说明:这是在面试中面试官出的题。虽然是常见的优化问题,但这种经验的确很有用。感慨之余,分享出来,以此共勉。
场景:现有List<PersonA>,List<PersonB>,PersonA 的属性是 String类型的身份证号,int型age;PersonB 的属性是 String类型的身份证号,int型sex;两个集合中的身份证号有相同的;
需求:查找身份证号相同的人的性别。
常见的思路是:
1 @Data 2 public class PersonA { 3 private String card; 4 private int age; 5 6 public PersonA(String card, int age) { 7 this.card = card; 8 this.age = age; 9 } 10 } 11 ---------------------------------------------- 12 @Data 13 public class PersonB { 14 private String card; 15 private int sex; 16 17 public PersonB(String card, int sex) { 18 this.card = card; 19 this.sex = sex; 20 } 21 }
public class TestForFor { private List<PersonA> pa; private List<PersonB> pb; @Before public void before(){ pa = new ArrayList<>(); for (int i = 0; i < 10000; i++) { pa.add(new PersonA(UUID.randomUUID().toString(),20)); } pa.add(new PersonA("abcd111",10)); pa.add(new PersonA("abcd112",10)); pa.add(new PersonA("abcd113",10)); pa.add(new PersonA("abcd114",10)); pa.add(new PersonA("abcd115",10)); pa.add(new PersonA("abcd116",10)); pb = new ArrayList<>(); for (int i = 0; i < 10000; i++) { pb.add(new PersonB(UUID.randomUUID().toString(),Math.random() >= 0.5 ? 1 : 0)); } pb.add(new PersonB("abcd111",1)); pb.add(new PersonB("abcd112",1)); pb.add(new PersonB("abcd113",1)); pb.add(new PersonB("abcd114",1)); pb.add(new PersonB("abcd115",1)); pb.add(new PersonB("abcd116",1)); } @Test public void testFor(){ out.println("start search"); for (PersonA a : pa) { for (PersonB b : pb) { if (a.getCard().equals(b.getCard())){ out.println(b.getSex()==1?"男":"女"); } } } } }
结果。。。花费三秒多的时间。这还只是一万条数据

现在换一种思路,直接贴代码
1 private List<PersonA> pa; 2 private List<PersonB> pb; 3 private Map<String,Object> map; 4 @Before 5 public void before(){ 6 out.println("start before"); 7 pa = new ArrayList<>(); 8 for (int i = 0; i < 10000; i++) { 9 pa.add(new PersonA(UUID.randomUUID().toString(),20)); 10 } 11 pa.add(new PersonA("abcd111",10)); 12 pa.add(new PersonA("abcd112",10)); 13 pa.add(new PersonA("abcd113",10)); 14 pa.add(new PersonA("abcd114",10)); 15 pa.add(new PersonA("abcd115",10)); 16 pa.add(new PersonA("abcd116",10)); 17 18 19 pb = new ArrayList<>(); 20 for (int i = 0; i < 10000; i++) { 21 pb.add(new PersonB(UUID.randomUUID().toString(),Math.random() >= 0.5 ? 1 : 0)); 22 } 23 pb.add(new PersonB("abcd111",1)); 24 pb.add(new PersonB("abcd112",1)); 25 pb.add(new PersonB("abcd113",1)); 26 pb.add(new PersonB("abcd114",1)); 27 pb.add(new PersonB("abcd115",1)); 28 pb.add(new PersonB("abcd116",1)); 29 map = new HashMap<>(); 30 for ( PersonB pbb : pb ) { 31 map.put(pbb.getCard(),pbb.getSex()); 32 } 33 } 34 @Test 35 public void testFor(){ 36 out.println("start search"); 37 for (PersonA a : pa) { 38 if (map.containsKey(a.getCard())){ 39 out.print(a.getAge()+" "); 40 out.println((int)map.get(a.getCard())==1?"男":"女"); 41 } 42 //out.println(map.get(a.getCard())==null?"空":map.get(a.getCard())); 43 //out.println((int)map.get(a.getCard())==1?"男":"女"); 44 } 45 }
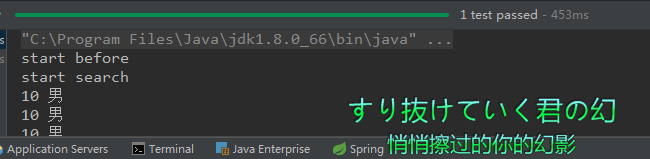
可以看出,查找的效率明显提升。
这里面的重点,第29行我用map重新填写了pb的数据[我的本地的sql坏了,所以用伪数据库的方式模仿,感兴趣也可以从数据库里试试],
为什么用map填完了后速度会这么快?
原因很简单。因为ArrayList的底层是数组实现的,若要查找必定是从索引0开始一个个的进行比对;而HashMap则不同,
HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度依然为O(1),因为最新的Entry会插入链表头部,仅需要简单改变引用链即可,而对于查找操作来讲,此时就需要遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
关于以上加粗内容取自博客
我在面试时只想到了hash,面试官提醒我用hashmap,恍然大悟。
时隔数月,回来归纳下这个问题。2018/9/13
其实这个问题可以抽象为:两个数组求交集,这里简要说下思路。
使用 treeset装载第一个数组,遍历第二个数组,if(!contains数组二中的值),add到一个新list中,最后这个list存的就是交集
原创分享,转载标注。