哇哦,光阴似箭!欢迎回到性能调优培训的最后一期。今天我会详细讲下SQL Server里的数据库维护,尤其是索引维护操作,还有如何进行数据库维护。
索引维护
作为一个DBA,数据库维护是你工作中非常重要的一部分,让数据库获得最佳性能。一个SQL Server数据库就像一辆车:它需要经常的检查来保证运行没有问题,副作用,且拥有最大可能的性能。SQL Server数据库最重要的部分是它的索引及其对应的统计信息对象。SQL Server运行一段时间后会有索引碎片,统计信息必须更新,这样的话查询优化器才可以为你生成“足够好”的执行计划。
我们来详细看下这2个东西。索引(聚集,非聚集)会产生碎片。索引意味着逻辑和物理排列顺序不再一致。如果你在传统旋转存储上存储你的数据库,索引碎片在你的存储子系统里带来随机I/O,与快速的循序I/O相比,它非常耗时。下图展示了索引碎片。
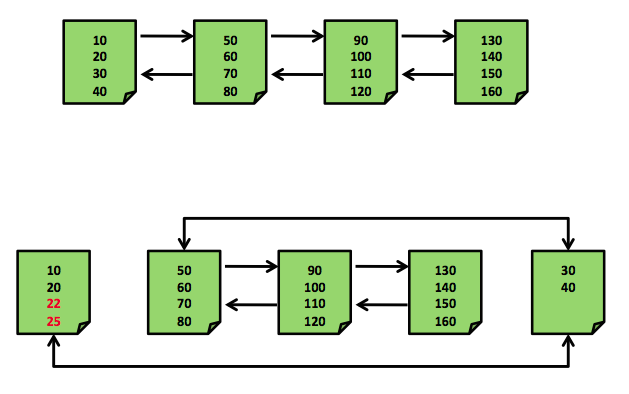
微软建议下列索引维护的最佳实践:
- 碎片低于10%:不进行维护
- 碎片在10-30%:进行索引重组操作
- 碎片大于30%:进行索引重建操作
除此之外,索引重组和索引重建操作应该只有在叶子层的页数至少有10000页才可以。如果你没有达到这个阈值,你不会看到随机I/O带来的副作用消失。索引重建(Index Rebuild)操作会完全重建你的索引。它是一个在事务日志里完全记录的“大”事务。在99%进度的时候回滚你的重建操作是个非常不好的想法,因为SQL Server需要把已做过的(有益的一面)全部重做一遍。因为你的回滚会花费很长时间。因为索引重建会重新生成你的整个索引,你的统计信息也会用全扫描更新。
另外,因为它是个大事务,如果这时你使用基于事务日志的HA技术就会有问题——例如数据库镜像或AlwaysOn可用组。SQL Server需要发送你的整个事务到镜像(或复制的地方)。那就意味着你的网络流量里有大量的事务日志记录。这对你的HA策略会有很大的副作用。
作为一个替代方法,索引重组(Index Reorganize)操作只处理你的索引的叶子层,重组叶子层的逻辑排序。因此,索引重组不会为你更新统计信息。索引重组只包含多个小的系统事务。因此它不会在事务日志上带来太大压力,因为虚拟日志文件可以为了更快的重用而被标记。索引重组操作对使用数据库镜像或AlwaysOn可用组都是有益的,因为使用索引重组操作你没有给网络流量里倒入大量的事务。
如何进行维护操作
我经常被问到的问题是在SQL Server里如何进行维护操作。我绝不,从未建议SQL Server提供的数据库维护计划(Database Maintenance Plans)。使用这些维护计划你使用大锤往SQL Server里砸:维护计划会重组/重建你的索引而不管它们的实际碎片!
我已经看过运行整晚在索引上进行索引重建的维护计划,尽管有些索引没有碎片。使用刚才提到的数据库维护计划,你就不能依据索引碎片情况进行维护。重组和重建索引是要根据索引碎片等级来的。因此我从不推荐这些数据库维护计划给任何人!
我推荐使用Ola Hallengren提供的SQL Server维护解决方案。这个解决方案包含一些列的存储过程,使用它们你可以继续宁数据库一致性检查,备份,还有索引维护操作。索引碎片等级就是你提供存储过程的参数值。我们来看看下列IndexOptimize存储过程的调用:
1 EXEC [master].[dbo].[IndexOptimize] 2 @Databases = 'AdventureWorks2012', 3 @FragmentationLow = 'INDEX_REBUILD_OFFLINE', 4 @FragmentationMedium = NULL, 5 @FragmentationHigh = NULL, 6 @FragmentationLevel1 = 10, 7 @FragmentationLevel2 = 30, 8 @PageCountLevel = 10000, 9 @SortInTempdb = 'N', 10 @MaxDOP = NULL, 11 @FillFactor = NULL, 12 @PadIndex = NULL, 13 @LOBCompaction = 'Y', 14 @UpdateStatistics = NULL, 15 @OnlyModifiedStatistics = 'N', 16 @StatisticsSample = NULL, 17 @StatisticsResample = 'N', 18 @PartitionLevel = 'N', 19 @TimeLimit = NULL, 20 @Indexes = NULL 21 @Delay = NULL, 22 @LogToTable = 'Y', 23 @Execute = 'Y' 24 GO
从代码里你可以看到,你可以指定不同的碎片等级作为参数(FragmentationLevel1, FragmentationLevel2)。最后对于这些碎片等级你指定你想要进行的索引操作(FragmentationLow, FragmentationMedium, FragmentationHigh)。在SQL Server里它是非常简单,却是非常强大的进行索引维护操作的方法。试下——用了包你忘不了!!
小结
在今天的性能调优培训里,我们谈了SQL Server里的数据库维护。你已经学到经常进行索引维护操作来摆脱索引碎片非常重要。因为索引碎片会在存储子系统引入随机I/O,它会降低磁盘读取操作。另外我想你展示通过使用Ola Hallengren提供的SQL Server维护解决方案进行非常高效的索引维护操作。
我希望和我一起的24个星期的性能调优培训很有收获,你已经学到了SQL Server里一些新的东西,尤其是性能调优和故障排除。欢迎大家给我留言,把你的想法告诉我!!再一次感谢您关注性能调优培训,感谢您和我一起度过这个24个星期的培训!! 谢谢您的一路陪伴!!!