之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时,由于SCRAPY解析数据的速率远远大于数据存储入数据库的速度,以至于造成数据阻塞,可以理解为数据高并发的问题。
现在我们可以使用TWISTED里的功能,话不多说先在PIPELINE里引入类对象,来执行异步操作:

引入adbapi对象
第一步:在SETTINGS.py里设置数据库连接配置,做成数据异步容器,书写格式如下图

第二步:自定义PIPRLINE,将配置数据的异步容器引入过来,注意语法引入的方法,将配置数据写入字典中,并以动态参数的方式作为连接池的参数
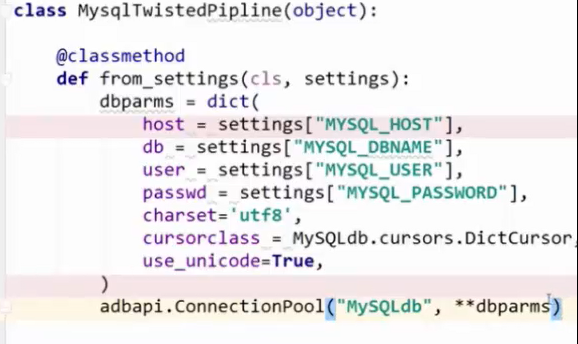
第三步:创建连接对象:
![]()
![]()
第四步:使用TWISTED将数据插入变为异步执行
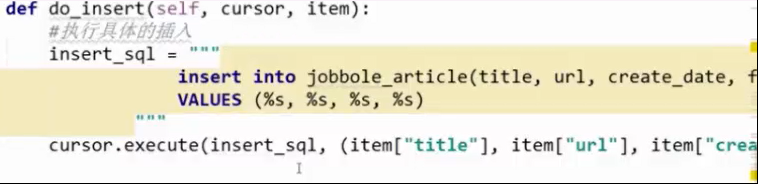
 第五步:执行插入:
第五步:执行插入:
 第六步:加入异步存储异常处理函数:
第六步:加入异步存储异常处理函数:

这种存储方式是极力推荐的一定是要会的 因为真正的爬虫工作数据量都特别大