfs dfs -cat /tmp/output/part-r-00000
通过查询http://localhost:8088/,你会发现刚才执行MapReduce任务的历史记录
