大家好,欢迎回到性能调优培训。今天讨论SQL Server里的死锁(Deadlocking),第5个月的培训就结束了。当2个查询彼此等待,没有查询可以继续它的工作就会发生死锁。第一步我会概括介绍下SQL Server如何处理死锁。最后我会向你展示下SQL Server里一些特定死锁,还有你如何避免并解决它们。
死锁处理(Deadlock Hanging)
死锁的好处是SQL Server会自动检测并解决它们。为了解决死锁,SQL Server需要回滚最便宜的2个事务。在SQL Server上下文里,最便宜的事务是写入事务日志,字节数更少的事务。
SQL Server在后台进程里使用所谓的Deadlock Monitor来实现死锁检测。这个后台进程每5秒钟运行一次,为死锁检查当前的死锁情况。最坏的情况,因此死锁应该不会超过5秒钟。回滚的查询收到1205号错误。死锁的"好处"是你可以从那个错误情形里完全还原,而不需要用户互动。一个聪明的开发人员必须做下列事情来从死锁中恢复:
- 当异常抛出时,检查下1205错误号
- 暂停应用程序给其他查询一些时间来完成它的事务并释放它已获得的锁
- 重新提交被SQL Server回滚的查询
查询重新提交后,查询应该继续没有问题,因为其它阻塞的查询已经完成它的事务。当然,你应该保持再次死锁的跟踪,这样的话,你就不用反复重试你的事务。
你可以在不同方式里故障排除死锁。SQL Server Profiler提供你Deadlock Graph事件,死锁一旦发生就会检测到。如果你在SQL Server 2008及更高的版本,你也可以用扩展事件(Extended Events)来故障排除死锁情形。扩展时间提供你system_health事件会话,它更总自上次SQL Server重启后发生过的死锁。使用启用1222跟踪标志(trace flag),SQL Server会把死锁信息写入错误日志。
死锁类型
在SQL Server里可以发生多个类型的死锁。在这个部分我想详细谈下最常见的几个。
几乎在每个SQL Server里都会看到的一个经典死锁是著名的书签查找死锁(Bookmark Lookup Deadlock),当你同时对聚集和非聚集索引进行读写是会发生。这个是主要是因为不好的索引设计的死锁。在我的日常生活里,作为SQL Server的故障排除者,我可以说至少所有死锁的90%可以通过应用更好的索引设计到你工作中来避免。书签查找死锁可以通过第8周性能调优培训里介绍的提供覆盖非聚集索引来轻松剔除。
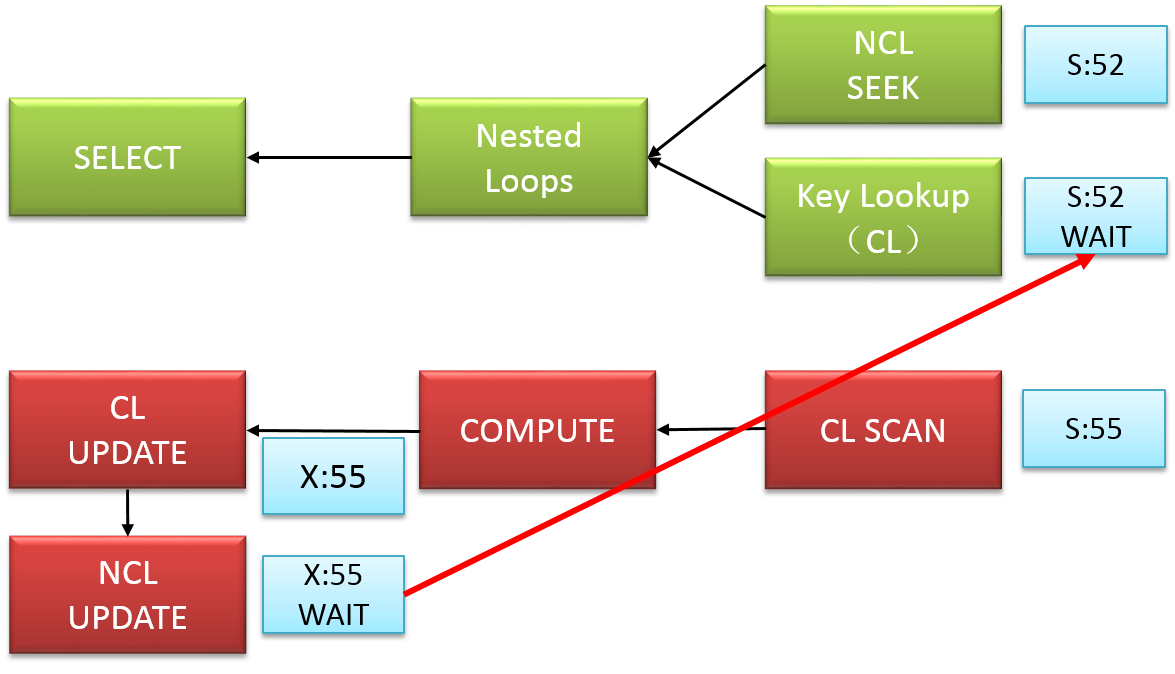
另一个常见的死锁是所谓的循环死锁(Cycle Deadlock),在你的各个查询以不同的顺序访问表里发生。为了避免那个特定死锁,你总要确保查询在同样的顺序访问表。另外在SQL Server里可以发生的“最好”死锁是所谓的内部并行死锁(Intra-Parallelism Deadlock),在并行运算符(Distribute Streams, Gather Streams, Repartition Streams)已经在各自线程间内部死锁。下图显示了一个典型的死锁图。
图片本身就是个很高雅的艺术品(pure art),因为你命中SQL Server里的1个BUG才发生。遗憾的是这样的BUG微软不会去修正,因为会引入回归(regressions)的可能。因此你要确保引起这个死锁的查询,在SQL Server里都是单线程运行的。你可以通过多个选项来获得执行计划的单线程执行:
- 在索引设计上做工作,这样的查询成本低于当前的并行开销阈值(默认5)
- 使用查询提示MAXDOP 1让SQL Server以单线程运行你有问题的查询
另一个死锁的特效疗法(miracle cure)是启用乐观并发控制(optimistic concurrency),尤其是读提交快照隔离(Read Committed Snapshot Isolation (RCSI)),这个2个星期前就已经讨论过,它对你的程序是完全透明的(completely transparent)。使用乐观并发控制,共享锁(S)就消失了,这意味这你可以剔除SQL Server里大量的典型死锁。
小结
死锁通过SQL Server回滚最便宜的事务来自动处理。但是你必须确保死锁尽可能小,因为每个回滚的事务都会负面影响你的终端用户。 死锁可以通过好的索引设计来避免,使用乐观并发控制对它们也可以是特效疗法。
下个星期,我们会开始性能调优培训的最后一个月,我们会讨论SQL Server里性能调优和故障排除的一切。请和我一起期待火力全开的最后一个月!