前言
首先需要说明一下,与前两章的安装篇不太一样,这篇主要扫清一下这些插件/框架 等都是干什么用的,大多数都会用于服务端或监测工具或其他,作为新手建立一个大概的思想更好的了解自己的项目.废话不多说直接进入正题.
Dubbo
什么是Dubbo?
Dubbo是一个分布式服务框架,由阿里旗下团队开发出来,来源与核心业务抽取出来说白了就是根据业务流向取出来做成框架,能使前端更加快速和稳定的相应.
首先是服务治理部分:
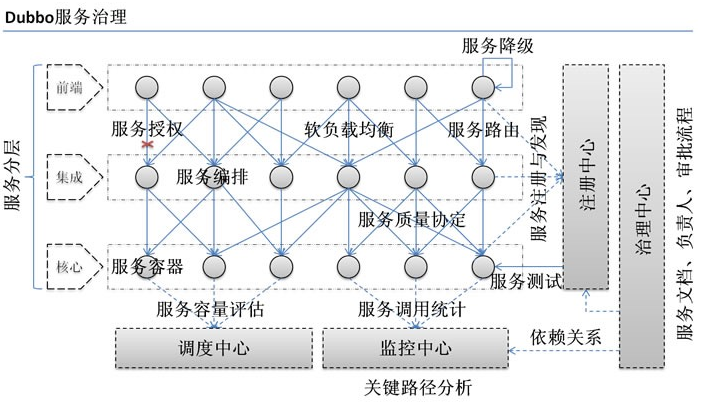
我说一下我个人理解,这个套系统的根源是线上的实际业务诞生儿来的,整体的架构思想如图我感觉特别凸显了MVC的原理不过深化了MVC思想,并不是简单的model层贯穿程序过程,这里指的是注册中心,治理中心,而调度中心和监控中心提供所有数据分析与治理中心行程依赖关系,为所有服务层出现的问题提供解决方案感觉上相当于一个有监管模式的model 如果有任何问题我可以从根源上改变model 来应付出现的错误.
视图层我觉得可以分为前端和集成,功能在于收集服务与编排服务,比如服务路由,软负载均衡 等等,当然他们不管处理这些服务,服务会被编排之后统一进入核心层面那才是真正的服务处理也就是MVC中的Controller层,这段完全是我自己的理解如有偏差还请指出.
为什么要使用Dubbo?
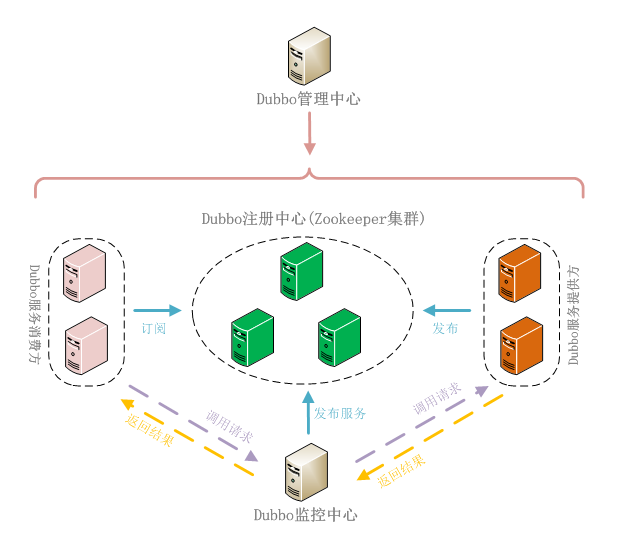
1.首先是刚刚提及的服务中心和注册中心,贯穿整个流程开发者只需要在服务中心注册服务,客户端去在服务中心查找该服务就可以了 而且服务中心使用zookeeper实现节点控制服务启动该服务时候会创建服务提供者节点信息,当然关闭时候会删除该信息.这样就方便客户端测试时候去主动选择服务提供者了,也就是直连服务提供者.
2.集群容错策略,我个人理解就是给报错划分等级制度,比如出现特别严重的错误需要马上修复的会立即报出,而部分错误并不会影响正常的线上业务所以优先级没有那么高,可以暂缓修改,还有如果一条服务出现问题,而有很多类似服务可以运行,那么会切换该服务,并且报错,这应该也算是一种集群容错策略,简单来说就是"不是不报,时候未到",这种集群容错对于程序耦合度要求很高.
3.负载均衡,就像上面所提到了如果一条服务压力过大而其他服务压力不是很大的时候就需要去均摊当前压力最大的服务这就是负载均衡机制,再搭配集群容错,划分错误等级 选择性报错 形成一条完整的自执行体.
4.多协议,相当于数据的多重入口 除了dubbo ,hessian,rmi 等等 根据需求选择合适的数据协议进行粒化分类
这里就不具体举例子如何实现的了,才疏学浅 只能理解到这些了,过一段时间使用熟练了再来分享以dubbo框架实现的工程
Zookeeper
什么是Zookeeper?
ZooKeeper是一个开源的分布式服务框架,它是Apache Hadoop项目的一个子项目,主要用来解决分布式应用场景中存在的一些问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置管理等,它支持Standalone模式和分布式模式,在分布式模式下,能够为分布式应用提供高性能和可靠地协调服务,而且使用ZooKeeper可以大大简化分布式协调服务的实现,为开发分布式应用极大地降低了成本。
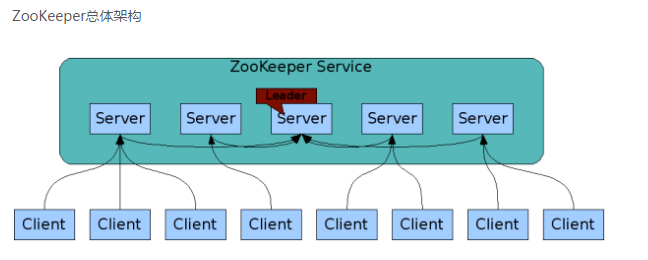
ZooKeeper工作原理
ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower。当客户端Client连接到ZooKeeper集群,并且执行写请求时,这些请求会被发送到Leader节点上,然后Leader节点上数据变更会同步到集群中其他的Follower节点.dubbo中集群管理部分就用到它,但是具体如何实现的暂未深层挖掘.
Redis
什么是redis?
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
在dubbo框架中分布式服务会用到redis,在集群容错方案中各个节点的配置信息会储存在redis中(这也许就是服务提供者发布之后,服务使用者可以查询到服务信息,单服务提供者关闭服务之后随之该服务也会消失的原因? 个人理解)
Elastic-job
什么是Elastic-job?
elastic-job是当当开发的基于qutarz以及zookeeper封装的作业调度工具,主要有两个大框架,一个是elastic-job lite另外一个是elastic-job cloud,其中qutarz是一个开源的作业调度工具,zookeeper是分布式调度工具,这两者结合搭建了elastic-job-lite,这是一个无中心节点的调度,而elastic-job-cloud是一个有中心节点的分布式调度开源工具,只需要设置好机器以及分片,就可以自动的调度到对应的机器上运行,与lite的不同时cloud采用了mesos来进行分布式资源管理,简单的来说两者的不同是:同一个作业在两台机器上跑,lite需要手动在两台机器上跑,但是cloud只需要上传作业包,就可以自动的在两台机器上跑,因为lite不支持作业的调度,为无中心的。
Elastic-job有点优势
1. 分布式调度
2. 作业高可用
3. 最大限度利用资源
AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。
RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗.


MyCat发展到目前的版本,已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL、SQL Server、Oracle、DB2、PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在MyCat里,都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度.
对于数据库中间件了解比较匮乏,不过这里有两位大神的回答比较到位:
其一是参与mycat开发的大神: http://www.csdn.net/article/2015-07-16/2825228
其二对其设计初衷表示怀疑的大神:http://www.yougemysqldba.com/discuz/viewthread.php?tid=526&extra=page%3D1
看完这两部分大神的理解 根据自己做的业务在做斟酌~