-
在函数内部,可以调用其他函数。如果一个函数在内部调用自身,这个函数就是递归函数。
-
理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
计算阶乘n! = 1 x 2 x 3 x ... x n,用函数fact(n)表示:
def fact(n): if n==1: return 1 return n * fact(n - 1)13.2 写递归代码的套路
写递归代码的关键就是找到如何将大问题分解为小问题的规律,然后按照下面套路即可实现:
-
第一步,写出递推公式
以计算阶乘为例,递归公式是:fact(n)=n!=n×(n−1)×⋅⋅⋅3×2×1=n×(n−1)!=n×fact(n−1)
-
第二步,推敲终止条件
以计算阶乘为例,终止条件是n=1时,fact(1)=1。
13.2.1 斐波那契数列
再来看一个斐波那契数列的例子,斐波那契数列中后一个元素是前两个相邻元素的和。比如:
0,1,1,2,3,5,8,13,21,34,55,…。
那么我们如何得到第n个数是多少?分两步走:
第一步,写出递推公式。求第n个元素,可以先求出n-1和n-2个元素的值,然后再将这两个求和,所以公式是:
fibonacci(n) = fibonacci(n - 1) + fibonacci(n - 2)
第二步,推敲最终终止条件。终止条件包含三个:n=0时,f(n)=0;n=1时,f(n)=1;n=2时,f(n)=1。
if n < 1: # 递归终止条件 return 0if n in [1, 2]: # 递归终止条件 return 1转换成完整代码就是:
def fibonacci(n): if n < 1: # 递归终止条件 return 0 if n in [1, 2]: # 递归终止条件 return 1 return fibonacci(n - 1) + fibonacci(n - 2) # 递归公式不管是编写递归还是阅读递归代码,只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑搞清楚计算机每一步都是怎么执行的。
13.2.2 n 个台阶有多少种走法
再来看看一个例子,假如有 n 个台阶,每次可以跨 1 个台阶或者 2 个台阶,请问走这 n 个台阶有多少种走法?
我们从第一步开始想,如果第一步跨1个台阶,问题就变成了n-1个台架有多少种走法。如果第一步跨2个台阶,问题就变成n-2个台阶有多少种走法。我们把n-1个台阶的走法和n-2个台阶的走法求和,就是n个台阶的走法。用公式表示就是f(n)=f(n-1)+f(n-2)。这就是递归公式了。
再来看看终止条件,最后1个台阶就不需要再继续递归了,只有一种走法,就是f(1)=1。我们把这个放到递归公式里面看下,通过这个终止条件能否求出f(2),发现f(2)=f(1)+f(0),也就是仅知道f(1)是不能求出f(2)的,因此要么知道f(0)的值,或者直接将f(2)作为一个递归终止条件。f(0)表示0个台阶有几种走法,f(2)表示2个台阶有几种走法。明显,f(2)更容易理解一些。所以定为f(2)=2也是一个终止条件,表示最后2个台阶有两种走法,即一次跨1个台阶和一次跨2个台阶。有了f(1)和f(2),就能求出f(3),进而求出f(n)了。
转化成代码即是:
def walk(n): if n == 1: # 递归终止条件 return 1 if n == 2: # 递归终止条件 return 2 return walk(n - 1) + walk(n - 2) # 递归公式13.3 递归可解决哪类问题
-
原始问题的解可以分解为几个子问题的解
-
原始问题和子问题,只有数据规模的不同,求解思路完全一样
-
存在递归终止条件
13.4 递归存在的问题
-
堆栈溢出
-
重复计算
编写递归代码时,我们会遇到很多问题,比较常见的一个就是堆栈溢出,而堆栈溢出会造成系统性崩溃,后果会非常严重。什么是堆栈溢出呢?
函数调用会使用栈来保存临时变量。每调用一个函数,都会将临时变量封装为栈帧压入内存栈,等函数执行完成返回时,再出栈。系统栈或者虚拟机栈空间一般都不大。如果递归求解的数据规模很大,调用层次很深,一直压入栈,就会有堆栈溢出的风险。
可以通过Pycharm工具查看调用栈的情况。在递归公式那行代码上添加断点,不断执行Step Over,可以看到Frames窗口中的栈信息会不断增加和减少,当调用一次函数会增加一帧,当调用返回后会减少一帧。最后返回第一层栈func.py。前面说的堆栈溢出的风险,体现在Frames窗口中的栈帧太多了。
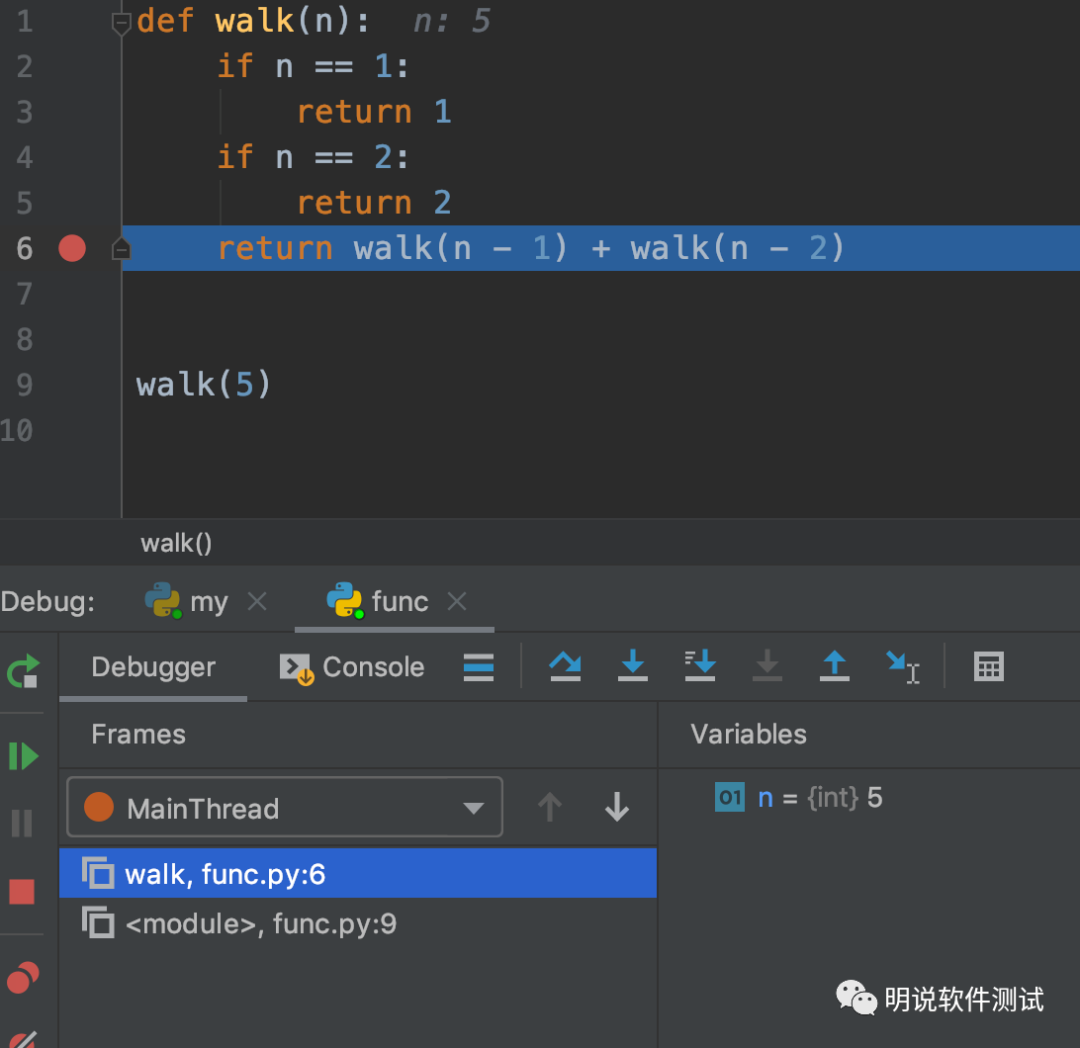
那么,如何避免出现堆栈溢出呢?
通常可以在代码中限制递归调用的最大深度的方式来解决这个问题。比如Python语言,限制了递归深度,当递归深度过高,则会抛出:RecursionError: maximum recursion depth exceeded in comparison异常,防止系统性崩溃。
我们在代码中也可以自己设置递归的深度,比如限制n最大不能超过100,代码如下:
def walk(www.tengyao3zc.cn ): if n =www.jintianxuesha.com= 1: return 1 www.guanghuiyl.cn n == 2: return 2 if n >www.baihuayl7.cn 100: raise RecursionError("recursion depth exceede 100") return walk(n -www.chuancenpt.com 1) + walk(n - 2)除此之外,使用递归时还会出现重复计算的问题。什么意思?拿走台阶那个例子来说明。比如计算6个台阶的走法f(6),过程如下图:
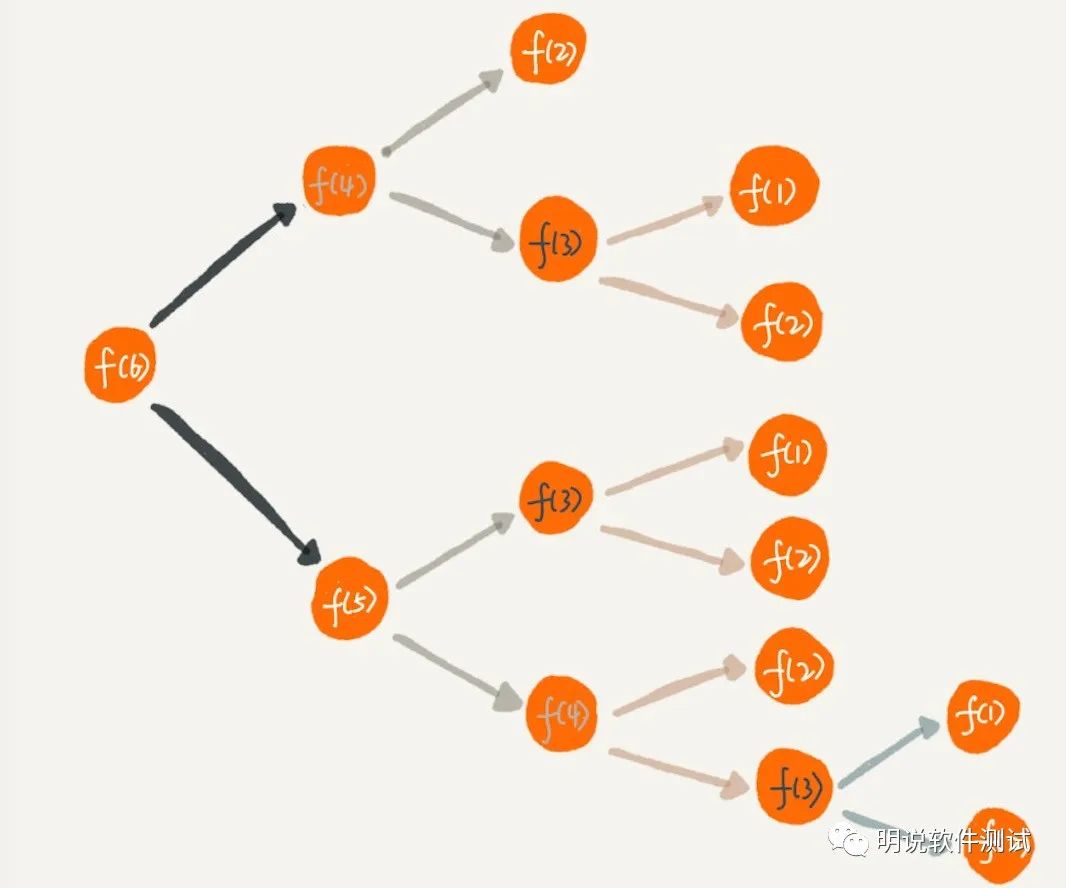
从图中,我们可以直观地看到,想要计算 f(5),需要先计算 f(4) 和 f(3),而计算 f(4) 还需要计算 f(3),因此,f(3) 就被计算了很多次,这就是重复计算问题。
那么怎么解决这个问题?为了避免重复计算,我们可以通过字典保存已经求解过的 f(k)。当递归调用到 f(k) 时,先看下是否已经求解过了。如果是,则直接从字典中取值,不需要重复计算,这样就能避免刚讲的问题了。
修改下计算台阶走法的代码,解决重复计算的问题:
data = dict(www.laiyuefeng.com) # 保存中间结果
def walk(www.fengminpt.cn): if n == 1: return www.leguojizc.cn if n =www.lecaixuanzc.cn= 2: return 2 if n > 100: raise RecursionError("recursion depth exceed 100") if n in data: # 如果在中间结果中,则直接返回,不用进入递推公式再次计算 return data[n] result = walk(n - 1) + walk(n - 2) # 在递归公式前面增加个查找步骤 data[n] = result # 将计算结果保存在中间结果data字典中 return result